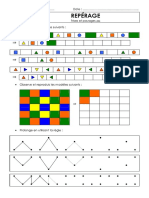
Vous aimerez peut-être aussi
- Frise 03Document1 pageFrise 03Oihana ReyesPas encore d'évaluation
- Frise 01Document1 pageFrise 01Oihana ReyesPas encore d'évaluation
- Évaluation Diagnostique 2aep 3Document4 pagesÉvaluation Diagnostique 2aep 3Abdel SlimaniPas encore d'évaluation
- RasterbationDocument12 pagesRasterbationJhanna Rheign SaragponPas encore d'évaluation
- Adm950 en Col62Document307 pagesAdm950 en Col62Ikarus DedaloPas encore d'évaluation
- Note 015.22 - 09.03.2022Document45 pagesNote 015.22 - 09.03.2022JALIL MARSPas encore d'évaluation
- Pleno Jurisdiccional Distrital de Los Juzgados de Paz Letrado de La Corte Superior de Justicia de LimaDocument42 pagesPleno Jurisdiccional Distrital de Los Juzgados de Paz Letrado de La Corte Superior de Justicia de LimabiosegurPas encore d'évaluation
- Dotted Arts Assignment 13 Sep 2022Document8 pagesDotted Arts Assignment 13 Sep 2022Ameen Design StudioPas encore d'évaluation
- THR12 1 EN Col95Document351 pagesTHR12 1 EN Col95Bhaskar BurraPas encore d'évaluation
- TADM10 1 EN Col72 PDFDocument525 pagesTADM10 1 EN Col72 PDFBruno LopesPas encore d'évaluation
- Theoi Sumbomoi Et Autels Multiples. Refl PDFDocument20 pagesTheoi Sumbomoi Et Autels Multiples. Refl PDFpatrserPas encore d'évaluation
- Offres D Emplois DGSIDocument41 pagesOffres D Emplois DGSIjody.eth.gonzalesPas encore d'évaluation
- MB-P1010132-MBot2 Getting Started Activities FRDocument114 pagesMB-P1010132-MBot2 Getting Started Activities FRSylvestre OlanloPas encore d'évaluation
- UntitledDocument54 pagesUntitledVentas VariasPas encore d'évaluation
- Clarinete - COPPELIADocument9 pagesClarinete - COPPELIAVicentePas encore d'évaluation
- Brochure LP EII 2023Document1 pageBrochure LP EII 2023zakariaPas encore d'évaluation
- APE - Formation - Focus Sur Le Nouveau Dispositif APEDocument91 pagesAPE - Formation - Focus Sur Le Nouveau Dispositif APEJérémy VaesPas encore d'évaluation
- (KT) Cosmetiquera..Paso A Paso PDFDocument25 pages(KT) Cosmetiquera..Paso A Paso PDFcindy hernandesPas encore d'évaluation
- Plaquette de Présentation Nutrizaza 1Document4 pagesPlaquette de Présentation Nutrizaza 1AlbPas encore d'évaluation
- AGB - Formulaire P - MoraleDocument7 pagesAGB - Formulaire P - MoraleSAMI ABDELLIOUIPas encore d'évaluation
- Smells Like Teen Spirit Nirvana VraieDocument1 pageSmells Like Teen Spirit Nirvana VraieHugo JolyPas encore d'évaluation
- Raspunsuri Rezidenriat 2021 Varianta ADocument1 pageRaspunsuri Rezidenriat 2021 Varianta AAlex PanduruPas encore d'évaluation
- AvengersDocument2 pagesAvengersfernando gonzalezPas encore d'évaluation
- Mademoiselle K - Jouer Dehors - Guitare Électrique 1Document3 pagesMademoiselle K - Jouer Dehors - Guitare Électrique 1Victor AubertPas encore d'évaluation
- V4814N 2 3N3L1515 M1C803CN0M1C0 WWW - Economiadigitals.blogspot - PeDocument654 pagesV4814N 2 3N3L1515 M1C803CN0M1C0 WWW - Economiadigitals.blogspot - PeC-bazh U AlboPas encore d'évaluation
