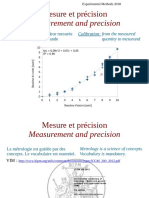
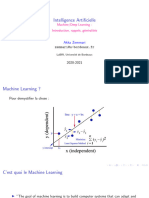
Télécharger au format pdf ou txt
Vous aimerez peut-être aussi
- File Dans Ta Chambre (Caroline Goldman)Document172 pagesFile Dans Ta Chambre (Caroline Goldman)Rayane LaangryPas encore d'évaluation
- Mesures Et IncertitudesDocument4 pagesMesures Et IncertitudesmedwisePas encore d'évaluation
- CancersPaper 14 04399 v23229 2Document16 pagesCancersPaper 14 04399 v23229 2dani demoPas encore d'évaluation
- TP Ndeg1 Mesure Et IncertitudesDocument4 pagesTP Ndeg1 Mesure Et Incertitudesabde rahim haidraPas encore d'évaluation
- ElementsDocument1 pageElementsjpxPas encore d'évaluation
- Mesures Incertitudes PDFDocument7 pagesMesures Incertitudes PDFdhouhaPas encore d'évaluation
- StatistislidesbDocument27 pagesStatistislidesbyan muhalaPas encore d'évaluation
- Cours m1 Econometrie Appliquee Slide2Document34 pagesCours m1 Econometrie Appliquee Slide2ZOUHOUR21Pas encore d'évaluation
- CancersPaper 14 04399 v23229 2Document20 pagesCancersPaper 14 04399 v23229 2dani demoPas encore d'évaluation
- Asset-V1 MinesTelecom+04006+session10+type@asset+block@Télécom FBD S1 AlgèbrePartie1 V2Document15 pagesAsset-V1 MinesTelecom+04006+session10+type@asset+block@Télécom FBD S1 AlgèbrePartie1 V2Younouss KEITAPas encore d'évaluation
- Poly CH 1Document15 pagesPoly CH 1NangaPas encore d'évaluation
- Incertitudes TSDocument6 pagesIncertitudes TSIsmail ait talebPas encore d'évaluation
- Erreurs Et IncertitudesDocument5 pagesErreurs Et Incertitudesعبد الحكيم معيزيةPas encore d'évaluation
- Evaluation Des Modèles de MLDocument32 pagesEvaluation Des Modèles de MLNora HabrichPas encore d'évaluation
- COURS Plan D'experienceDocument19 pagesCOURS Plan D'experienceSafa RejebPas encore d'évaluation
- Cours 1 - Incertitude (1h30) PDFDocument60 pagesCours 1 - Incertitude (1h30) PDFAbdallah SobohPas encore d'évaluation
- Cours MasterDocument55 pagesCours MasterNaim ChPas encore d'évaluation
- Chapitre IDocument7 pagesChapitre Ichouroukbelkacemi236Pas encore d'évaluation
- Cours2 ADDDocument45 pagesCours2 ADDYassine MadaniPas encore d'évaluation
- ST M Explo AfdDocument6 pagesST M Explo AfdSouad BouabanaPas encore d'évaluation
- Polycopie de TP S3 ThermoDocument16 pagesPolycopie de TP S3 Thermoعمر عمري100% (3)
- Survol: Synthèse D'images Outils Mathématiques de BaseDocument7 pagesSurvol: Synthèse D'images Outils Mathématiques de BaseCyrille LamasséPas encore d'évaluation
- Cours Acp HandoutDocument10 pagesCours Acp HandoutMichelPas encore d'évaluation
- Anal-données-M1-CORRELATION ET REGRESSION LINEAIREDocument7 pagesAnal-données-M1-CORRELATION ET REGRESSION LINEAIREPatrice Kengne100% (1)
- Memento Prof MiDocument2 pagesMemento Prof MiLights'artsPas encore d'évaluation
- Labo FrottementDocument5 pagesLabo Frottementandyatt0068Pas encore d'évaluation
- Main MLDocument36 pagesMain MLflav legrand mongouoPas encore d'évaluation
- Cours Biostat Licence Et MasterDocument39 pagesCours Biostat Licence Et Masterfatmaamir878Pas encore d'évaluation
- Chap 3 RégressionDocument17 pagesChap 3 RégressionNadia BeraknaPas encore d'évaluation
- Cours-Resolution SEL-EnS - Info2!23!24 - Version 2Document83 pagesCours-Resolution SEL-EnS - Info2!23!24 - Version 2benjimktPas encore d'évaluation
