Vous aimerez peut-être aussi
- Recherche OperationnelDocument2 pagesRecherche OperationnelJihed BeyPas encore d'évaluation
- Bases de Données: Exercices: IUT de Villetaneuse - R&T 1 AnnéeDocument13 pagesBases de Données: Exercices: IUT de Villetaneuse - R&T 1 AnnéeNour KkhaPas encore d'évaluation
- TD M2104 PDFDocument12 pagesTD M2104 PDFMohamed MeskiPas encore d'évaluation
- Harmonie Pour La Guitare Et La BasseDocument43 pagesHarmonie Pour La Guitare Et La BasseGreg Wailliez100% (4)
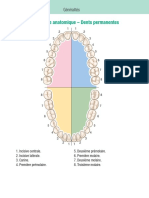
- Corrige Anatomie TVa Janvier 2016Document3 pagesCorrige Anatomie TVa Janvier 2016Feryel ZbidiPas encore d'évaluation
- Pointage MontbeliardeDocument4 pagesPointage MontbeliardeGéraldine Jourdan100% (1)
- 921 - Recherche - 2023-08-11T083516.117Document13 pages921 - Recherche - 2023-08-11T083516.117Zelkif NjamenPas encore d'évaluation
- IntroIA CM 02 ResProbDocument42 pagesIntroIA CM 02 ResProbmedinialex9Pas encore d'évaluation
- Flight of The Bumble Bee by Nikolai Rimsky-KorsakovDocument5 pagesFlight of The Bumble Bee by Nikolai Rimsky-Korsakovlee geddyPas encore d'évaluation
- Abbani SaidDocument5 pagesAbbani SaidcauchyPas encore d'évaluation
- Rekod Transit PBD 2021Document4 pagesRekod Transit PBD 2021SITI MAWARNI BINTI MURAT MoePas encore d'évaluation
- Imparfait Mots Croisés Le Fichier WORDDocument32 pagesImparfait Mots Croisés Le Fichier WORDAdda AddaPas encore d'évaluation
- Pierre Gilles AaaDocument6 pagesPierre Gilles AaaNuria CastroPas encore d'évaluation
- Gammes ChromatiquesDocument1 pageGammes ChromatiquesAvant AprèsPas encore d'évaluation
- Cours de CristrllogDocument29 pagesCours de Cristrllogmerouane maamar bassataPas encore d'évaluation
- TF 00001054Document20 pagesTF 00001054ToP MarPas encore d'évaluation
- 4e en 3e-Maths-Été19Document9 pages4e en 3e-Maths-Été19naglaaPas encore d'évaluation
- Chapitre 471527Document11 pagesChapitre 471527Salim Hadj SadokPas encore d'évaluation
- Tiras FraccionesDocument1 pageTiras FraccionesJimenes ZaukPas encore d'évaluation
- SAI10101 Dossier Evaluation Finale Dessin TechDocument5 pagesSAI10101 Dossier Evaluation Finale Dessin Techlud empPas encore d'évaluation
- Structures Algébriques by Javad MashreghiDocument155 pagesStructures Algébriques by Javad MashreghiNatôuhor SokroPas encore d'évaluation
- PR#1 (Ans)Document3 pagesPR#1 (Ans)Arjuna SarumpaetPas encore d'évaluation
- Les Spermaphytes TDDocument4 pagesLes Spermaphytes TDOssete BricePas encore d'évaluation
- Tp4 Calcul Raideur Rdm6 Optimisation de Structure Logiciel RDM Le ManDocument5 pagesTp4 Calcul Raideur Rdm6 Optimisation de Structure Logiciel RDM Le ManAmine RdPas encore d'évaluation
- Fiche Math Equation de Droite Tangente Et AsymptoteDocument15 pagesFiche Math Equation de Droite Tangente Et AsymptoteTamaru DialloPas encore d'évaluation
- Data Two Way AnovaDocument2 pagesData Two Way AnovaRafni FajriatiPas encore d'évaluation
- (WWW - Al7ibre - Com) Devoir 1 Semestre 1 SVT TCS-BIOF Exemple 4Document3 pages(WWW - Al7ibre - Com) Devoir 1 Semestre 1 SVT TCS-BIOF Exemple 4Brahim Omari100% (2)
- Aula Bandolim (Mudança de Posição - 7 Posições - Frases - Escalas Maiores)Document3 pagesAula Bandolim (Mudança de Posição - 7 Posições - Frases - Escalas Maiores)Felipe VianaPas encore d'évaluation
- SudokuDocument1 pageSudokuRose-Annmel CortezPas encore d'évaluation
- Dev RO 1Document7 pagesDev RO 1MAMANE SOULEYPas encore d'évaluation
- Dynamique D'un PenduleDocument10 pagesDynamique D'un Pendulecoucou garbiPas encore d'évaluation
- Devoir P2 BIO 1Document2 pagesDevoir P2 BIO 1caroline.irasquePas encore d'évaluation