- Ballscrew 3020-3040 CNC Router GUIDEDocument18 pagesBallscrew 3020-3040 CNC Router GUIDEHector Fabio Vega EspinelPas encore d'évaluation
- Ballscrew 3020-3040 CNC Router GUIDEDocument18 pagesBallscrew 3020-3040 CNC Router GUIDEvituchogoodPas encore d'évaluation
- Ballscrew 3020-3040 CNC Router GUIDEDocument18 pagesBallscrew 3020-3040 CNC Router GUIDEEdison MarquesPas encore d'évaluation
- Catalogue Peugeot 1985Document20 pagesCatalogue Peugeot 1985Henrique CorreiaPas encore d'évaluation
- Bioeconomía AcuícolaDocument5 pagesBioeconomía AcuícolaANDREA BOTELLO NAVARRETEPas encore d'évaluation
- SAi Production Suite 21 ReadmeDocument17 pagesSAi Production Suite 21 ReadmetroladeiradorPas encore d'évaluation
- Bebe Mange SeulDocument118 pagesBebe Mange SeulNoemie PerraultPas encore d'évaluation
- CV Dexter GarbarzDocument4 pagesCV Dexter GarbarzDexter GarbarzPas encore d'évaluation
- Rock of The Ages - CRC - Full ScoreDocument3 pagesRock of The Ages - CRC - Full ScoreTravis Mc DowallPas encore d'évaluation
- Hangin' AroundDocument2 pagesHangin' AroundvilamadridPas encore d'évaluation
- Jesusholy KeyboardDocument2 pagesJesusholy KeyboardHendry TambunanPas encore d'évaluation
- Le Coeur Des Gens Canon À 4 Voix MUSICAMOS AVANZADADocument5 pagesLe Coeur Des Gens Canon À 4 Voix MUSICAMOS AVANZADAXaloc Marí VivóPas encore d'évaluation
- M510188a Exorcist Construction DiagramDocument3 pagesM510188a Exorcist Construction DiagramMarkus HirviPas encore d'évaluation
- Hormigas 1-10Document11 pagesHormigas 1-10Angélica GonzálezPas encore d'évaluation
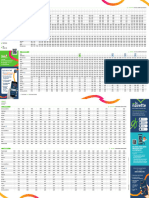
- E Transports Horaires 2023-24Document2 pagesE Transports Horaires 2023-24dpz5r7brwbPas encore d'évaluation
- ENEMY Arr. Moreno Tomás - Partitura + TABDocument3 pagesENEMY Arr. Moreno Tomás - Partitura + TABAlfonzo AlbaricoquePas encore d'évaluation
- ENEMY Arr. Moreno Tomás - Partitura + TABDocument3 pagesENEMY Arr. Moreno Tomás - Partitura + TABMariano Torres SilvaPas encore d'évaluation
- EscrituraDocument2 pagesEscrituracarigirivasPas encore d'évaluation
- Ikan Dan Buaya: KromongDocument4 pagesIkan Dan Buaya: KromongMuhamad FirdausPas encore d'évaluation
- 4 Simple Rhythm Exercises PDFDocument28 pages4 Simple Rhythm Exercises PDFShant KeuroghelianPas encore d'évaluation
- جذاذات الوحدة الثالثة الواضح في النشاط العلمي الخامس ابتدائيDocument24 pagesجذاذات الوحدة الثالثة الواضح في النشاط العلمي الخامس ابتدائيOumayama RAKIAIPas encore d'évaluation
- Pink Panter SoloDocument1 pagePink Panter SoloLeison MachadoPas encore d'évaluation
- Intro Zamba Del GrilloDocument1 pageIntro Zamba Del GrilloAgua De LumbrePas encore d'évaluation
- Personal Mountains Keith JarretDocument2 pagesPersonal Mountains Keith JarretkevinseddikiPas encore d'évaluation
- Mary Had A Little Lamb (Guitar TAB)Document1 pageMary Had A Little Lamb (Guitar TAB)Kanzul FikriPas encore d'évaluation
- Do I Wanne Know Artic MonkeysDocument3 pagesDo I Wanne Know Artic MonkeysPieter ThysPas encore d'évaluation
- Kur Tu Teci PDFDocument1 pageKur Tu Teci PDFSvens VilsonsPas encore d'évaluation
