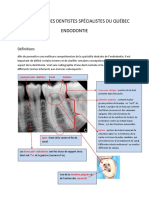
Vous aimerez peut-être aussi
- AnalysePredictive ArbreDécisionDocument35 pagesAnalysePredictive ArbreDécisionفركوس محمد العيدPas encore d'évaluation
- Sujet Mathematiques Brevet College Corrige Nouvelle Caledonie Decembre 2015Document7 pagesSujet Mathematiques Brevet College Corrige Nouvelle Caledonie Decembre 2015Mila SanoPas encore d'évaluation
- Arbre de Décision ET KNN PDFDocument47 pagesArbre de Décision ET KNN PDFMohamed SammariPas encore d'évaluation
- PCT UrbainDocument2 pagesPCT UrbainSanvi VictorPas encore d'évaluation
- Maths 4ème VOGT Controle Du 07 Oct 2023Document2 pagesMaths 4ème VOGT Controle Du 07 Oct 2023salimaimounatou0Pas encore d'évaluation
- HguhjikDocument6 pagesHguhjikalienorbouche221Pas encore d'évaluation
- Corrigé TD1 TGDocument4 pagesCorrigé TD1 TGferdaows laboudiPas encore d'évaluation
- Serie1 ABRDocument2 pagesSerie1 ABRImane ChatouiPas encore d'évaluation
- Unite 6 Et 7 WordDocument37 pagesUnite 6 Et 7 Wordcelinekhalil2003Pas encore d'évaluation
- Dnb21 Mathematique Serie Generale PDFDocument8 pagesDnb21 Mathematique Serie Generale PDFGuler SunaPas encore d'évaluation
- INF8111 - ExercicesDocument12 pagesINF8111 - Exercices4scdn50hwPas encore d'évaluation
- Sujet Maths 3eDocument1 pageSujet Maths 3eKelia QUADJOVIEPas encore d'évaluation
- Maths Prepa BEPC 2022Document39 pagesMaths Prepa BEPC 2022carter MaximePas encore d'évaluation
- Eva 7 CM1 Cercle PolygonesDocument3 pagesEva 7 CM1 Cercle Polygonesmavy inaoPas encore d'évaluation
- Sujet National, 2021, Exercice 3 - Assistance Scolaire Personnalisée Et Gratuite - ASPDocument3 pagesSujet National, 2021, Exercice 3 - Assistance Scolaire Personnalisée Et Gratuite - ASPRabeh Mohamed MehdiPas encore d'évaluation
- BR Math 2021 1 FRDocument4 pagesBR Math 2021 1 FRGrowtopiahelpingteamPas encore d'évaluation
- Devoir Commun 4eme 9Document6 pagesDevoir Commun 4eme 9Saikou Oumar BarryPas encore d'évaluation
- Géométrie Ceinture Verte Corrigé PDFDocument4 pagesGéométrie Ceinture Verte Corrigé PDFfrudellePas encore d'évaluation
- Brevet 2021 Mathematiques Sujet Serie GeneraleDocument8 pagesBrevet 2021 Mathematiques Sujet Serie GeneraleLETUDIANT67% (6)
- Corrigé TD1 TGDocument3 pagesCorrigé TD1 TGSiwar AbbesPas encore d'évaluation
- Olympiade Maths Belge de 2004 À 2023Document42 pagesOlympiade Maths Belge de 2004 À 2023Abdelilah SellamiPas encore d'évaluation
- Exam IA FIP2 Decembre 2020Document2 pagesExam IA FIP2 Decembre 2020nabPas encore d'évaluation
- Épreuve Mise en Ligne Par: Site de T Éléchargement Gratuit Des Épreuves Au CamerounDocument2 pagesÉpreuve Mise en Ligne Par: Site de T Éléchargement Gratuit Des Épreuves Au CamerounNgos JeanPas encore d'évaluation
- 1èrea Seq4Document2 pages1èrea Seq4Alice FokaPas encore d'évaluation
- 1 Construction D'arbre de Dã©cision 2 Arbre de Dã©cision Et Choix Des PDFDocument3 pages1 Construction D'arbre de Dã©cision 2 Arbre de Dã©cision Et Choix Des PDFRahim AbbaPas encore d'évaluation
