Vous aimerez peut-être aussi
- TP UltrasonDocument8 pagesTP UltrasonZaki ZaidiPas encore d'évaluation
- Chapitre 1 - Eléments de Machines ElectriquesDocument31 pagesChapitre 1 - Eléments de Machines ElectriquesInsafe Aarab100% (1)
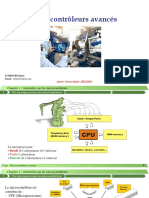
- Cours Microcontrôleurs 1ère Année 21Document171 pagesCours Microcontrôleurs 1ère Année 21haitam lfridiPas encore d'évaluation
- Cours UC 1èrea2022Document185 pagesCours UC 1èrea2022haitam lfridiPas encore d'évaluation
- Cours Microcontrôleur Microprocesseur 47Document31 pagesCours Microcontrôleur Microprocesseur 47LAHOUSSINE ELMAHNIPas encore d'évaluation
- PIC16F84Document22 pagesPIC16F84Rida bellarranePas encore d'évaluation
- Histoire de MicroprocesseurDocument18 pagesHistoire de Microprocesseurbenhamzaikram2318Pas encore d'évaluation
- Cours Microcontrôleur Microprocesseur 51Document18 pagesCours Microcontrôleur Microprocesseur 51NasriMohsenPas encore d'évaluation
- Coursmicro 05 12 2004id027 PDFDocument167 pagesCoursmicro 05 12 2004id027 PDFAnas KâPas encore d'évaluation
- Process EurDocument15 pagesProcess EurGanesh PaulPas encore d'évaluation
- Cours Microcontrôleur Microprocesseur 23Document51 pagesCours Microcontrôleur Microprocesseur 23karima seghaierPas encore d'évaluation
- Microprocesseurs ATMEL Part1Document10 pagesMicroprocesseurs ATMEL Part1Mustapha ramziPas encore d'évaluation
- Cours Microcontrôleur Microprocesseur 19Document15 pagesCours Microcontrôleur Microprocesseur 19Med EL JaouhariPas encore d'évaluation
- Cours Architecture CompletDocument176 pagesCours Architecture CompletAya MkPas encore d'évaluation
- MICRODocument4 pagesMICROWalter FopaPas encore d'évaluation
- Pic16f877 150125131206 Conversion Gate01Document44 pagesPic16f877 150125131206 Conversion Gate01Harzly HajerPas encore d'évaluation
- Cours MicrocontrrolleurDocument65 pagesCours MicrocontrrolleurAngélica DEKEPas encore d'évaluation
- Cours Microcontrôleur Microprocesseur 50Document25 pagesCours Microcontrôleur Microprocesseur 50ouahabPas encore d'évaluation
- Leçon N°1: Presentation de L'Informatique Industrielle Et Des Systemes Micro-Programmes I - L'Informatique IndustrielleDocument120 pagesLeçon N°1: Presentation de L'Informatique Industrielle Et Des Systemes Micro-Programmes I - L'Informatique IndustrielleFulbert FissouPas encore d'évaluation
- C1 Arm7Document19 pagesC1 Arm7Nacim AguenarousPas encore d'évaluation
- COURS ARPA Chap1 3Document6 pagesCOURS ARPA Chap1 3moudouPas encore d'évaluation
- VHDL ProcesseurDocument21 pagesVHDL ProcesseurchaoukiPas encore d'évaluation
- Chapitre 2 Systemes A Base de Microprocesseurs - C2I2S - S1Document29 pagesChapitre 2 Systemes A Base de Microprocesseurs - C2I2S - S1Karym ElhoussinePas encore d'évaluation
- Chapitre II Architecture Générale D Un MicrocontroleurDocument22 pagesChapitre II Architecture Générale D Un Microcontroleurfou100% (1)
- Architecture Et Segmentation Mémoire Du 80286Document39 pagesArchitecture Et Segmentation Mémoire Du 80286the dawgPas encore d'évaluation
- Microcontroeluers AvancésDocument83 pagesMicrocontroeluers AvancésFeesher DragwelPas encore d'évaluation
- Presentation MicroprocesseurDocument340 pagesPresentation Microprocesseurpapinou sarrPas encore d'évaluation
- Traiter 2 SteDocument50 pagesTraiter 2 SteFadwa GHANIPas encore d'évaluation
- Chapitre V MicroprocesseurDocument10 pagesChapitre V MicroprocesseurMouhamed MoustaphaPas encore d'évaluation
- Chapitre 2 Introduction Sur Les MicrocontroleursDocument15 pagesChapitre 2 Introduction Sur Les MicrocontroleursMedPas encore d'évaluation
- Chapitre2 SE ARCHITECTURE DES MICROCONTROLLEURSDocument24 pagesChapitre2 SE ARCHITECTURE DES MICROCONTROLLEURSKarima ChakerPas encore d'évaluation