- EJERCICIO LECTURA 1 - Partitura CompletaDocument1 pageEJERCICIO LECTURA 1 - Partitura CompletaLoreley VallejosPas encore d'évaluation
- افغانستان د امريكا لپاره ويتنامDocument286 pagesافغانستان د امريكا لپاره ويتنامsayaf.charkhi1394Pas encore d'évaluation
- Para Los Ojos Mas Bellos GuitarraDocument2 pagesPara Los Ojos Mas Bellos GuitarraCarolina OjedaPas encore d'évaluation
- Faire Les CoursesDocument2 pagesFaire Les Courseshoa nguyễnPas encore d'évaluation
- Juno - Alto SaxophoneDocument2 pagesJuno - Alto SaxophoneSamjmilesPas encore d'évaluation
- Kromong BaxterDocument4 pagesKromong BaxterMuhamad FirdausPas encore d'évaluation
- 326 31Document2 pages326 31Ilias BenyekhlefPas encore d'évaluation
- Font RomeuDocument21 pagesFont RomeuIlias BenyekhlefPas encore d'évaluation
- Tangente MPSDocument21 pagesTangente MPSIlias BenyekhlefPas encore d'évaluation
- TheseDocument185 pagesTheseIlias BenyekhlefPas encore d'évaluation
- Eqdiff Cours2Document3 pagesEqdiff Cours2Ilias BenyekhlefPas encore d'évaluation
- Chap2 TariantDocument8 pagesChap2 TariantIlias BenyekhlefPas encore d'évaluation
- DivinematriceDocument64 pagesDivinematriceLolo Batt100% (1)
- Chain e MarkovDocument32 pagesChain e MarkovIlias BenyekhlefPas encore d'évaluation
- Cours Lassagne 1Document187 pagesCours Lassagne 1pagniezpriscillaPas encore d'évaluation
- Guide EvaluationDocument30 pagesGuide EvaluationIlias BenyekhlefPas encore d'évaluation
- Tel 00009238Document165 pagesTel 00009238Ilias BenyekhlefPas encore d'évaluation
- Tel 00009238Document165 pagesTel 00009238Ilias BenyekhlefPas encore d'évaluation
- Chap2 Para3 DenosDocument23 pagesChap2 Para3 DenosIlias BenyekhlefPas encore d'évaluation
- 2010 Memoire M2 Logistique - GOGUELIN Lucie 01Document95 pages2010 Memoire M2 Logistique - GOGUELIN Lucie 01Ilias BenyekhlefPas encore d'évaluation
- Chap1 Para6 DenosDocument10 pagesChap1 Para6 DenosIlias BenyekhlefPas encore d'évaluation
- Chap2 APCEDocument13 pagesChap2 APCEIlias BenyekhlefPas encore d'évaluation
- Chap1 Para3 DenosDocument33 pagesChap1 Para3 DenosIlias BenyekhlefPas encore d'évaluation
- Chap2 APCEDocument116 pagesChap2 APCEIlias BenyekhlefPas encore d'évaluation
- CCP Informatique Oct2011Document6 pagesCCP Informatique Oct2011Ilias BenyekhlefPas encore d'évaluation
- Cah 20 KebabdjianDocument10 pagesCah 20 KebabdjianIlias BenyekhlefPas encore d'évaluation
- Baubeau PereiraDocument16 pagesBaubeau PereiraIlias Benyekhlef100% (1)
- Brochure Strategie Prospect IonDocument21 pagesBrochure Strategie Prospect IonIlias BenyekhlefPas encore d'évaluation
- MOADDocument15 pagesMOADBanque BanquierPas encore d'évaluation
- BilansocialDocument14 pagesBilansocialYoussef JouiraPas encore d'évaluation
- Bates On 1Document1 pageBates On 1Ilias BenyekhlefPas encore d'évaluation
- ALES Formation 2012Document8 pagesALES Formation 2012Ilias BenyekhlefPas encore d'évaluation
- BibliographieDocument8 pagesBibliographieIlias BenyekhlefPas encore d'évaluation
- Asservissement Non Lineaire 2Document87 pagesAsservissement Non Lineaire 2Nouha Kh50% (2)