- 961911explications Au Test de Logique PDFDocument10 pages961911explications Au Test de Logique PDFberhoofPas encore d'évaluation
- CompoMaths 1ertrim 2ndes LSLK22 - 23Document2 pagesCompoMaths 1ertrim 2ndes LSLK22 - 23Dawaïdom SAMIEPas encore d'évaluation
- TD1 Proba. S. BENHMIDA C. JALAL PDFDocument2 pagesTD1 Proba. S. BENHMIDA C. JALAL PDFElmehdi TalbiPas encore d'évaluation
- BrevetmathsgeneDocument7 pagesBrevetmathsgeneanbenyounes74Pas encore d'évaluation
- Pr. AIT CHEIKH - SEG - S2 - Examen Blanc de Probabilités - Ensembles 2,3 Et 4Document4 pagesPr. AIT CHEIKH - SEG - S2 - Examen Blanc de Probabilités - Ensembles 2,3 Et 4Sabrine BenouraidaPas encore d'évaluation
- Ex Amen FDA 2016Document7 pagesEx Amen FDA 2016slim yaichPas encore d'évaluation
- Jeux de Géométrie - Maguy LyDocument167 pagesJeux de Géométrie - Maguy LyRoger Dubois100% (1)
- Collection Seq4 - 3èmeDocument46 pagesCollection Seq4 - 3èmenana tony patrickPas encore d'évaluation
- Sétie de TD Numéro 1Document2 pagesSétie de TD Numéro 1talebPas encore d'évaluation
- Maths Seq 3 1ere D Lybil Dschang 1Document2 pagesMaths Seq 3 1ere D Lybil Dschang 1Ahmed SudaisPas encore d'évaluation
- Brevet Polynesie Sept 2020 DVDocument5 pagesBrevet Polynesie Sept 2020 DVAntonio DanielsPas encore d'évaluation
- Eval Cycle III BASE MathsDocument7 pagesEval Cycle III BASE Mathscad natPas encore d'évaluation
- Sujet Devoir Commun 2023Document5 pagesSujet Devoir Commun 2023danielzekaPas encore d'évaluation
- Développement en Fractions ContinuesDocument47 pagesDéveloppement en Fractions Continuescheria2010100% (1)
- Evaluation 2Document2 pagesEvaluation 2Yassine BarouniPas encore d'évaluation
- DM Maths Rentrée SecondeDocument4 pagesDM Maths Rentrée SecondeoranotnathananthonyyPas encore d'évaluation
- Chapitres 5 Et 6 Probabilités Et Dénombrements: Exercice 1Document21 pagesChapitres 5 Et 6 Probabilités Et Dénombrements: Exercice 1Foromo junior KovanahPas encore d'évaluation
- Devoir de Vacances Classe Eb6Document35 pagesDevoir de Vacances Classe Eb6api-318646823Pas encore d'évaluation
- Cahier Vacances Chenove 2007Document41 pagesCahier Vacances Chenove 2007aliasjanusPas encore d'évaluation
- Examen Aptitude Travail BureauDocument8 pagesExamen Aptitude Travail BureauGoldevie Genséric Nzitoukoulou KizaboulouPas encore d'évaluation
- Epreuve Zero Bacc C e 2021Document3 pagesEpreuve Zero Bacc C e 2021kofane yakanaPas encore d'évaluation
- Test de LogiqueDocument50 pagesTest de LogiqueKala Mangoubi juniorPas encore d'évaluation
- Sujet Zero Ou Sujet 0 Epreuves Communes E3c Premiere Spe Maths Specialite Mathematiques Bac 2021Document6 pagesSujet Zero Ou Sujet 0 Epreuves Communes E3c Premiere Spe Maths Specialite Mathematiques Bac 2021Shanthini JekumarPas encore d'évaluation
- CorrigeDocument5 pagesCorrigeKouadioPas encore d'évaluation
- Sujet EC Avril 2022Document4 pagesSujet EC Avril 2022natalia.7Pas encore d'évaluation
- Iepr1011 Cours12Document26 pagesIepr1011 Cours12valentinPas encore d'évaluation
