Vous aimerez peut-être aussi
- TD Architecture Des Ordinateurs PDFDocument17 pagesTD Architecture Des Ordinateurs PDFAhmedBoukadPas encore d'évaluation
- Cours VHDL Et FPGADocument135 pagesCours VHDL Et FPGAMounira Tarhouni100% (1)
- Fiche de Travaux Diriges PDFDocument6 pagesFiche de Travaux Diriges PDFGoran Person DongmoPas encore d'évaluation
- Tower FrenchDocument215 pagesTower FrenchbegougPas encore d'évaluation
- TPautomatique TIMQ2018Document16 pagesTPautomatique TIMQ2018fatima azalmadPas encore d'évaluation
- TP Filtrage Numerique DSPDocument7 pagesTP Filtrage Numerique DSPRACHID100% (1)
- Initiation MatLabDocument31 pagesInitiation MatLabHamzaHariatePas encore d'évaluation
- CORRIGE EXAMENJanvier2017Document4 pagesCORRIGE EXAMENJanvier2017Sel Ma100% (1)
- DSP Resume PDFDocument31 pagesDSP Resume PDFStephane Durel MbidaPas encore d'évaluation
- MLPDocument6 pagesMLPHussein SuprêmePas encore d'évaluation
- RCP208 TP4Document4 pagesRCP208 TP4Soukaina AcharkiPas encore d'évaluation
- Rapport Identifecation NaitaliDocument11 pagesRapport Identifecation NaitaliEl GhafraouiPas encore d'évaluation
- TP2 PDFDocument3 pagesTP2 PDFAridje. EljanaPas encore d'évaluation
- RCP208 TP4 PDFDocument4 pagesRCP208 TP4 PDFSofiene GuedriPas encore d'évaluation
- Exa 2Document5 pagesExa 2iheblinko21Pas encore d'évaluation
- DSPCours 1Document13 pagesDSPCours 1Oussama MstraiiPas encore d'évaluation
- TP MatlabDocument14 pagesTP MatlabLakhdari BoutheinaPas encore d'évaluation
- TP MatlabDocument18 pagesTP MatlabLakhdari BoutheinaPas encore d'évaluation
- 3-Big Data Exercices ISIA Partie 2 Centrale Dec2018 Janv 2019Document88 pages3-Big Data Exercices ISIA Partie 2 Centrale Dec2018 Janv 2019zaki nygmaPas encore d'évaluation
- AlgoDocument142 pagesAlgoanonymeeeePas encore d'évaluation
- Examen Algo AfraitesDocument5 pagesExamen Algo AfraitesKontePas encore d'évaluation
- Fascicule PPCE 2122Document29 pagesFascicule PPCE 2122Amine BoujnahPas encore d'évaluation
- DSP tp1 0304 C PDFDocument12 pagesDSP tp1 0304 C PDFSaliha HarizePas encore d'évaluation
- Chapitre1 Méthodes Numériques Et ProgrammationDocument8 pagesChapitre1 Méthodes Numériques Et ProgrammationTaki EddinePas encore d'évaluation
- FD Programmation SystemeDocument5 pagesFD Programmation Systemevanel nwabaPas encore d'évaluation
- Corr PDFDocument8 pagesCorr PDFSoundous AyariPas encore d'évaluation
- Exam 1920Document2 pagesExam 1920Msik MssiPas encore d'évaluation
- 2018 02 RCP209correctionDocument5 pages2018 02 RCP209correctionJames OptimistePas encore d'évaluation
- Travaux Pratiques 4Document9 pagesTravaux Pratiques 4barhoumi oussamaPas encore d'évaluation
- Chapitre 5Document8 pagesChapitre 5oussama KOBZILIPas encore d'évaluation
- ds1 SolutionDocument14 pagesds1 SolutionColmain NassiriPas encore d'évaluation
- Oussaoui Sabir TP Matlab Part 2Document10 pagesOussaoui Sabir TP Matlab Part 2Sabir oussaouiPas encore d'évaluation
- Exam 2223Document2 pagesExam 2223Msik MssiPas encore d'évaluation
- MSP tp1Document9 pagesMSP tp1MechernenePas encore d'évaluation
- mn03 1Document15 pagesmn03 1Amir Na DzPas encore d'évaluation
- Compte Rendu TP5 Barriga GUODocument12 pagesCompte Rendu TP5 Barriga GUOricardo BarrigaPas encore d'évaluation
