Vous aimerez peut-être aussi
- Correction Examen Big Data 2020 2021 Session NormaleDocument4 pagesCorrection Examen Big Data 2020 2021 Session NormaleNora Habrich88% (8)
- Iscae IfDocument71 pagesIscae IffbentaharPas encore d'évaluation
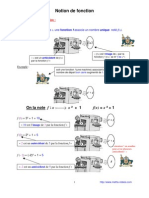
- Notion de Fonction (3ème)Document3 pagesNotion de Fonction (3ème)MATHS - VIDEOSPas encore d'évaluation
- Programmation LinéaireDocument53 pagesProgrammation LinéaireIssam Dhahri100% (1)
- Exam Final-Big DataDocument3 pagesExam Final-Big DataFerdaous Hdioud100% (3)
- Vocabulaire Kabyle de L'ostéologie Et de L'orthopédieDocument330 pagesVocabulaire Kabyle de L'ostéologie Et de L'orthopédieamazighisant100% (5)
- Résumé Des Conflits D'intérêtsDocument7 pagesRésumé Des Conflits D'intérêtsDoha67% (3)
- QCM Inf 356Document13 pagesQCM Inf 356Sali Yaya Farani100% (3)
- Ordre Et Opérations (4ème)Document3 pagesOrdre Et Opérations (4ème)MATHS - VIDEOS75% (4)
- Structures de Données I - 2022 - UAMDocument357 pagesStructures de Données I - 2022 - UAMNasserPas encore d'évaluation
- Devoir Bac Blanc TIC Avec La CORRECTIONDocument20 pagesDevoir Bac Blanc TIC Avec La CORRECTIONlinda Ben AttiaPas encore d'évaluation
- Bigdata 1Document47 pagesBigdata 1Marwan ElPas encore d'évaluation
- Ht00cours Texte XXXDocument14 pagesHt00cours Texte XXXAhmed BelaïdPas encore d'évaluation
- 8 Patrons Algorithmes Ac PDFDocument52 pages8 Patrons Algorithmes Ac PDFSerge AlainPas encore d'évaluation
- Table de Hachage PDFDocument5 pagesTable de Hachage PDFJose Landry BogbéPas encore d'évaluation
- Hach AgeDocument39 pagesHach Agefred gbegbePas encore d'évaluation
- CM BonusDocument9 pagesCM BonusAlexis De-lazzariPas encore d'évaluation
- Gretl Guide (101 150)Document50 pagesGretl Guide (101 150)Taha NajidPas encore d'évaluation
- TP 06Document3 pagesTP 06Daignon Max Nicolas ATINDOKPOPas encore d'évaluation
- CH 3Document9 pagesCH 3Kabb kenkenPas encore d'évaluation
- Algo Chap1Document42 pagesAlgo Chap1abde aznagPas encore d'évaluation
- Tdtme 1Document10 pagesTdtme 1bouba lodiaPas encore d'évaluation
- Algorithmique Volume 1 at BULLET IntroduDocument74 pagesAlgorithmique Volume 1 at BULLET IntroduLionelPas encore d'évaluation
- 4 - Les TableauxDocument38 pages4 - Les TableauxEspoir MAKAYA MBANZILAPas encore d'évaluation
- Lab 3Document15 pagesLab 3Maryâm BôuchPas encore d'évaluation
- 01 Algo Av Master INSEA Complexite TriDocument64 pages01 Algo Av Master INSEA Complexite Trithe other sidePas encore d'évaluation
- Cours Algo 1 2Document160 pagesCours Algo 1 2halissoPas encore d'évaluation
- NoSQLziad (1) - 1Document34 pagesNoSQLziad (1) - 1Dimokrati HoussamPas encore d'évaluation
- Cours Algo2-Chapitre3Document9 pagesCours Algo2-Chapitre3David Kevin OvengaPas encore d'évaluation
- 2 Memoire RelDocument28 pages2 Memoire RelAquarius87Pas encore d'évaluation
- Algorithmique FST 2023Document70 pagesAlgorithmique FST 2023L'empereur DarkalexPas encore d'évaluation
- Cours VBA 20 - Utilisations Des TableauxDocument4 pagesCours VBA 20 - Utilisations Des TableauxSambPas encore d'évaluation
- Rapport Traitement Des Données MassivesDocument12 pagesRapport Traitement Des Données MassivesM MAXPas encore d'évaluation
- Hach AgeDocument30 pagesHach Agebenguerine.seifeddinePas encore d'évaluation