- Chapitre 2 Microcontroleur Pic 16f877Document8 pagesChapitre 2 Microcontroleur Pic 16f877Redouane AmianPas encore d'évaluation
- Cours MicrocontrrolleurDocument65 pagesCours MicrocontrrolleurCrypto Sylvain100% (1)
- Chapitre 4Document37 pagesChapitre 4Ahmed JguirimPas encore d'évaluation
- Chap 1-Présentation de La MachineDocument41 pagesChap 1-Présentation de La MachineFlashPas encore d'évaluation
- Cours Microcontrôleurs-Tres ImportantDocument132 pagesCours Microcontrôleurs-Tres ImportantNabil Dakhli0% (1)
- Architecture Des ProcesseursDocument67 pagesArchitecture Des Processeursayaayaaya456789Pas encore d'évaluation
- Cours - Architecture ch1Document45 pagesCours - Architecture ch1Hoody 05Pas encore d'évaluation
- Cours-Microproc 2018Document192 pagesCours-Microproc 2018Badr Eddine EL HAGAOUIPas encore d'évaluation
- Pic 16F84 2Document40 pagesPic 16F84 2felkirPas encore d'évaluation
- Cours Pics16f877 PDFDocument113 pagesCours Pics16f877 PDFBày RémPas encore d'évaluation
- Chapitre II (Microcontrolleurs)Document28 pagesChapitre II (Microcontrolleurs)Rayene RinaPas encore d'évaluation
- Cours 2022Document88 pagesCours 2022Iheb BelhsanPas encore d'évaluation
- MicroprocesseurDocument11 pagesMicroprocesseurlolizepazePas encore d'évaluation
- Microproc Enstb2001Document124 pagesMicroproc Enstb2001Mohamed EnnajiPas encore d'évaluation
- Informatique IndustrielleDocument16 pagesInformatique IndustrielleNo RayaPas encore d'évaluation
- Chap7 PIC16F84Document12 pagesChap7 PIC16F84keylog100% (1)
- Archi CM01Document37 pagesArchi CM01Àźwű ŠāģhřűPas encore d'évaluation
- B PIC16F877Document35 pagesB PIC16F877KhonashPas encore d'évaluation
- Architectures RISC Et ExemplesDocument6 pagesArchitectures RISC Et ExemplesjuniorPas encore d'évaluation
- Chapitre IIDocument15 pagesChapitre IIdjamalooPas encore d'évaluation
- Introduction Au ProcesseursDocument24 pagesIntroduction Au ProcesseursOliver TwistePas encore d'évaluation
- Partie1 Introduction Cours PDocument15 pagesPartie1 Introduction Cours PKhadija HtPas encore d'évaluation
- Chapitre 5 MicrocontroleursDocument28 pagesChapitre 5 Microcontroleursbenachour ismailPas encore d'évaluation
- PIC LeçonN°1Document16 pagesPIC LeçonN°1Smart ClassePas encore d'évaluation
- Chapitre 2-1Document11 pagesChapitre 2-1bouchenebPas encore d'évaluation
- Cours 1 ASP GBM3-LMDDocument38 pagesCours 1 ASP GBM3-LMDDONIA JBELI100% (1)
- Tous Circuits Logiques ProgrammablesDocument190 pagesTous Circuits Logiques ProgrammablesSaf Bes50% (2)
- Chapitre 1Document58 pagesChapitre 1Ahmed JguirimPas encore d'évaluation
- AB MicroprocesseurDocument11 pagesAB MicroprocesseurMhB SaAdPas encore d'évaluation
- Cours 02Document6 pagesCours 02Wiam KhettabPas encore d'évaluation
- Ingénierie Neuromorphique: La pratique consistant à utiliser des systèmes de circuits électriques analogiques pour imiter les structures neurobiologiques présentes dans le système nerveuxD'EverandIngénierie Neuromorphique: La pratique consistant à utiliser des systèmes de circuits électriques analogiques pour imiter les structures neurobiologiques présentes dans le système nerveuxPas encore d'évaluation
- Examen Transmission22Document3 pagesExamen Transmission22Insafe AarabPas encore d'évaluation
- Diagnostic Des Défauts de Balourd Par Analyse VibratoireDocument60 pagesDiagnostic Des Défauts de Balourd Par Analyse VibratoireInsafe AarabPas encore d'évaluation
- Exemples de RégressionDocument13 pagesExemples de RégressionInsafe AarabPas encore d'évaluation
- Chapitre 2 - Machines SynchronesDocument100 pagesChapitre 2 - Machines SynchronesInsafe Aarab100% (1)