- TP RCP208 PMC RegressionDocument9 pagesTP RCP208 PMC RegressionDaly ZeddiniPas encore d'évaluation
- TP Diagraphie en Milieux PoreuxDocument11 pagesTP Diagraphie en Milieux PoreuxMohamed OussamaPas encore d'évaluation
- tp1 - OpenmpDocument13 pagestp1 - Openmpkatia ines cherifi100% (1)
- Rapport Soumia Abdellaoui Ci1Document29 pagesRapport Soumia Abdellaoui Ci1soumia abdellaouiPas encore d'évaluation
- TP AutomatiqueDocument19 pagesTP AutomatiquemainoPas encore d'évaluation
- M23 CC 1A TFM Mathématique 22-23 V1Document1 pageM23 CC 1A TFM Mathématique 22-23 V1badr hadriPas encore d'évaluation
- Numpy SlidesDocument48 pagesNumpy Slideszenalabidine mahamat tahirPas encore d'évaluation
- HTML To PDFDocument13 pagesHTML To PDFMerou ndiayePas encore d'évaluation
- Tp2: Deep Learning: TensorflowDocument9 pagesTp2: Deep Learning: Tensorflowkais.chammakhiPas encore d'évaluation
- Examen Economertire Non paraDocument14 pagesExamen Economertire Non paramamoudou tallaPas encore d'évaluation
- Antenne Et Propagation RadioDocument48 pagesAntenne Et Propagation Radiocolin37100% (2)
- Examen AO Corrig Univ Guelma 2018Document6 pagesExamen AO Corrig Univ Guelma 2018Siaka Dycosh BertePas encore d'évaluation
- TP ALL Outils 2015Document32 pagesTP ALL Outils 2015buss comptePas encore d'évaluation
- DemomatlabDocument8 pagesDemomatlabAbdelmoudjib BenkadaPas encore d'évaluation
- TP 3 de Compression. Sujet - La Norme JPEG de Compression Des Images Fixes. S7 Master 1 Audiovisuel Et Multimédia - ISIS Clément FOLLET Avril 2008Document12 pagesTP 3 de Compression. Sujet - La Norme JPEG de Compression Des Images Fixes. S7 Master 1 Audiovisuel Et Multimédia - ISIS Clément FOLLET Avril 2008Houda SenoussiPas encore d'évaluation
- Projet Optimisation Deep Learning Theorie Et PratiqueDocument4 pagesProjet Optimisation Deep Learning Theorie Et PratiqueAbdoulayePas encore d'évaluation
- Rapport de CryptographieDocument16 pagesRapport de CryptographieDARIL RAOUL KENGNE WAMBO100% (1)
- EXAMEN SSI Janvier2020Document1 pageEXAMEN SSI Janvier2020unfair deathPas encore d'évaluation
- TP2 2018Document6 pagesTP2 2018limited editionPas encore d'évaluation
- Optimisation TP OTDocument8 pagesOptimisation TP OTAbdesselem Boulkroune100% (1)
- TP3 Andreff Etal-GoughDocument4 pagesTP3 Andreff Etal-GoughHoussem RadhouanePas encore d'évaluation
- Partiel H03solDocument4 pagesPartiel H03soloussama elkaissiPas encore d'évaluation
- 2015 08 21 Examen Jan2007collectifDocument3 pages2015 08 21 Examen Jan2007collectifMēđ GouigaPas encore d'évaluation
- 4 DynamDocument30 pages4 DynamHichem KemaliPas encore d'évaluation
- Formation 3D par la pratique avec C#5 et WPF: Modeliser des moleculesD'EverandFormation 3D par la pratique avec C#5 et WPF: Modeliser des moleculesPas encore d'évaluation
- Résumé POODocument3 pagesRésumé POOThéo Phanie100% (1)
- 6.2.4.4 Packet Tracer - Configuring IPv6 Static and Default Routes InstructionsDocument3 pages6.2.4.4 Packet Tracer - Configuring IPv6 Static and Default Routes InstructionsBrazza In My VeinsPas encore d'évaluation
- Rapport EMSI FinalDocument28 pagesRapport EMSI FinalAchraf MarchoudPas encore d'évaluation
- 12.2.2.9 Lab - Regular Expression TutorialDocument3 pages12.2.2.9 Lab - Regular Expression TutorialthiernoPas encore d'évaluation
