Vous aimerez peut-être aussi
- Pf00cours Texte XXXDocument22 pagesPf00cours Texte XXXXxxxxxxxxwPas encore d'évaluation
- Apprentissage de Dictionnaire Sur Les Images - Application À La Détection D'anomaliesDocument43 pagesApprentissage de Dictionnaire Sur Les Images - Application À La Détection D'anomaliesSam PerochonPas encore d'évaluation
- Traité d'économétrie financière: Modélisation financièreD'EverandTraité d'économétrie financière: Modélisation financièrePas encore d'évaluation
- ArithmetiqueDocument61 pagesArithmetiquehousseinePas encore d'évaluation
- Cours de Stat InferentiellesDocument65 pagesCours de Stat InferentiellesDuy An100% (1)
- Fonctions Numériques: Continuité, Limites, Dérivation, Fonctions ClassiquesDocument14 pagesFonctions Numériques: Continuité, Limites, Dérivation, Fonctions ClassiquesThiago LukusaPas encore d'évaluation
- Cours Proc AléatoireDocument73 pagesCours Proc AléatoireMennad MennadPas encore d'évaluation
- Cours Optim NLDocument69 pagesCours Optim NLHajar BensahlPas encore d'évaluation
- TDStat L3 MHDocument21 pagesTDStat L3 MHMikhael QUENUMPas encore d'évaluation
- Cours Probabilite Et Statistique SMC s4 Faculte Des Science France 1-1Document150 pagesCours Probabilite Et Statistique SMC s4 Faculte Des Science France 1-1blaksitoPas encore d'évaluation
- Cours Methodes D'Approximation Des Equations Aux Derivees Partielles Par Differences Finies Et Volumes FinisDocument47 pagesCours Methodes D'Approximation Des Equations Aux Derivees Partielles Par Differences Finies Et Volumes FinisTâm ĐàoPas encore d'évaluation
- Calcul Différentiel (UPS)Document22 pagesCalcul Différentiel (UPS)Adrien RouvierePas encore d'évaluation
- E de Cours: Statistique Pour L'economieDocument27 pagesE de Cours: Statistique Pour L'economieantoine moryPas encore d'évaluation
- GLM EuriaDocument49 pagesGLM EuriaMrabti RimePas encore d'évaluation
- Aide Multicritère A La DécisionDocument20 pagesAide Multicritère A La DécisionpierrePas encore d'évaluation
- Cours de Maths Semestre 1Document41 pagesCours de Maths Semestre 1mbnlleilaPas encore d'évaluation
- Révision Echantillonnage Estimation TestDocument16 pagesRévision Echantillonnage Estimation TestMustapha ZettifPas encore d'évaluation
- Cours Monte CarloDocument30 pagesCours Monte CarloGoya Alama Désiré DaoPas encore d'évaluation
- TP Masse RessortDocument6 pagesTP Masse RessortFATIMA ZAHRA SAIHPas encore d'évaluation
- Harmo (1) - Differences-Finies-Et-Analyse-Numerique-MatricielleDocument52 pagesHarmo (1) - Differences-Finies-Et-Analyse-Numerique-Matriciellestephanie andriamanalinaPas encore d'évaluation
- CM de Statistique 2015Document26 pagesCM de Statistique 2015Toure100% (1)
- Les Entiers Naturels (Alain Prouté) PDFDocument12 pagesLes Entiers Naturels (Alain Prouté) PDFGillian SeedPas encore d'évaluation
- IN101 Poly AlgoDocument124 pagesIN101 Poly AlgoSakhr TantaouiPas encore d'évaluation
- Ahmed WARSSADocument31 pagesAhmed WARSSAmorabitifaiza55Pas encore d'évaluation
- Cours LAT-324 L3-TELECOMDocument26 pagesCours LAT-324 L3-TELECOMMinou LuchianoPas encore d'évaluation
- Tables RessourcesDocument27 pagesTables RessourcesdcanabalgPas encore d'évaluation
