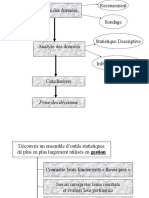
Vous aimerez peut-être aussi
- Fiche Data AnalysisDocument6 pagesFiche Data AnalysischarpentierPas encore d'évaluation
- Questions SubjectivesDocument8 pagesQuestions SubjectivesScribdTranslationsPas encore d'évaluation
- TD 3Document6 pagesTD 3Jingjing ShaPas encore d'évaluation
- Rapport DactivitéDocument63 pagesRapport DactivitéScribdTranslationsPas encore d'évaluation
- CH 9- droite de régression.docxDocument11 pagesCH 9- droite de régression.docxboudour.zitounPas encore d'évaluation
- Manuscrit StatDocument21 pagesManuscrit Statbouthainaamara6Pas encore d'évaluation
- Econométrie - Analyse DescriptiveDocument8 pagesEconométrie - Analyse DescriptiveGasy ManjabePas encore d'évaluation
- Add 1 2Document9 pagesAdd 1 2Mouad BouanzaPas encore d'évaluation
- Module Econometrie Chap1 2 2022Document18 pagesModule Econometrie Chap1 2 2022Abdou Dodo Bohari100% (1)
- Atelier 3Document12 pagesAtelier 3limaPas encore d'évaluation
- Chapitre I Anlyse en Composantes PrincipalesDocument20 pagesChapitre I Anlyse en Composantes PrincipalesAsma Satouri100% (1)
- Chapitre 0Document39 pagesChapitre 0Harold CarterPas encore d'évaluation
- Evaluation Des Modèles de MLDocument32 pagesEvaluation Des Modèles de MLNora HabrichPas encore d'évaluation
- Imad 2019Document18 pagesImad 2019gasparantonio99Pas encore d'évaluation
- Procedures Statistique 1 Variable 1Document156 pagesProcedures Statistique 1 Variable 1Salma MounirPas encore d'évaluation
- SPSS InterpretationDocument11 pagesSPSS InterpretationYao Kobena Arthur100% (1)
- Exam 2022-2023Document5 pagesExam 2022-2023ZAYNAB KANDROUCHPas encore d'évaluation
- ResuméDocument30 pagesResuméLalla Sanae JazouliPas encore d'évaluation
- Econometrie IntroDocument10 pagesEconometrie IntrodidjwPas encore d'évaluation
- Data ScienceDocument8 pagesData SciencemielledavPas encore d'évaluation
- EXAM CorrigeDocument2 pagesEXAM CorrigeAbdel MugiwaraPas encore d'évaluation
- Résumé ch1 Modèles de MesureDocument27 pagesRésumé ch1 Modèles de MesureMélissa FlorianPas encore d'évaluation
- QCM AddDocument1 pageQCM AddDantePas encore d'évaluation
- Psy1004 06Document13 pagesPsy1004 06Jean-paul AgbohPas encore d'évaluation
- Methodes ExploratoiresDocument34 pagesMethodes ExploratoiresfbdfnwdPas encore d'évaluation
- Analyse Des Donnees - CoursDocument61 pagesAnalyse Des Donnees - CoursAbdelwahab El Hadiri100% (1)
- Methodes ExploratoiresDocument34 pagesMethodes ExploratoiresFAOUZI NizarPas encore d'évaluation
- CM de ChloéDocument31 pagesCM de ChloéMohamed BennaniPas encore d'évaluation
- COURS DE MATHS 2ndeDocument48 pagesCOURS DE MATHS 2ndemat konanPas encore d'évaluation
- Trait Stat Avec SPSSDocument20 pagesTrait Stat Avec SPSSJoseph Blaise DONGMO LEKAGNEPas encore d'évaluation
- Analyse Statistique Des MesuresDocument11 pagesAnalyse Statistique Des Mesuressabri essaheli100% (1)
- Théorie Probabilité Et InférenceDocument42 pagesThéorie Probabilité Et InférenceMarie Emma NdeyePas encore d'évaluation
- Résumé S6 EDM NON FINALISE .Document6 pagesRésumé S6 EDM NON FINALISE .hajar rcmPas encore d'évaluation