- Regularized RegressionDocument41 pagesRegularized RegressionOmar BenPas encore d'évaluation
- 4 Chapitre III Statistique Descriptive BivariéeDocument12 pages4 Chapitre III Statistique Descriptive Bivariéehebrimaroua0Pas encore d'évaluation
- Chromatographie CalibrationDocument15 pagesChromatographie CalibrationKhalil OukebdanePas encore d'évaluation
- 1 Mathematiques-BaseDocument15 pages1 Mathematiques-BaseKristmi Gédéon BAMOGOPas encore d'évaluation
- Séance 8 IGF 13 JuinDocument31 pagesSéance 8 IGF 13 JuinSalah DahbiPas encore d'évaluation
- AM RadiobioDocument15 pagesAM Radiobiotiravi1249Pas encore d'évaluation
- TP2 Régression Linéaire MultipleDocument2 pagesTP2 Régression Linéaire Multiplemathieut157Pas encore d'évaluation
- Incertitude Et Logiciel GUM (MPRN)Document8 pagesIncertitude Et Logiciel GUM (MPRN)sofianesedkaouiPas encore d'évaluation
- Anova One Way (L3) Support de Cours Détaillé (Fevrier 2024)Document13 pagesAnova One Way (L3) Support de Cours Détaillé (Fevrier 2024)lynasamaPas encore d'évaluation
- Klubprepa 4790 PDFDocument2 pagesKlubprepa 4790 PDFdamino32Pas encore d'évaluation
- Stats - RésuméDocument8 pagesStats - Résuméyessminchaabouni5Pas encore d'évaluation
- 7 Tests 2016Document17 pages7 Tests 2016beday27725Pas encore d'évaluation
- Fiche Synthèse Sur La Régression Linéaire MultipleDocument1 pageFiche Synthèse Sur La Régression Linéaire MultipleAchrafOuinouPas encore d'évaluation
- Torseur Action MecaniqueDocument8 pagesTorseur Action MecaniqueMaha Karray100% (1)
- EJAYDocument24 pagesEJAYromuald calpasPas encore d'évaluation
- Chapitre2 - Statistique Descriptive À Une VariableDocument22 pagesChapitre2 - Statistique Descriptive À Une VariablebayePas encore d'évaluation
- Data ScienceDocument8 pagesData SciencemielledavPas encore d'évaluation
- Chapitre. Régression Linéaire Simple - 19-20 - Part01Document10 pagesChapitre. Régression Linéaire Simple - 19-20 - Part01Kamilia bouhraouaPas encore d'évaluation
- Chapitre. Régression Linéaire Simple - 19-20 - Part01 PDFDocument10 pagesChapitre. Régression Linéaire Simple - 19-20 - Part01 PDFKamilia bouhraouaPas encore d'évaluation
- S1 Modelisation RLDocument20 pagesS1 Modelisation RLAmine ChettatPas encore d'évaluation
- Cours Introduction À L'econométrieDocument95 pagesCours Introduction À L'econométriegondodiesamesperancePas encore d'évaluation
- Partie 1 - Chap 1 - de Mécanique Rationnelle-S1-TennougaL - CopieDocument20 pagesPartie 1 - Chap 1 - de Mécanique Rationnelle-S1-TennougaL - CopieRezig Ahmed KhodhirPas encore d'évaluation
- CHP0 - Partie 02Document9 pagesCHP0 - Partie 02refran daliaPas encore d'évaluation
- Formules Statistique UnivarieeDocument2 pagesFormules Statistique UnivarieeAce100% (1)
- Examenblanc PDFDocument7 pagesExamenblanc PDFabousalimPas encore d'évaluation
- Lois de Newton Resume de Cours 1 1Document3 pagesLois de Newton Resume de Cours 1 1motatata231Pas encore d'évaluation
- TP 1 Mesures Et IncertitudesDocument4 pagesTP 1 Mesures Et Incertitudesdalia aliasPas encore d'évaluation