- Fascicule Exercices GesEnt 22-23Document79 pagesFascicule Exercices GesEnt 22-23Lieve EmielPas encore d'évaluation
- Cours Calc Diff 2020 2021 1Document48 pagesCours Calc Diff 2020 2021 1med elhaddadPas encore d'évaluation
- Stat ExploDocument73 pagesStat ExploMohamed RdaitPas encore d'évaluation
- Cours de Mathématiques Pour La Terminale SDocument50 pagesCours de Mathématiques Pour La Terminale SMarco PoloPas encore d'évaluation
- Ana - Dans R - N - 2022-2023Document39 pagesAna - Dans R - N - 2022-2023Arsène KekpenaPas encore d'évaluation
- coursRN EDO19 20Document19 pagescoursRN EDO19 20Wiamae23Pas encore d'évaluation
- Cours ProbaDocument60 pagesCours ProbabounchichyPas encore d'évaluation
- Cours Estimation Et EchantillonnageDocument36 pagesCours Estimation Et EchantillonnageChaymæ AdmirPas encore d'évaluation
- Ana 1Document37 pagesAna 1aliturkiPas encore d'évaluation
- 2nde CoursDocument97 pages2nde CoursamadeusPas encore d'évaluation
- Tables 1Document27 pagesTables 1Badrane Taleb AliPas encore d'évaluation
- CH Calcul DiffDocument18 pagesCH Calcul DiffChota ChrifPas encore d'évaluation
- Biostatistiques Rappels de Cours Et Travaux DirigésDocument26 pagesBiostatistiques Rappels de Cours Et Travaux DirigésYatie Mamadou DAYOPas encore d'évaluation
- Examens TDS, TPs Et CorrigésDocument90 pagesExamens TDS, TPs Et CorrigésSlimani AhmedPas encore d'évaluation
- Cours ElliptiqueDocument67 pagesCours ElliptiqueSèíf KâdŕïPas encore d'évaluation
- Statistique DescriptiveDocument34 pagesStatistique DescriptiveAbdessamad BoulhdoubPas encore d'évaluation
- Lois UsuellesDocument15 pagesLois UsuellesPerrait DjiPas encore d'évaluation
- Cours DistributionsDocument51 pagesCours DistributionsAmadou LYPas encore d'évaluation
- 27 Matrices ChapitreDocument23 pages27 Matrices ChapitreOussama McPas encore d'évaluation
- 09 Cours Statistiques Pourcentages ProbabiliteDocument19 pages09 Cours Statistiques Pourcentages ProbabiliteOtmane LhmPas encore d'évaluation
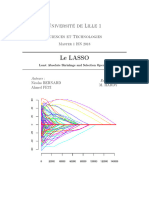
- Lasso 2Document66 pagesLasso 2ABDELLAH QANNARIPas encore d'évaluation
- Poly Cop I Analyse 04Document100 pagesPoly Cop I Analyse 04Tahirou FanePas encore d'évaluation
- StochastiqueDocument74 pagesStochastiqueSouid GhadaPas encore d'évaluation
- Copie de Cours-RO-VF PDFDocument23 pagesCopie de Cours-RO-VF PDFEnocksonPas encore d'évaluation
- Cours GalerneDocument38 pagesCours GalerneQu CPas encore d'évaluation
- Cours Optim M1SAFDocument65 pagesCours Optim M1SAFHamouda AzzouzPas encore d'évaluation
- Manuel Tab Freq GL MDocument282 pagesManuel Tab Freq GL MNathanaël Lenny Ahsan Vladislav BenjaminPas encore d'évaluation
- S Erie N 1 D' Echantillonnage Et EstimationDocument5 pagesS Erie N 1 D' Echantillonnage Et EstimationOtmane AbouriPas encore d'évaluation
- Cours Calcul IntegralDocument12 pagesCours Calcul IntegralYves AbrahamPas encore d'évaluation
- Sci1018 l5 TheorieDocument24 pagesSci1018 l5 TheorieEzekiel TakaPas encore d'évaluation
- Poly TP TS 16 17Document15 pagesPoly TP TS 16 17Ayoub Elfarwah0% (1)
- Cours Statistique MR - El Haddaoui 21-22Document33 pagesCours Statistique MR - El Haddaoui 21-22abraham LincolnPas encore d'évaluation