- Page 0055Document1 pagePage 0055صلاح الدين معوPas encore d'évaluation
- 8fa57-Perforateur A Papier Avec CorrectionDocument3 pages8fa57-Perforateur A Papier Avec CorrectionMajda El-aouni100% (3)
- Evaluation de Geometrie cm2Document4 pagesEvaluation de Geometrie cm2Anne ChannelPas encore d'évaluation
- Algèbre Et Theorie GaloisiennesDocument3 pagesAlgèbre Et Theorie GaloisiennesSarah SouidPas encore d'évaluation
- Cours de Mathematiques Speciales Tome 1 Algebre - E. (Edmond) Ramis, C. (Claude) Deschamps, J. Odoux - 2225815011Document450 pagesCours de Mathematiques Speciales Tome 1 Algebre - E. (Edmond) Ramis, C. (Claude) Deschamps, J. Odoux - 2225815011NiceLittleRabbit93% (15)
- Ejercicio de Tecnica DiagonalDocument1 pageEjercicio de Tecnica DiagonalRomina CuevaPas encore d'évaluation
- DaduDocument4 pagesDaduIstiqomahPas encore d'évaluation
- Practica para GuitarraDocument3 pagesPractica para GuitarraPeter LitwinPas encore d'évaluation
- Ti TD Ees4Document12 pagesTi TD Ees4Meriam KooliPas encore d'évaluation
- Ejercicios, ProblemarioDocument2 pagesEjercicios, ProblemarioALAN YAFTE LOPEZ ALVAREZPas encore d'évaluation
- RèglesDocument22 pagesRèglesJeanjean59Pas encore d'évaluation
- Sommets3 Ch04 CorrigeDocument9 pagesSommets3 Ch04 CorrigeÉdouard Poirier100% (2)
- Ipt Mpsi Tp2 CorrigeDocument18 pagesIpt Mpsi Tp2 CorrigeSwayziiPas encore d'évaluation
- Y 4 M FM 6 RK PK UG6 PW PM TAgni Ggpgy Y0 C SCQ KPV5 Op EUAb WX68 Ha 7Document4 pagesY 4 M FM 6 RK PK UG6 PW PM TAgni Ggpgy Y0 C SCQ KPV5 Op EUAb WX68 Ha 7ayissi nkollo marcel christelPas encore d'évaluation
- TD Newrork Science 2021-RendreDocument5 pagesTD Newrork Science 2021-RendreYassine ZitouniPas encore d'évaluation
- 15 Découverte Des FractionsDocument32 pages15 Découverte Des FractionsFredPas encore d'évaluation
- Chap 5 - Ex2b - Division Euclidienne (Preuve) - CORRIGEDocument3 pagesChap 5 - Ex2b - Division Euclidienne (Preuve) - CORRIGEhouda.saaliPas encore d'évaluation
- Correction Ex Montage Et DémontageDocument4 pagesCorrection Ex Montage Et DémontageMarouen MekkiPas encore d'évaluation
- CH 18 Treillis Exercices Corriges 5Document2 pagesCH 18 Treillis Exercices Corriges 5SD Post-Graduation CU-Tamanrasset100% (1)
- Le Deliateur Pour Basse S PDFDocument63 pagesLe Deliateur Pour Basse S PDFBAHRI100% (1)
- VAL200 Memotechnique Bob Man EG V2Document12 pagesVAL200 Memotechnique Bob Man EG V2Oumaima EzzaherPas encore d'évaluation
- ACFrOgB25qH7y Zk0VkrY7Hl w7OEnpyC6BmGSj6wMX1VWGj-PKjnQL1Tq56aYiLF-W JaC3RymFVOTvmds-NSa2XiYkpmbZUbBmFerSFIbHHqhJWHbgfqFElV9mwFGyFQcPRd12akE0uaiM2 LQDocument10 pagesACFrOgB25qH7y Zk0VkrY7Hl w7OEnpyC6BmGSj6wMX1VWGj-PKjnQL1Tq56aYiLF-W JaC3RymFVOTvmds-NSa2XiYkpmbZUbBmFerSFIbHHqhJWHbgfqFElV9mwFGyFQcPRd12akE0uaiM2 LQLuis André GgggPas encore d'évaluation
- Modele de Feuille de Presence FormationDocument3 pagesModele de Feuille de Presence FormationGaluhPas encore d'évaluation
- Guide de la recherche documentaireD'EverandGuide de la recherche documentairePas encore d'évaluation
- 21 Conj 2010Document13 pages21 Conj 2010Orubiyi FADEYIPas encore d'évaluation
- BIM2008Document68 pagesBIM2008Orubiyi FADEYIPas encore d'évaluation
- Cours de Phylognie MolculaireDocument49 pagesCours de Phylognie MolculaireOrubiyi FADEYIPas encore d'évaluation
- Phylogénie Moléculaire: Topic: Source File: Field: Variant Subject HeadingsDocument3 pagesPhylogénie Moléculaire: Topic: Source File: Field: Variant Subject HeadingsOrubiyi FADEYIPas encore d'évaluation
- (Elena Cassin) La Splendeur DivineDocument82 pages(Elena Cassin) La Splendeur DivineomarnsheaPas encore d'évaluation