- Complément Chapitre II - Calcul de La Médiane Et Les Quantiles - Cas Discret Et ContinuDocument43 pagesComplément Chapitre II - Calcul de La Médiane Et Les Quantiles - Cas Discret Et ContinuBlackstarr 547Pas encore d'évaluation
- Régression Linéaire Simple Et MultipleDocument13 pagesRégression Linéaire Simple Et MultipleOlivier TaonsaPas encore d'évaluation
- Français Première Année SecondaireDocument7 pagesFrançais Première Année SecondaireFrantzxo BonhommePas encore d'évaluation
- Prepa G2Document5 pagesPrepa G2bayilisamuel01Pas encore d'évaluation
- La Coordination Par Jean LoubatDocument13 pagesLa Coordination Par Jean LoubatdjelvrPas encore d'évaluation
- Republique Democratique Du CongoDocument1 pageRepublique Democratique Du CongoIsraël Ready Mabiala100% (1)
- Mettre en Place Un Outil de VeilleDocument6 pagesMettre en Place Un Outil de Veillehansi.pelikanPas encore d'évaluation
- Maarch Framework Tests ChargeDocument11 pagesMaarch Framework Tests ChargeicarobluePas encore d'évaluation
- 06 17 Rapport de Stage en Psychologie Maroiane HAOUIDEGDocument44 pages06 17 Rapport de Stage en Psychologie Maroiane HAOUIDEGultrazartrexPas encore d'évaluation
- DCICN Formation Introduction Aux Reseaux Data Center Cisco PDFDocument2 pagesDCICN Formation Introduction Aux Reseaux Data Center Cisco PDFCertyouFormationPas encore d'évaluation
- Cours-Systeme D Exploitation SeDocument50 pagesCours-Systeme D Exploitation SemahrazaekPas encore d'évaluation
- Formulaire M1 - 10-11Document6 pagesFormulaire M1 - 10-11blueskyedPas encore d'évaluation
- ViergeDocument1 pageViergeGode-junior YeyePas encore d'évaluation
- ENSEIGNEMENT - Une Crise Planétaire de L'éducation - Courrier InternationalDocument7 pagesENSEIGNEMENT - Une Crise Planétaire de L'éducation - Courrier InternationalAnonymous TPeTdS430% (1)
- 13 - Le Mental Du ChampionDocument5 pages13 - Le Mental Du Championalain kouassi100% (1)
- Autocad 2012 ProductDocument4 pagesAutocad 2012 ProductRobobatMaroc2012Pas encore d'évaluation
- Réglement Des Etudes Master 2020 - 2021 - VotéDocument10 pagesRéglement Des Etudes Master 2020 - 2021 - VotéYassine SaddikiPas encore d'évaluation
- LivreDocument71 pagesLivrecxxxPas encore d'évaluation
- Dev N°2 SBTFa CouDocument2 pagesDev N°2 SBTFa CouOumar TraoréPas encore d'évaluation
- Rapport D'activités 2015 - Fondation Pour La Mémoire de La ShoahDocument56 pagesRapport D'activités 2015 - Fondation Pour La Mémoire de La ShoahFondation pour la Mémoire de la Shoah100% (1)
- Autorité Nationale D'Assurance Qualité de L'Enseignement SupérieurDocument22 pagesAutorité Nationale D'Assurance Qualité de L'Enseignement SupérieurCOOPASIV TOGOPas encore d'évaluation
- Syllabus Cours Culture Entrepreneuriat - LP1Document2 pagesSyllabus Cours Culture Entrepreneuriat - LP1Yasmine SolenePas encore d'évaluation
- Programme Laboratoire - Physique - Cours (2017-01-D-72-fr-3)Document11 pagesProgramme Laboratoire - Physique - Cours (2017-01-D-72-fr-3)Barthélemy HoubenPas encore d'évaluation
- مصادر المعلومات الالكترونية المتاحة عن بعد في الاستشها... ال... تحليلية لعينة من مذكرات الماستر بقسم علوم التربية جامعة قسنطينة.Document8 pagesمصادر المعلومات الالكترونية المتاحة عن بعد في الاستشها... ال... تحليلية لعينة من مذكرات الماستر بقسم علوم التربية جامعة قسنطينة.Golden RosePas encore d'évaluation