Vous aimerez peut-être aussi
- Corrigé de La Série 2 - SimulationDocument14 pagesCorrigé de La Série 2 - SimulationAnisPas encore d'évaluation
- Ca 4 PDFDocument23 pagesCa 4 PDFmohamedPas encore d'évaluation
- Microéconomie L2 AES Semestre 2Document17 pagesMicroéconomie L2 AES Semestre 2ARatfatPas encore d'évaluation
- sujetTP1 PDFDocument2 pagessujetTP1 PDFAdil AbouelhassanPas encore d'évaluation
- TD 3 SupDocument4 pagesTD 3 SupWiem MelkiPas encore d'évaluation
- Application Variable ContinueDocument2 pagesApplication Variable ContinueDavila AlomgbaPas encore d'évaluation
- Analyse Mathématique Corrigé Série 3Document5 pagesAnalyse Mathématique Corrigé Série 3aden.91Pas encore d'évaluation
- ProgrammationLineaire PDFDocument59 pagesProgrammationLineaire PDFAbed NegoPas encore d'évaluation
- 8 Variable Aléatoire ContinueDocument3 pages8 Variable Aléatoire Continuelvtmath100% (1)
- Chapitre 3 - Intérêts Simples Et ComposésDocument25 pagesChapitre 3 - Intérêts Simples Et ComposésSamuelPas encore d'évaluation
- Corrige Maths Cnaem 2014Document12 pagesCorrige Maths Cnaem 2014taoufik mabrour50% (2)
- Fiche 1Document5 pagesFiche 1othman okPas encore d'évaluation
- Lois Discretes Et ContinuesDocument36 pagesLois Discretes Et ContinuesShamir ganamaPas encore d'évaluation
- TD Suite Numérique - 2Document16 pagesTD Suite Numérique - 2nour1960100% (1)
- Solutions Des Exercices Chapitre EstimationsDocument18 pagesSolutions Des Exercices Chapitre EstimationsSimo MnhPas encore d'évaluation
- Etud Chap 2 P1 Microéconomie de LincertainDocument13 pagesEtud Chap 2 P1 Microéconomie de Lincertainchiraz bekirPas encore d'évaluation
- Exercice N°4-CorrDocument5 pagesExercice N°4-CorrPFEPas encore d'évaluation
- Examen ProbabilitéDocument3 pagesExamen ProbabilitéKael LasriPas encore d'évaluation
- TD3 CorrDocument4 pagesTD3 CorrImane KhaliPas encore d'évaluation
- Exam Master 1213Document2 pagesExam Master 1213stevy darelPas encore d'évaluation
- Theorie TestsDocument17 pagesTheorie TestsblazardPas encore d'évaluation
- ProbabiliteDocument8 pagesProbabiliteMichel MerdiPas encore d'évaluation
- Probabilite1 PrepaDocument39 pagesProbabilite1 PrepaDavid BAWAPas encore d'évaluation
- 4 Forme Extensive ArticleDocument19 pages4 Forme Extensive ArticleEunockPas encore d'évaluation
- Corrige 4Document4 pagesCorrige 4yves1ndriPas encore d'évaluation
- Variable Aleatoire ContinueDocument9 pagesVariable Aleatoire ContinueSkander GuitouniPas encore d'évaluation
- TP1Document3 pagesTP1Chatiri AzizPas encore d'évaluation
- Tp-Estimateur Du Maximum de Vraisemblance-Cor - CopieDocument5 pagesTp-Estimateur Du Maximum de Vraisemblance-Cor - CopieCharo Cass100% (1)
- Support ProbabilitéDocument38 pagesSupport ProbabilitéYasser KaztiPas encore d'évaluation
- Deter Min Ante NoDocument5 pagesDeter Min Ante NoJalal AlouiatPas encore d'évaluation
- TD3 Chapitre3 Echantillonnage Et Estimation - CompressedDocument11 pagesTD3 Chapitre3 Echantillonnage Et Estimation - CompressedJamila ridaPas encore d'évaluation