- Chapitre I RLS .Document4 pagesChapitre I RLS .ABDELOUAHAB ETTAIKPas encore d'évaluation
- Cours EchantillonnageDocument90 pagesCours Echantillonnagefourat.zarkounaPas encore d'évaluation
- Fiche de TD de Theorie Des SondagesDocument4 pagesFiche de TD de Theorie Des SondagesWilfried DjekoréPas encore d'évaluation
- AcpDocument19 pagesAcpsancha22100% (1)
- Analyse Descriptive Des Donnees PDFDocument68 pagesAnalyse Descriptive Des Donnees PDFBlack AkatsukiPas encore d'évaluation
- StatisDocument8 pagesStatisWissal HammoudanePas encore d'évaluation
- Projet SPSS VFDocument8 pagesProjet SPSS VFEttalbiPas encore d'évaluation
- ACP Intelligence TD Solution Sommaire RDocument3 pagesACP Intelligence TD Solution Sommaire RTazi RedaPas encore d'évaluation
- Fiches Stats DescriptivesDocument3 pagesFiches Stats DescriptivesPierre MacarioPas encore d'évaluation
- Caractéristiques de La Forme Et de La ConcentrationDocument28 pagesCaractéristiques de La Forme Et de La Concentrationrania.benmoussa678Pas encore d'évaluation
- Support Cours Seco4 - 2022-2023-1Document30 pagesSupport Cours Seco4 - 2022-2023-1interactif tchatcheuPas encore d'évaluation
- AcpDocument10 pagesAcpThinhinane GuedriPas encore d'évaluation
- Analyse de DonnéesDocument12 pagesAnalyse de DonnéesRenaud AKATTIAPas encore d'évaluation
- Cours 1.02 - Qualité Des Estimateurs, Intervalles de Confiance Et Taille D'échantillonDocument10 pagesCours 1.02 - Qualité Des Estimateurs, Intervalles de Confiance Et Taille D'échantillonArthurDoesStats100% (1)
- DOE02.en.frDocument5 pagesDOE02.en.frchaib boudabPas encore d'évaluation
- PrésentationDocument27 pagesPrésentationOussama McPas encore d'évaluation
- M1 GRF Linear Model SPSSDocument103 pagesM1 GRF Linear Model SPSSsoufiane hilalPas encore d'évaluation
- Analyse de Base de DonnéesDocument17 pagesAnalyse de Base de Donnéeslhassanenna100% (1)
- CM Introduction Aux Statistiques 1701Document6 pagesCM Introduction Aux Statistiques 1701Morgane FaconPas encore d'évaluation
- Chapitre IDocument7 pagesChapitre Ichouroukbelkacemi236Pas encore d'évaluation
- Parametre Dispersion Boxplot Jan 2021Document13 pagesParametre Dispersion Boxplot Jan 2021Mamadou Diouck SowPas encore d'évaluation
- TADD Chapitre1 RégressionDocument15 pagesTADD Chapitre1 RégressionSaide MOHAMEDPas encore d'évaluation
- Psy1004 12Document12 pagesPsy1004 12Mustapha ImadPas encore d'évaluation
- Formulaire Psy1351 2011Document36 pagesFormulaire Psy1351 2011Amandine BiralPas encore d'évaluation
- Exemple Detude de CasDocument40 pagesExemple Detude de Casabel100% (1)
- Cours Chronique - Séance 3Document26 pagesCours Chronique - Séance 3abelPas encore d'évaluation
- Cours 4Document7 pagesCours 4abelPas encore d'évaluation
- T218 115a126ChantLigneBDocument12 pagesT218 115a126ChantLigneBabelPas encore d'évaluation
- Geologie DDocument1 pageGeologie DabelPas encore d'évaluation
- Normes Comptables InternationalesDocument10 pagesNormes Comptables InternationalesAbdou Diatta100% (1)
- TD N°3 S.AlimentairesDocument45 pagesTD N°3 S.AlimentairesSagacious IvejutenPas encore d'évaluation
- Corrigé Oulala A1 - Association FPADocument16 pagesCorrigé Oulala A1 - Association FPAespoirPas encore d'évaluation