- BEPCN2018Document1 pageBEPCN2018Abderrahmane Bedy100% (1)
- Arbre de Défaillance TS01 TD N 4Document55 pagesArbre de Défaillance TS01 TD N 4SvnPas encore d'évaluation
- Devoir de Maths Epid 2021Document1 pageDevoir de Maths Epid 2021Ousmane TraorePas encore d'évaluation
- Padlet SEC1-25 Mai 2020Document6 pagesPadlet SEC1-25 Mai 2020nathanaelouedraogo55Pas encore d'évaluation
- Baccalaur at G N Ral 2022 - Math Matiques - Jour 2 114656Document7 pagesBaccalaur at G N Ral 2022 - Math Matiques - Jour 2 114656arieldecauchy9Pas encore d'évaluation
- Devoir Maths 3college International FR 4Document12 pagesDevoir Maths 3college International FR 4Toni KrossPas encore d'évaluation
- Le cahier d'exercices : Tome 1 - Premiers pas: Outils visuels pour les musiciens, #2D'EverandLe cahier d'exercices : Tome 1 - Premiers pas: Outils visuels pour les musiciens, #2Pas encore d'évaluation
- Solfège Facile Pour Tous ou Comment Apprendre Le Solfège en 20 Jours ! - Leçon N°11: Solfège Facile Pour Tous, #11D'EverandSolfège Facile Pour Tous ou Comment Apprendre Le Solfège en 20 Jours ! - Leçon N°11: Solfège Facile Pour Tous, #11Pas encore d'évaluation
- Exam Modeles Pour Le Datamining 2015 2016 RattrapageDocument1 pageExam Modeles Pour Le Datamining 2015 2016 RattrapageilyesPas encore d'évaluation
- Exam Modeles Pour Le Datamining 2015 2016Document5 pagesExam Modeles Pour Le Datamining 2015 2016ilyesPas encore d'évaluation
- Exam Modeles Pour Le Datamining 2015 2016 RattrapageCorDocument5 pagesExam Modeles Pour Le Datamining 2015 2016 RattrapageCorilyesPas encore d'évaluation
- Exam Modeles Pour Le Datamining 2016 2017Document2 pagesExam Modeles Pour Le Datamining 2016 2017ilyesPas encore d'évaluation
- Exam Modeles Pour Le Datamining 2015 2016corDocument4 pagesExam Modeles Pour Le Datamining 2015 2016corilyesPas encore d'évaluation
- Tdmotifs1920 PDFDocument2 pagesTdmotifs1920 PDFilyesPas encore d'évaluation
- 1 Examen2011-2012 PDFDocument1 page1 Examen2011-2012 PDFilyesPas encore d'évaluation
- 2 Rattfda2011-2012 PDFDocument1 page2 Rattfda2011-2012 PDFilyesPas encore d'évaluation
- 4 Examenfda2014Document4 pages4 Examenfda2014ilyesPas encore d'évaluation
- 5 Examenfda2015Document5 pages5 Examenfda2015ilyesPas encore d'évaluation
- 2 Rattfda2011-2012Document1 page2 Rattfda2011-2012ilyesPas encore d'évaluation
- PolycopefdaDocument96 pagesPolycopefdailyesPas encore d'évaluation
- 1 Examen2011-2012Document1 page1 Examen2011-2012ilyesPas encore d'évaluation
- 12 Examenrattfda2018Document4 pages12 Examenrattfda2018ilyesPas encore d'évaluation
- 3 Examenfda2013 PDFDocument2 pages3 Examenfda2013 PDFilyes100% (1)
- 13 Examenfda 2019Document7 pages13 Examenfda 2019ilyesPas encore d'évaluation
- Tdad 1920Document1 pageTdad 1920ilyes0% (1)
- Tdmotifs 1920Document2 pagesTdmotifs 1920ilyes100% (1)
- Endo Revision PDFDocument13 pagesEndo Revision PDFMedecine Dentaire100% (2)
- SAAD 2019 ArchivageDocument224 pagesSAAD 2019 ArchivageCarlos Redondo BenitezPas encore d'évaluation