- Leçon N°9 - Les Coûts Variables Et Le Seuil de RentabilitéDocument9 pagesLeçon N°9 - Les Coûts Variables Et Le Seuil de RentabilitéZury84Pas encore d'évaluation
- Cours de Digital Control SystemsDocument172 pagesCours de Digital Control SystemsarcPas encore d'évaluation
- Cas Pratique 1 Final - ÉnoncéDocument6 pagesCas Pratique 1 Final - ÉnoncéAmina KirechePas encore d'évaluation
- Master TOX1 PDFDocument17 pagesMaster TOX1 PDFSidahmed MilPas encore d'évaluation
- Chapitre 1Document31 pagesChapitre 1Chahid ChokoutPas encore d'évaluation
- DEPLIANT 16e SOCAPED COMPLET 02092022Document4 pagesDEPLIANT 16e SOCAPED COMPLET 02092022SamuelPas encore d'évaluation
- PDFDocument137 pagesPDFMETAHRI DhiyaeddinePas encore d'évaluation
- Guide Juridique PDFDocument754 pagesGuide Juridique PDFMariem AssafiPas encore d'évaluation
- Le Guide de La Gestion de CriseDocument17 pagesLe Guide de La Gestion de CriseThierry KOUAME100% (3)
- Crédit ManagementDocument25 pagesCrédit Managementjosuedassi1Pas encore d'évaluation
- Systeme 2DDLDocument25 pagesSysteme 2DDLSamado Tips46Pas encore d'évaluation
- Dqe Hangar 24X40 Poteaux MetalliquesDocument2 pagesDqe Hangar 24X40 Poteaux MetalliquesorianeruthdPas encore d'évaluation
- Guide de Massage Lomi-LomiDocument3 pagesGuide de Massage Lomi-Lomibittencourt.caroline108Pas encore d'évaluation
- Vini Oral BTSDocument14 pagesVini Oral BTSheiariiverPas encore d'évaluation
- LeFa, GéomancieAfricainePDF 1712184199545Document37 pagesLeFa, GéomancieAfricainePDF 1712184199545Bachir Maman MoustaphaPas encore d'évaluation
- Krigeage DualDocument5 pagesKrigeage DualkaderPas encore d'évaluation
- Pdfnotice 65409Document32 pagesPdfnotice 65409Michel MunozPas encore d'évaluation
- Réflexion Et Réfraction Notions À RetenirDocument14 pagesRéflexion Et Réfraction Notions À Retenirsarra takfaouiPas encore d'évaluation
- Naples BOUCHIBA Farid Ibadism Napoli 1Document32 pagesNaples BOUCHIBA Farid Ibadism Napoli 1Ayman UchihaPas encore d'évaluation
- TP N°1Document4 pagesTP N°1Marouane TaibiniPas encore d'évaluation
- GRAM Mardi 31 COD COI Et Pronoms Perso Compléments ConvertiDocument2 pagesGRAM Mardi 31 COD COI Et Pronoms Perso Compléments ConvertiAbanoubPas encore d'évaluation
- Anatomie de L'oesophageDocument26 pagesAnatomie de L'oesophageilham bzikha33% (3)
- CE1 Anglais Lets Travel To Australia CompressedDocument11 pagesCE1 Anglais Lets Travel To Australia CompressedFifi liloPas encore d'évaluation
- Méthode de Commentaire de Texte PhilosophiqueDocument7 pagesMéthode de Commentaire de Texte PhilosophiqueDaniel Stain Ferreira100% (2)
- Contrat Type PPPDocument69 pagesContrat Type PPPDecour Paul-JeanPas encore d'évaluation
- Cook Expert Magimix 10 RecettesDocument20 pagesCook Expert Magimix 10 RecettesdilonPas encore d'évaluation
- Evaluation SommativeDocument14 pagesEvaluation SommativeAnonymous wzl1VpDoz6Pas encore d'évaluation
- Nat PatDocument9 pagesNat PatMedvall Ould Med YehdhihPas encore d'évaluation
- Delonghi Ec695Document18 pagesDelonghi Ec695Kaddouri KaddaPas encore d'évaluation
- Sanda Rituels de Gurison Par Les Archanges PDFDocument23 pagesSanda Rituels de Gurison Par Les Archanges PDFEric MerlinPas encore d'évaluation