- Presentation SoutenanceDocument25 pagesPresentation Soutenancemorris DUKULYPas encore d'évaluation
- Firestone (Kygo)Document3 pagesFirestone (Kygo)bengt_berglundPas encore d'évaluation
- Chap 1Document53 pagesChap 1hamid kamalPas encore d'évaluation
- Guide D Accompagnement - Le Petit PoucetDocument15 pagesGuide D Accompagnement - Le Petit Poucetآلبرت خلیلPas encore d'évaluation
- Série N°4 Gestion Comptable Des Stocks Bac 2022-2023Document4 pagesSérie N°4 Gestion Comptable Des Stocks Bac 2022-2023maaloulfarah8Pas encore d'évaluation
- EN 1090-2 01-07-2010 Cle783afcDocument20 pagesEN 1090-2 01-07-2010 Cle783afcfontainePas encore d'évaluation
- 07 Exos Prod Scalaire Geo RepereeDocument10 pages07 Exos Prod Scalaire Geo RepereeVitaliy BushuevPas encore d'évaluation
- Guide RDocument797 pagesGuide RKamel KamelPas encore d'évaluation
- 14 Systeme Éducatif Algérien PDFDocument19 pages14 Systeme Éducatif Algérien PDFZeyneb Enseignante0% (1)
- Rapport PFE VFDocument82 pagesRapport PFE VFrarzi12100% (1)
- Les Pratiques Funéraires Néolithiques Avant 3500 Av J-C en France Et Dans Les Régions LimitrophesDocument310 pagesLes Pratiques Funéraires Néolithiques Avant 3500 Av J-C en France Et Dans Les Régions LimitrophesGerardo Gómez RuizPas encore d'évaluation
- Statuts Renault Sa Ag 15.06.17Document20 pagesStatuts Renault Sa Ag 15.06.17aminata aboudramanePas encore d'évaluation
- Eolienne CorrigeDocument6 pagesEolienne CorrigeJad AyaPas encore d'évaluation
- Chapitre 2 Integration NumériqueDocument18 pagesChapitre 2 Integration NumériqueSarah BardiPas encore d'évaluation
- Liste Dépicerie VégétarienneDocument2 pagesListe Dépicerie Végétariennesandrinemode100% (1)
- Dell Emc Poweredge r650xs Technical Guide FRDocument61 pagesDell Emc Poweredge r650xs Technical Guide FRImen Makhlouf Ben AyedPas encore d'évaluation
- Assainissement Lit Filtrant (SOTRALENTZ) Fiche-UtilisateurPLASTEPURDocument64 pagesAssainissement Lit Filtrant (SOTRALENTZ) Fiche-UtilisateurPLASTEPURValcenyPas encore d'évaluation
- Exercice Compta KchiriDocument9 pagesExercice Compta KchiriTàHàà ZRPas encore d'évaluation
- Exposé Durée Du Travail KASSOU FinalDocument27 pagesExposé Durée Du Travail KASSOU FinalAya BaroudiPas encore d'évaluation
- Marketing Comportement Consommateur DistributionDocument83 pagesMarketing Comportement Consommateur Distributionnguyen100% (2)
- Liste Principale Des Candidats Admis Au Concours D'accès Au Master GMPMDocument1 pageListe Principale Des Candidats Admis Au Concours D'accès Au Master GMPMOutmane KachachPas encore d'évaluation
- Memoire FirewallDocument97 pagesMemoire FirewallLou LoulouPas encore d'évaluation
- 0 PDFDocument3 pages0 PDFДжалала ХілаліPas encore d'évaluation
- Lettre de Motivation NACHAT OssamaDocument1 pageLettre de Motivation NACHAT OssamaOssama NachatPas encore d'évaluation
- Cloud ComputingDocument25 pagesCloud ComputinghalimPas encore d'évaluation
- Bvah 52Document109 pagesBvah 52Harold de MoffartsPas encore d'évaluation
- CGV SANIFER-Juillet 2022Document5 pagesCGV SANIFER-Juillet 2022Cyanno Michael RANDRIAMIADANARISOAPas encore d'évaluation