- Recyclage Et Valorisation de Sédiments Fins de Dragage À Usage de Matériaux RoutiersDocument11 pagesRecyclage Et Valorisation de Sédiments Fins de Dragage À Usage de Matériaux RoutiersSaid MOHAFIDPas encore d'évaluation
- 11-Comment Tuer PompeDocument15 pages11-Comment Tuer Pompelee marvin BilongPas encore d'évaluation
- A-TESE 1976 - PesquisaDocument400 pagesA-TESE 1976 - PesquisaBelchiorCosta0% (1)
- Fondements Psycho-Sociaux de La Définition Des Méssages Éducatifs - S3 - 19Document30 pagesFondements Psycho-Sociaux de La Définition Des Méssages Éducatifs - S3 - 19Mohamed TliliPas encore d'évaluation
- FST Equipes Oct 2018Document4 pagesFST Equipes Oct 2018Mohamed HnaPas encore d'évaluation
- PDF Le Grafcet Cours Exercices Corriges - TextmarkDocument186 pagesPDF Le Grafcet Cours Exercices Corriges - Textmarkousmane kanePas encore d'évaluation
- Contexte de LDocument3 pagesContexte de LKonan Richard Kouassi100% (1)
- Activité N°3 A3 Vitesse Et DéplacementDocument2 pagesActivité N°3 A3 Vitesse Et DéplacementEmmanuel VionPas encore d'évaluation
- Mode Operatoire Access 2016 Page 1Document5 pagesMode Operatoire Access 2016 Page 1amoucha sarfdaPas encore d'évaluation
- L2 - B G 1" Examen Écrit 2 Session: PARTIE BIOLOGIE MOLECULAIRE (Note Sur 20 Durée Conseillée: 45 MN)Document3 pagesL2 - B G 1" Examen Écrit 2 Session: PARTIE BIOLOGIE MOLECULAIRE (Note Sur 20 Durée Conseillée: 45 MN)Mohamed SdikPas encore d'évaluation
- Service de Démarrage de Baie de Stockage HPE Niveau 1-A00023078freDocument4 pagesService de Démarrage de Baie de Stockage HPE Niveau 1-A00023078freOlivier DuhamelPas encore d'évaluation
- La Scence Et La CriseDocument8 pagesLa Scence Et La CriseNicolas VantisPas encore d'évaluation
- 04-La Malveillance PDFDocument41 pages04-La Malveillance PDFRachid Richard100% (2)
- Bellevilloise Carte Boisson Vdef PrintempsDocument2 pagesBellevilloise Carte Boisson Vdef PrintempsSabrina DelnardPas encore d'évaluation
- Modele Gratuit de Suivi StockDocument16 pagesModele Gratuit de Suivi StockABDOURAHMANE BERETEPas encore d'évaluation
- Amélioration Des Plantes 2022Document15 pagesAmélioration Des Plantes 2022Brahim GharbiPas encore d'évaluation
- Tabeau de FluxDocument7 pagesTabeau de FluxZakaria AchirPas encore d'évaluation
- ApacheDocument31 pagesApacheAbdelmoumene BoulghalghPas encore d'évaluation
- Imparfait de LDocument2 pagesImparfait de LNastja VogrincPas encore d'évaluation
- A QCM Système Nationale de Santé - CS - SROSDocument112 pagesA QCM Système Nationale de Santé - CS - SROSasmae chadli100% (5)
- Développement Personnel: Sequence 6 - Etre Methodique: Se Fixer Un But Et Un PlanDocument7 pagesDéveloppement Personnel: Sequence 6 - Etre Methodique: Se Fixer Un But Et Un PlanAmeth SeckPas encore d'évaluation
- Geometrie Analytique de L Espace Corrige Serie D Exercices 1Document6 pagesGeometrie Analytique de L Espace Corrige Serie D Exercices 1Mohamed WidadPas encore d'évaluation
- LACROIXCity Sogexi FestilumDocument2 pagesLACROIXCity Sogexi FestilumSchwobPas encore d'évaluation
- Caifanes - Afuera (G2)Document4 pagesCaifanes - Afuera (G2)Víctor IbarraPas encore d'évaluation
- Combiner PDF Apercu MacDocument2 pagesCombiner PDF Apercu MacJonPas encore d'évaluation
- 165 12092010Document18 pages165 12092010elmoudjahid_dzPas encore d'évaluation
- La Nouvelle Norme 5 Les Nouveautés Et Les EnjeuxDocument47 pagesLa Nouvelle Norme 5 Les Nouveautés Et Les EnjeuxSami JaballahPas encore d'évaluation
- Memoire & Resume GODRIX BastienDocument116 pagesMemoire & Resume GODRIX BastienRiadh A.HPas encore d'évaluation
- These Garcia ArandaDocument188 pagesThese Garcia ArandadarkeyesesPas encore d'évaluation