- Bi - 28 11 2017Document4 pagesBi - 28 11 2017bamsPas encore d'évaluation
- MAPREDUCEDocument9 pagesMAPREDUCEpatrice mvogoPas encore d'évaluation
- BIG DATA Et RDocument6 pagesBIG DATA Et RŠməì ĹĕPas encore d'évaluation
- Semaine 8Document51 pagesSemaine 8radPas encore d'évaluation
- BDD 4Document48 pagesBDD 4KhadyPas encore d'évaluation
- Abstraction Des ProcéduresDocument4 pagesAbstraction Des Procéduresoumaima hajjiPas encore d'évaluation
- Cour 9Document7 pagesCour 9Ran IaPas encore d'évaluation
- Projet TP 2.1 Règles Association Oct2020Document6 pagesProjet TP 2.1 Règles Association Oct2020Cedric KonguepPas encore d'évaluation
- Chapitre 1Document8 pagesChapitre 1amara abdelkarimePas encore d'évaluation
- Intro Matlab09Document21 pagesIntro Matlab09kanet17Pas encore d'évaluation
- Janvier 2023Document2 pagesJanvier 2023Yi DirPas encore d'évaluation
- Poly BDMDocument15 pagesPoly BDMWafa BenzaouiPas encore d'évaluation
- Séance 2 - Transact SQL 2 - Administration Base de DonnéesDocument27 pagesSéance 2 - Transact SQL 2 - Administration Base de DonnéesMed Taha HakamPas encore d'évaluation
- Week1 Chap 1Document16 pagesWeek1 Chap 1AKA MICHAEL BERENGERPas encore d'évaluation
- Null 5Document15 pagesNull 5arielle stella TSAMOPas encore d'évaluation
- Hadoop EcosystemDocument37 pagesHadoop Ecosystemhajar.filali4Pas encore d'évaluation
- Cours Matlab 1Document79 pagesCours Matlab 1LOUNDOU orthegaPas encore d'évaluation
- TP 1 - Introduction À MatlabDocument13 pagesTP 1 - Introduction À MatlabSouad Ahmed BenchiheubPas encore d'évaluation
- Cours No SQLDocument8 pagesCours No SQLkamel eddinePas encore d'évaluation
- Les Fonctions de Hachage CryptographiquesDocument12 pagesLes Fonctions de Hachage CryptographiquesAmice Quentin MavoungouPas encore d'évaluation
- Chapitre 1 TDA PDFDocument23 pagesChapitre 1 TDA PDFFeten NabiPas encore d'évaluation
- Mod Elisation Et M Ethodes Num Eriques Pour Les Sciences Du Vivant. TP1 - InitiationDocument11 pagesMod Elisation Et M Ethodes Num Eriques Pour Les Sciences Du Vivant. TP1 - Initiationoscar chambaudPas encore d'évaluation
- Enp 12Document28 pagesEnp 12Aiglecity OukassouPas encore d'évaluation
- Enoncé Du TPDocument12 pagesEnoncé Du TPouijdan boumahrezPas encore d'évaluation
- MetaheuristiquesDocument7 pagesMetaheuristiquesYao jean lucPas encore d'évaluation
- Cours - 1 Introduction À MatlabDocument8 pagesCours - 1 Introduction À MatlabhamamaPas encore d'évaluation
- TP VBA TableauxDocument12 pagesTP VBA Tableauxlucas. DsPas encore d'évaluation
- Idl NosqlDocument54 pagesIdl NosqlYesmine MakkesPas encore d'évaluation
- Coupes de graphiques de vision par ordinateur: Explorer les coupes graphiques en vision par ordinateurD'EverandCoupes de graphiques de vision par ordinateur: Explorer les coupes graphiques en vision par ordinateurPas encore d'évaluation
- Remplissage d'inondation: Flood Fill : Explorer le terrain dynamique de la vision par ordinateurD'EverandRemplissage d'inondation: Flood Fill : Explorer le terrain dynamique de la vision par ordinateurPas encore d'évaluation
- Détermination des surfaces cachées: Dévoiler les secrets de la vision par ordinateurD'EverandDétermination des surfaces cachées: Dévoiler les secrets de la vision par ordinateurPas encore d'évaluation