- Géobiologie de l'habitat et Géobiologie sacrée: Pour un lieu sainD'EverandGéobiologie de l'habitat et Géobiologie sacrée: Pour un lieu sainÉvaluation : 4.5 sur 5 étoiles4.5/5 (2)
- Je me prépare aux examens du ministère en mathématiques: Es-tu prêt à passer le test ?D'EverandJe me prépare aux examens du ministère en mathématiques: Es-tu prêt à passer le test ?Évaluation : 4 sur 5 étoiles4/5 (1)
- Neuropsychologie: Les bases théoriques et pratiques du domaine d'étude (psychologie pour tous)D'EverandNeuropsychologie: Les bases théoriques et pratiques du domaine d'étude (psychologie pour tous)Pas encore d'évaluation
- Le fa, entre croyances et science: Pour une epistemologie des savoirs africainsD'EverandLe fa, entre croyances et science: Pour une epistemologie des savoirs africainsÉvaluation : 3.5 sur 5 étoiles3.5/5 (6)
- Les 10 Secrets pour une Vie Plus Heureuse avec la Maladie de ParkinsonD'EverandLes 10 Secrets pour une Vie Plus Heureuse avec la Maladie de ParkinsonPas encore d'évaluation
- Histoire de la psychologie scientifique: De la naissance de la psychologie à la neuropsychologie et aux champs d'application les plus actuelsD'EverandHistoire de la psychologie scientifique: De la naissance de la psychologie à la neuropsychologie et aux champs d'application les plus actuelsPas encore d'évaluation
- Comment développer l’autodiscipline: Résiste aux tentations et atteins tes objectifs à long termeD'EverandComment développer l’autodiscipline: Résiste aux tentations et atteins tes objectifs à long termeÉvaluation : 4.5 sur 5 étoiles4.5/5 (7)
- Encyclopédie de la thérapie par ventouses : Une nouvelle éditionD'EverandEncyclopédie de la thérapie par ventouses : Une nouvelle éditionPas encore d'évaluation
- L'Ombre à l'Univers: La structure des particules élémentaires XIIfD'EverandL'Ombre à l'Univers: La structure des particules élémentaires XIIfPas encore d'évaluation
- Les defis du developpement local au SenegalD'EverandLes defis du developpement local au SenegalÉvaluation : 2 sur 5 étoiles2/5 (1)
- Un régime quantiqueD'EverandUn régime quantiqueÉvaluation : 5 sur 5 étoiles5/5 (1)
- Cabot-Caboche de Daniel Pennac: Questionnaire de lectureD'EverandCabot-Caboche de Daniel Pennac: Questionnaire de lecturePas encore d'évaluation
- Mathématiques et Mathématiciens Pensées et CuriositésD'EverandMathématiques et Mathématiciens Pensées et CuriositésÉvaluation : 4.5 sur 5 étoiles4.5/5 (5)
- le Phoenix de nos âmes: Les lois énergétiques de la lumière divineD'Everandle Phoenix de nos âmes: Les lois énergétiques de la lumière divinePas encore d'évaluation
- Comment penser à l'intérieur de la boîte: FormidablesD'EverandComment penser à l'intérieur de la boîte: FormidablesPas encore d'évaluation
- Les personnalités les plus productives de l'HistoireD'EverandLes personnalités les plus productives de l'HistoireÉvaluation : 4.5 sur 5 étoiles4.5/5 (2)
- Maison Intelligente: Conception et réalisation d'une maison intelligenteD'EverandMaison Intelligente: Conception et réalisation d'une maison intelligenteÉvaluation : 4 sur 5 étoiles4/5 (5)
- Voyager à Travers les Mondes Parallèles pour Atteindre vos RêvesD'EverandVoyager à Travers les Mondes Parallèles pour Atteindre vos RêvesÉvaluation : 4 sur 5 étoiles4/5 (11)