- Art 15-1-5 GuzelianDocument8 pagesArt 15-1-5 GuzelianIlias BenyekhlefPas encore d'évaluation
- A Me 6043 SyllabusDocument8 pagesA Me 6043 SyllabusIlias BenyekhlefPas encore d'évaluation
- Theorie Des Graphes-ExtraitDocument29 pagesTheorie Des Graphes-ExtraitIlham Yacine100% (1)
- Devoir de Maison3Document2 pagesDevoir de Maison3Akpo ArmandPas encore d'évaluation
- INF941 TD3 Crypto CorrigeDocument2 pagesINF941 TD3 Crypto CorrigeMed KarimPas encore d'évaluation
- Nombres Instructions ÉlémentairesDocument8 pagesNombres Instructions ÉlémentairesInes DhamerPas encore d'évaluation
- C3 ArithmetiqueOrdinateursDocument118 pagesC3 ArithmetiqueOrdinateursMohammed BabaPas encore d'évaluation
- Theorie Casse Tete MathDocument30 pagesTheorie Casse Tete MathmaximinPas encore d'évaluation
- C Td3 Les Boucles: Exercice 1Document3 pagesC Td3 Les Boucles: Exercice 1أسامة يعقوبيPas encore d'évaluation
- TC 01 Arithmétique Sr4Fr AmmariDocument1 pageTC 01 Arithmétique Sr4Fr AmmariSasoukeiPas encore d'évaluation
- Cours Optimisation Des GraphesDocument77 pagesCours Optimisation Des Graphessalahdin sehliPas encore d'évaluation
- Algorithmique Avancee Et ComplexiteDocument101 pagesAlgorithmique Avancee Et Complexiteامين نفيد100% (4)
- Corrigé Ex 20 Et 23Document1 pageCorrigé Ex 20 Et 23anaPas encore d'évaluation
- Les Suites Numeriques Exercices Non Corriges 2 7Document1 pageLes Suites Numeriques Exercices Non Corriges 2 7Zo Zo100% (1)
- Arith 2022 ResumDocument43 pagesArith 2022 ResumTouria OunhariPas encore d'évaluation
- Fibonacci 2 PDFDocument84 pagesFibonacci 2 PDFMENYE Elie collinsPas encore d'évaluation
- TH Info PolycDocument2 pagesTH Info PolycChouichi GhadaPas encore d'évaluation
- Cours Chap 14 Arbre Couvrant MinimalDocument12 pagesCours Chap 14 Arbre Couvrant MinimalHanan TalibPas encore d'évaluation
- Corrige Ds 1601Document9 pagesCorrige Ds 1601爸 Ray 爸Pas encore d'évaluation
- 23 Loi de Reciprocite Quadratique BisDocument3 pages23 Loi de Reciprocite Quadratique BisAmin ZekriPas encore d'évaluation
- Controle Terminal 2019 2020 RSTDocument3 pagesControle Terminal 2019 2020 RSTHachette MapedPas encore d'évaluation
- Theorie Des NombresDocument106 pagesTheorie Des NombresJose Roberto Duarte100% (1)
- AlgoII TD3Document2 pagesAlgoII TD3aissamPas encore d'évaluation
- Exercice 2Document9 pagesExercice 2Lynda SouissiPas encore d'évaluation
- ArithmDocument69 pagesArithmmfaraz110Pas encore d'évaluation
- Theorie Des Nombres PDFDocument150 pagesTheorie Des Nombres PDFGHANI810Pas encore d'évaluation
- Master GL Graphe ch1 EnvDocument90 pagesMaster GL Graphe ch1 EnvhakimaPas encore d'évaluation
- Complex It eDocument29 pagesComplex It eHfd NourPas encore d'évaluation
- 02 Algorithmes DjikstraDocument54 pages02 Algorithmes DjikstraaichaPas encore d'évaluation
- DTL 1 SpeDocument1 pageDTL 1 SpeAli Ben MessaoudPas encore d'évaluation
- CC 217+CorrigéDocument4 pagesCC 217+CorrigéYaacoub El GuezdarPas encore d'évaluation
- TD 1cppa1 23-24Document3 pagesTD 1cppa1 23-24Jh BmnPas encore d'évaluation