- Rapport D'intervention IndustrieDocument2 pagesRapport D'intervention IndustrieAdama SawadogoPas encore d'évaluation
- 10-DS Chaîne de MontageDocument3 pages10-DS Chaîne de MontagesaulnierPas encore d'évaluation
- VARIATEUR - DE - VITESSE - Doc ProfDocument3 pagesVARIATEUR - DE - VITESSE - Doc Profsaid100% (2)
- 24ème Dimanche Année CDocument2 pages24ème Dimanche Année CPatrick LessiPas encore d'évaluation
- La Place de La RSE Dans L Approche RelatDocument728 pagesLa Place de La RSE Dans L Approche RelattrabelsiPas encore d'évaluation
- MAROC - TELECOM - Une - Correction - Disproportionnée - en - BourseDocument8 pagesMAROC - TELECOM - Une - Correction - Disproportionnée - en - BourseYouri PlaysPas encore d'évaluation
- Liste Des Cartes Évolution CélesteDocument1 pageListe Des Cartes Évolution CélesteMohammed ChihazPas encore d'évaluation
- Resume Du TPDocument9 pagesResume Du TPMOUGANGPas encore d'évaluation
- Chapitre 434Document18 pagesChapitre 434dieudonnepooda71Pas encore d'évaluation
- PMMP Formulaire D Inscription Des Entreprises 2017Document2 pagesPMMP Formulaire D Inscription Des Entreprises 2017Aalaeddine Afifi100% (2)
- Exploration Biologique Du FoieDocument9 pagesExploration Biologique Du FoieYounes Hadj CharefPas encore d'évaluation
- Guide GLPI-FusionInventory - NagiosDocument12 pagesGuide GLPI-FusionInventory - NagiosAITALI MohamedPas encore d'évaluation
- Rappel Sur Le ParodonteDocument27 pagesRappel Sur Le Parodontemisha melissaPas encore d'évaluation
- Projet Final CCNA1Document4 pagesProjet Final CCNA1Vito CoppolaPas encore d'évaluation
- Contrôles Particulaires Et Microbiologiques de L'air Et Contrôles Microbiologiques Des Surfaces Dans Les Établissements de Santé.Document12 pagesContrôles Particulaires Et Microbiologiques de L'air Et Contrôles Microbiologiques Des Surfaces Dans Les Établissements de Santé.amiraPas encore d'évaluation
- TD Tns-SticDocument3 pagesTD Tns-Sticqzsv7wpnnwPas encore d'évaluation
- TP #1 CristallographieDocument14 pagesTP #1 CristallographieMohamed CHIBANPas encore d'évaluation
- Recyclage Dechets Plastiques Converti ConvertiDocument15 pagesRecyclage Dechets Plastiques Converti ConvertiYoo BahPas encore d'évaluation
- Chapitre IV équilibre Liquide-SolideDocument8 pagesChapitre IV équilibre Liquide-SolideChamssou BoustilaPas encore d'évaluation
- Chapitre 2 - Evolutions Économiques Et Sociales Dans Les Pays Occidentaux D'une Guerre À L'autreDocument24 pagesChapitre 2 - Evolutions Économiques Et Sociales Dans Les Pays Occidentaux D'une Guerre À L'autreNazwa NubowoPas encore d'évaluation
- CHAPITRE I1 SupervisionDocument4 pagesCHAPITRE I1 Supervisionkamgabriel920Pas encore d'évaluation
- TD10 AOP CaracteristiquesDocument31 pagesTD10 AOP CaracteristiquesRaouia AouiniPas encore d'évaluation
- Cas Pratique Bilan À Élaborer Av SolutionDocument5 pagesCas Pratique Bilan À Élaborer Av SolutionAfif Ben SaidPas encore d'évaluation
- Thèse: Philosophiæ Doctor (Ph. D.)Document188 pagesThèse: Philosophiæ Doctor (Ph. D.)Oussama ChahirPas encore d'évaluation
- DW+P5+Optimisation Debug+ +Modele+Rapport+InterventionDocument16 pagesDW+P5+Optimisation Debug+ +Modele+Rapport+Interventionriyah22654Pas encore d'évaluation