- Le Fruit DéfenduDocument6 pagesLe Fruit DéfenduStradin Bien-aimePas encore d'évaluation
- Chapitre 2 Aftis Expo 3Document12 pagesChapitre 2 Aftis Expo 3Ayyoub DriouechPas encore d'évaluation
- Supports de CoursDocument62 pagesSupports de CoursSoufian Ouenzar100% (1)
- Cours Maintenance 2BENIM 1 PDFDocument99 pagesCours Maintenance 2BENIM 1 PDFhocine100% (1)
- Ebook Petit Cours D Autodefense IntellectuelleDocument345 pagesEbook Petit Cours D Autodefense IntellectuelleZoula Khidri100% (5)
- 3 Phase RectifierDocument72 pages3 Phase RectifierViet VietPas encore d'évaluation
- Marie-Madeleine by Sylvaine Landrivon (Landrivon, Sylvaine)Document126 pagesMarie-Madeleine by Sylvaine Landrivon (Landrivon, Sylvaine)Gabriela Negru100% (1)
- 10 Sujets Pour Lesquels Nous Devrions Prier Plus SouventDocument4 pages10 Sujets Pour Lesquels Nous Devrions Prier Plus SouventJacques ZinsePas encore d'évaluation
- Guide Lire Ecrire CP 18 Version1juin18 PDFDocument5 pagesGuide Lire Ecrire CP 18 Version1juin18 PDFMustapha OUDIJAPas encore d'évaluation
- Cours Initiation À L'architectureDocument271 pagesCours Initiation À L'architectureFoufa Archi100% (3)
- Programme Français Niveaua1 - 1Document4 pagesProgramme Français Niveaua1 - 1bluegreeneyesPas encore d'évaluation
- Les Socles de Competences - Formation Mathematique (Ressource 1653) PDFDocument15 pagesLes Socles de Competences - Formation Mathematique (Ressource 1653) PDFdgsqfruerjtrsPas encore d'évaluation
- Preparation A L'envir ProfessDocument12 pagesPreparation A L'envir Professeya.jemaiPas encore d'évaluation
- Bedel Olle Josiana RAPPORT DE STAGE 3ème3 (10) .OdtDocument13 pagesBedel Olle Josiana RAPPORT DE STAGE 3ème3 (10) .OdtjosianaPas encore d'évaluation
- tp15 MaiverDocument19 pagestp15 MaiverhenryPas encore d'évaluation
- Khaled Abou El Fadl Rebellion and ViolenDocument2 pagesKhaled Abou El Fadl Rebellion and ViolenlekohPas encore d'évaluation
- Cécile DemaudeDocument4 pagesCécile DemaudeliliphinexPas encore d'évaluation
- Méthodologie Écrit BacDocument10 pagesMéthodologie Écrit Baclucienhardy73Pas encore d'évaluation
- Viento Recio - Partitura CompletaDocument4 pagesViento Recio - Partitura CompletaAdonayPas encore d'évaluation
- Cours MS1 Treillis MetalliquesDocument33 pagesCours MS1 Treillis MetalliquesJean-Vincent Kandela100% (1)
- Règlement D'application de L'accord Portant Révision de L'accord de Bangui 1977Document8 pagesRèglement D'application de L'accord Portant Révision de L'accord de Bangui 1977Adrien RainPas encore d'évaluation
- Anticalciques KB 2018Document3 pagesAnticalciques KB 2018Simona IonitaPas encore d'évaluation
- FREN 4101 B ExercicesDocument5 pagesFREN 4101 B ExercicesMa BeleuPas encore d'évaluation
- Cours 2 Naissance de La Modernite - CPDocument146 pagesCours 2 Naissance de La Modernite - CPOussama ElkPas encore d'évaluation
- Swade Deadlandstheweirdwest ScntoutceqDocument2 pagesSwade Deadlandstheweirdwest ScntoutceqLaurentPas encore d'évaluation
- Elle Est Bénie de DieuDocument1 pageElle Est Bénie de Dieudark musPas encore d'évaluation
- ME Resume Conception Des Mecanismes Version 2022 2023 AV 10 01 2023 Période 3Document55 pagesME Resume Conception Des Mecanismes Version 2022 2023 AV 10 01 2023 Période 3ghali besriPas encore d'évaluation
- Lauzanne L. Loubens G. Peces Del Río Mamoré (1985)Document113 pagesLauzanne L. Loubens G. Peces Del Río Mamoré (1985)Lila da Silva MoralesPas encore d'évaluation
- Denombrement PDFDocument5 pagesDenombrement PDFAhmed EnnajiPas encore d'évaluation