- Zaki ChahbounDocument10 pagesZaki ChahbounMOHAMED TAMZAITIPas encore d'évaluation
- Thème 2: Internet.: 1961: Naissance Communication Par Paquet 1974: Naissance 1989: Démocratisation D'internet GrâceDocument4 pagesThème 2: Internet.: 1961: Naissance Communication Par Paquet 1974: Naissance 1989: Démocratisation D'internet GrâceManault levacherPas encore d'évaluation
- Con 3Document29 pagesCon 3kakaPas encore d'évaluation
- Telecoms Entreprises - Catalogue Produits Et Services 2014Document35 pagesTelecoms Entreprises - Catalogue Produits Et Services 2014munaimiPas encore d'évaluation
- Cours SDFDocument283 pagesCours SDFsayedms9983Pas encore d'évaluation
- 10 Exemples de SMS Professionnels Que Vos Clients Veulent RecevoirDocument16 pages10 Exemples de SMS Professionnels Que Vos Clients Veulent RecevoirgilmarPas encore d'évaluation
- Comment Accéder Aux Données de Mon Smartphone Si Mon Écran Tactile Est Cassé - Samsung BE - FRDocument4 pagesComment Accéder Aux Données de Mon Smartphone Si Mon Écran Tactile Est Cassé - Samsung BE - FRdgnagbeinfoPas encore d'évaluation
- Installation de Remote Desktop Services (RDS) Sur Windows Server 2012 R2 Et Publication D'une RemoteAppDocument15 pagesInstallation de Remote Desktop Services (RDS) Sur Windows Server 2012 R2 Et Publication D'une RemoteAppAina Tanjona Randriambolarivo100% (1)
- Évaluation: Collège UrsuyaDocument1 pageÉvaluation: Collège UrsuyaDidier TchaleuPas encore d'évaluation
- Virtualisation Asa GuideDocument12 pagesVirtualisation Asa GuideJoel NguinaPas encore d'évaluation
- TRE RS Rep+ & RS Rep-MIA300392-3Document12 pagesTRE RS Rep+ & RS Rep-MIA300392-3Laurent AnabaPas encore d'évaluation
- Logiciel MatérielDocument2 pagesLogiciel MatérielHakim MohamedPas encore d'évaluation
- WMT05 06Document8 pagesWMT05 06Mohamed Anouar BidaPas encore d'évaluation
- MemoireDocument109 pagesMemoirefilalk100% (1)
- Max VolDocument145 pagesMax VolCeren ErgulPas encore d'évaluation
- BIGTREETECH PI4B Adapter V1.0 User Manual FRDocument14 pagesBIGTREETECH PI4B Adapter V1.0 User Manual FRdamienduinoPas encore d'évaluation
- La Navigation InternetDocument9 pagesLa Navigation InternetangaPas encore d'évaluation
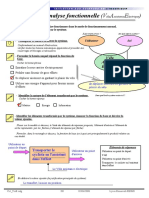
- Analyse Fonctionnelle (V: Vélo Assistance ÉlectriqueDocument6 pagesAnalyse Fonctionnelle (V: Vélo Assistance Électriquesilkbull Iuo-alaPas encore d'évaluation
- Rapport F DfinalDocument95 pagesRapport F Dfinalyassine EssoufiPas encore d'évaluation
- Proposition Devoir PremiereDocument2 pagesProposition Devoir PremiereDiaPas encore d'évaluation
- Présentation Sans TitreDocument2 pagesPrésentation Sans TitreSassi InesPas encore d'évaluation
- ACACEDDocument15 pagesACACEDAlexandra UséPas encore d'évaluation
- Polycopié Réseaux Informatiques CorrigéDocument98 pagesPolycopié Réseaux Informatiques CorrigéZidane TiogoPas encore d'évaluation
- La Perception Du E-Learning Via La Plateforme Moodle Par Les Étudiants de L'université Alger 3 - Cas de La Faculté Des Sciences de L'information Et de La Communication (2020 - 2021)Document13 pagesLa Perception Du E-Learning Via La Plateforme Moodle Par Les Étudiants de L'université Alger 3 - Cas de La Faculté Des Sciences de L'information Et de La Communication (2020 - 2021)Hanane ABDELMALEKPas encore d'évaluation