- ExOpti CorrectionDocument13 pagesExOpti CorrectionAnthony ChristianPas encore d'évaluation
- Exercice 1: Travail À FaireDocument18 pagesExercice 1: Travail À FaireAbdennour KhadijaPas encore d'évaluation
- exosPL Foad4c-1Document6 pagesexosPL Foad4c-1Septimus PierrePas encore d'évaluation
- Fiche No2 AAlgorithme SimplexeDocument5 pagesFiche No2 AAlgorithme SimplexeFabrice FotsoPas encore d'évaluation
- Exercice 6Document4 pagesExercice 6Amel Elfirjani100% (1)
- Analyse Mathématique Corrigé Série 2Document8 pagesAnalyse Mathématique Corrigé Série 2aden.91Pas encore d'évaluation
- ExerciceDocument6 pagesExerciceMoad EddalossPas encore d'évaluation
- Cours9 AlgoDocument10 pagesCours9 Algocribble09Pas encore d'évaluation
- TD Statistiques Appliquées (S5) - Série 1 Exercice 1:: Ecole Nationale de Commerce Et de GestionDocument5 pagesTD Statistiques Appliquées (S5) - Série 1 Exercice 1:: Ecole Nationale de Commerce Et de GestionYasserPas encore d'évaluation
- ProbabilitéDocument22 pagesProbabilitéayoubbbbPas encore d'évaluation
- Exercices Corrigés - Marches AléatoiresDocument14 pagesExercices Corrigés - Marches AléatoiresyaudasPas encore d'évaluation
- INTERET Chap23Document23 pagesINTERET Chap23Euloge EhoussouPas encore d'évaluation
- ExosDocument22 pagesExosmourad24000100% (2)
- Corrigé Du TD #2Document2 pagesCorrigé Du TD #2SAFO100% (1)
- Partiel L2 Séries Intégrations 2006 2Document2 pagesPartiel L2 Séries Intégrations 2006 2R-winPas encore d'évaluation
- Recherche Operationnelle S7 Corrige TD1Document6 pagesRecherche Operationnelle S7 Corrige TD1ELETRIPas encore d'évaluation
- Variables Aleatoires Continues TDDocument6 pagesVariables Aleatoires Continues TDjoséphin sylvèrePas encore d'évaluation
- TD1 RO2022 Corrig éDocument27 pagesTD1 RO2022 Corrig éReda HamlyPas encore d'évaluation
- Correction Stat 20102011Document9 pagesCorrection Stat 20102011Dony KravitzPas encore d'évaluation
- La théorie des jeux: Thrillers judiciaires de Katerina Carter, #2D'EverandLa théorie des jeux: Thrillers judiciaires de Katerina Carter, #2Pas encore d'évaluation
- Aspects fiscaux de la comptabilité et technique de déclaration fiscaleD'EverandAspects fiscaux de la comptabilité et technique de déclaration fiscaleÉvaluation : 5 sur 5 étoiles5/5 (1)
- BudgetDocument4 pagesBudgetMohammed berkaniPas encore d'évaluation
- Analyse FinDocument95 pagesAnalyse FinMohammed berkaniPas encore d'évaluation
- Comptabilité GénéraleDocument60 pagesComptabilité GénéraleMohammed berkaniPas encore d'évaluation
- Catalogue ProbDocument4 pagesCatalogue ProbMohammed berkaniPas encore d'évaluation
- Activités QCM: Said, El MelhaouiDocument9 pagesActivités QCM: Said, El MelhaouiMohammed berkaniPas encore d'évaluation
- Catalogue ProbDocument4 pagesCatalogue ProbMohammed berkaniPas encore d'évaluation
- NormalisationDocument32 pagesNormalisationZinelabedine OulimePas encore d'évaluation