- A3 2 PDFDocument34 pagesA3 2 PDFLéopold SENEPas encore d'évaluation
- Moez El Kouni: ExperienceDocument1 pageMoez El Kouni: ExperienceMoezPas encore d'évaluation
- Format Label 113Document5 pagesFormat Label 113Marlisa IchaPas encore d'évaluation
- Histoire Et Géographie Sacrées Dans Le CoranDocument37 pagesHistoire Et Géographie Sacrées Dans Le CoranCatharsis HaddoukPas encore d'évaluation
- FoQual Rapport Incidents FRDocument40 pagesFoQual Rapport Incidents FRMarco SanPas encore d'évaluation
- Module 3 La Mise en Oeuvre La Résine Epoxy Clé en MainDocument19 pagesModule 3 La Mise en Oeuvre La Résine Epoxy Clé en Maintommy100% (1)
- Babas Savarins-1Document1 pageBabas Savarins-1Benjamin GevoldePas encore d'évaluation
- PHARMACO Respi. Médicaments de La TouxDocument40 pagesPHARMACO Respi. Médicaments de La TouxyvesPas encore d'évaluation
- Flyer Passerelle VF (18752)Document2 pagesFlyer Passerelle VF (18752)grosjeanblandinePas encore d'évaluation
- 1715944Document1 page1715944ADRIANNE BETTAPas encore d'évaluation
- Manuel MilitaireDocument204 pagesManuel MilitaireFRED100% (1)
- Droit Des Affaires 2019 - 2020Document104 pagesDroit Des Affaires 2019 - 2020YassminaPas encore d'évaluation
- Bourdieu Emprise JournalismeDocument4 pagesBourdieu Emprise JournalismebobyPas encore d'évaluation
- Série TD 5 Phys2 2019 2020+corrigéDocument5 pagesSérie TD 5 Phys2 2019 2020+corrigéamiranomi5Pas encore d'évaluation
- Pinpankôd Désigne Celle Des Jeunes Garçons Et Filles Dont L'âge VarieDocument20 pagesPinpankôd Désigne Celle Des Jeunes Garçons Et Filles Dont L'âge VarieNajimou Alade TidjaniPas encore d'évaluation
- 1710 PDF Du 30Document26 pages1710 PDF Du 30PDF JournalPas encore d'évaluation
- Atelier1 PowerQueryDocument2 pagesAtelier1 PowerQuerylouay bencheikhPas encore d'évaluation
- 27 Eme - Tob - 02-10-2021Document2 pages27 Eme - Tob - 02-10-2021Joyce DouanlaPas encore d'évaluation
- American Gods - Neil GaimanDocument254 pagesAmerican Gods - Neil GaimanmrabdoPas encore d'évaluation
- Construire en TerreDocument274 pagesConstruire en Terreridha1964100% (4)
- Formula D PDFDocument16 pagesFormula D PDFNour-Eddine BenkerroumPas encore d'évaluation
- ExamSys1 LMD 2010 2011 EpreuveCorDocument2 pagesExamSys1 LMD 2010 2011 EpreuveCorSira NdiayePas encore d'évaluation
- Algorithmes de Traitement Suggeres HTADocument3 pagesAlgorithmes de Traitement Suggeres HTAZiedBenSassiPas encore d'évaluation
- Compl Biologie Etudiant S-1Document43 pagesCompl Biologie Etudiant S-1aloys NdziePas encore d'évaluation
- Generateur High Tech Mig Mag Digiwave III Saf-Fro FRDocument16 pagesGenerateur High Tech Mig Mag Digiwave III Saf-Fro FROmar MaalejPas encore d'évaluation
- Ligne Directrice 2021 - DyslipidémieDocument1 pageLigne Directrice 2021 - Dyslipidémiesara harvey vachonPas encore d'évaluation
- Pyramide MaslowDocument3 pagesPyramide Maslowvibus2014Pas encore d'évaluation
- Brevet Sur Le Front Populaire Avec CorrectionDocument2 pagesBrevet Sur Le Front Populaire Avec Correctiondouzi nourPas encore d'évaluation