- Réseau de PÉTRIDocument10 pagesRéseau de PÉTRIBaugram RudyPas encore d'évaluation
- Chapitre 2 Transformé de LaplaceDocument27 pagesChapitre 2 Transformé de LaplaceYounouss KEITAPas encore d'évaluation
- Partie I. Arithmétique Des Entiers de GaussDocument6 pagesPartie I. Arithmétique Des Entiers de GaussMohamed Ali EchPas encore d'évaluation
- 2.1.-Corrige ds2Document3 pages2.1.-Corrige ds2Eduardo Gindel LadowskiPas encore d'évaluation
- TD LCD 2024Document5 pagesTD LCD 2024ady thiamPas encore d'évaluation
- Série N°2 OnlDocument2 pagesSérie N°2 Onlnihad snPas encore d'évaluation
- Projet Analyse NumériqueDocument1 pageProjet Analyse NumériqueMarc MarinPas encore d'évaluation
- CSI4Document6 pagesCSI4Abdoul Latif SinonPas encore d'évaluation
- Maxima PMA12Document4 pagesMaxima PMA12RuffucePas encore d'évaluation
- Présenter Le Problème Sac ÀdosDocument4 pagesPrésenter Le Problème Sac ÀdosWifek OUERGHEMMIPas encore d'évaluation
- Equiv Normes PDFDocument2 pagesEquiv Normes PDFABDELKADERPas encore d'évaluation
- Généralités Sur Les Fonctions 3ème Mathématiques PDFDocument5 pagesGénéralités Sur Les Fonctions 3ème Mathématiques PDFANDRIANJAFYPas encore d'évaluation
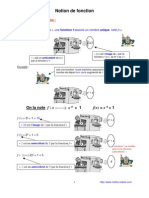
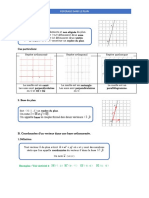
- Notion de Fonction (3ème)Document3 pagesNotion de Fonction (3ème)MATHS - VIDEOSPas encore d'évaluation
- IntroductionDocument16 pagesIntroductiontakichelseaPas encore d'évaluation
- Maths Second Cycle PDFDocument27 pagesMaths Second Cycle PDFCrédit Finance PlusPas encore d'évaluation
- Espaces MétriquesDocument9 pagesEspaces MétriquesJonas MbengPas encore d'évaluation
- @Ânîšbìíü@Óüa at @ Exercice (1) ÆDocument3 pages@Ânîšbìíü@Óüa at @ Exercice (1) ÆTANITOSPas encore d'évaluation
- Problemes D Analyse 2Document389 pagesProblemes D Analyse 2ناوي خزيت100% (3)
- 6 Applications LinéairesDocument17 pages6 Applications LinéairesYoussef El FahimePas encore d'évaluation
- Série 2 Solution Corrélation ConvolutionDocument6 pagesSérie 2 Solution Corrélation ConvolutionKorichi OmarPas encore d'évaluation
- Series TD 2014 2015Document7 pagesSeries TD 2014 2015fad hmaPas encore d'évaluation
- 3Ms An 8 PDFDocument16 pages3Ms An 8 PDFalan muzanPas encore d'évaluation
- DS 6 SupDocument2 pagesDS 6 SupSara MarouchePas encore d'évaluation
- Cours Repérage Dans Le PlanDocument3 pagesCours Repérage Dans Le Planalh bljPas encore d'évaluation
- Mstsexp 2020 Reedition2021 Version ImprimeurDocument256 pagesMstsexp 2020 Reedition2021 Version Imprimeurana100% (2)
- TD 1 Geodiff 2023 2024Document2 pagesTD 1 Geodiff 2023 2024ebenezer n'goranPas encore d'évaluation
- Resume Cours Chitour Septembre 2018 Semi-GroupesDocument10 pagesResume Cours Chitour Septembre 2018 Semi-Groupesrabah100% (2)
- 1sex G Fonction Cour PDFDocument26 pages1sex G Fonction Cour PDFSimoMonkad100% (1)
- Fractions Cours de Maths en 6eme 678Document4 pagesFractions Cours de Maths en 6eme 678e2342062Pas encore d'évaluation