Vous aimerez peut-être aussi
- Chapitre 5 CorrigeDocument14 pagesChapitre 5 Corrigeihsen gasmiPas encore d'évaluation
- ch6 CorrectionexercicesDocument13 pagesch6 CorrectionexercicesOgier SurcoufPas encore d'évaluation
- INF202 - TP05 - Générateur Pseudo-AléatoireDocument3 pagesINF202 - TP05 - Générateur Pseudo-AléatoireVincent LabatutPas encore d'évaluation
- Informatique de BaseDocument8 pagesInformatique de BaseHafsaKanPas encore d'évaluation
- RnotDocument4 pagesRnotilliPas encore d'évaluation
- Concurrence tp1Document4 pagesConcurrence tp1MohamedChiheb BenChaabanePas encore d'évaluation
- TP JAVA Amine Ramadane LPABD 2022 2023Document23 pagesTP JAVA Amine Ramadane LPABD 2022 2023Amine RamadanePas encore d'évaluation
- Cours AlgorithmeDocument52 pagesCours AlgorithmeH-KatiPas encore d'évaluation
- Tutoriels Utilisation de KNNDocument10 pagesTutoriels Utilisation de KNNKodjo SouleymanePas encore d'évaluation
- TP 5 Les Reseaux de Neurones ArtificielsDocument6 pagesTP 5 Les Reseaux de Neurones ArtificielsBaha BechikhPas encore d'évaluation
- HangmanDocument5 pagesHangmanllfreakyPas encore d'évaluation
- Travaux D - 02Document7 pagesTravaux D - 02Ahmed FawziPas encore d'évaluation
- Bash Scripts Exercices Solutions tp3Document6 pagesBash Scripts Exercices Solutions tp3billyzebillPas encore d'évaluation
- Mines2019 CorrectionDocument4 pagesMines2019 CorrectionfatehPas encore d'évaluation
- TD3 SemaphoresDocument5 pagesTD3 Semaphoresmeezto1Pas encore d'évaluation
- Python Les Instructions Et Boucles ConditionnellesDocument1 pagePython Les Instructions Et Boucles ConditionnellesMouna BoumezbeurPas encore d'évaluation
- TP AnnDocument2 pagesTP AnnLe DescripteurPas encore d'évaluation
- Tutoriel Pratiques Avancées Et Méconnues en PythonDocument13 pagesTutoriel Pratiques Avancées Et Méconnues en PythonPi91Pas encore d'évaluation
- Examen Economertire Non paraDocument14 pagesExamen Economertire Non paramamoudou tallaPas encore d'évaluation
- TP InformatiqueDocument28 pagesTP Informatiquemechernene_aek9037Pas encore d'évaluation
- Serie1correction PartielleDocument11 pagesSerie1correction PartielleMohamed TrabelsiPas encore d'évaluation
- Boids PaperDocument18 pagesBoids Paperseyba tourePas encore d'évaluation
- Test LivreDocument2 pagesTest Livresouha ben abdessalemPas encore d'évaluation
- TutoPython&KerasLesréseauxdeneurones-TutorielPython 1683742635968 PDFDocument23 pagesTutoPython&KerasLesréseauxdeneurones-TutorielPython 1683742635968 PDFkoudou EliePas encore d'évaluation
- Ex Id2009Document3 pagesEx Id2009zlatko22225Pas encore d'évaluation
- Introduction Au JavaDocument8 pagesIntroduction Au JavaYounous TCHAOPas encore d'évaluation
- Cours MallocDocument7 pagesCours MallocTàHa SamihPas encore d'évaluation
- Cahier D'algorithmique Avec AlgoboxDocument16 pagesCahier D'algorithmique Avec AlgoboxvinblanPas encore d'évaluation
- Exceptions Et GénériquesDocument3 pagesExceptions Et GénériquesAngélica DEKEPas encore d'évaluation
- Cours Simulation 2 13Document12 pagesCours Simulation 2 13Ilham TimadjerPas encore d'évaluation
- Cours Simulation 2 13Document12 pagesCours Simulation 2 13Ilham TimadjerPas encore d'évaluation
- ALGORITHME 1R Cours 3Document6 pagesALGORITHME 1R Cours 3aya bouremanaPas encore d'évaluation
- INFO - Terminale CDDocument2 pagesINFO - Terminale CDsteve keudemPas encore d'évaluation
- Q de Cours SEDocument2 pagesQ de Cours SESoufyane SosoPas encore d'évaluation
- Programmation Parallele PythonDocument9 pagesProgrammation Parallele PythonKhlifi AyoubPas encore d'évaluation
- Programmation Parallele Python PDFDocument9 pagesProgrammation Parallele Python PDFKhlifi AyoubPas encore d'évaluation
- Examen 1h Principes Des Systèmes D'exploitation - Unix/LinuxDocument4 pagesExamen 1h Principes Des Systèmes D'exploitation - Unix/LinuxMai Anh ThưPas encore d'évaluation
- Orniformation Bts Corrige Informatique 2013Document4 pagesOrniformation Bts Corrige Informatique 2013MENGUE Benjamin BienvenuPas encore d'évaluation
- SujetTP SNMPDocument3 pagesSujetTP SNMPfun funPas encore d'évaluation
- TP CNNDocument4 pagesTP CNNFrank Facundo0% (1)
- Informatique Cours 01Document9 pagesInformatique Cours 01Kim OutchenPas encore d'évaluation
- Enoncé Du TP1Document2 pagesEnoncé Du TP1Zahra TALEBPas encore d'évaluation
- TPDocument9 pagesTPyousfi.najah6085100% (1)
- TP2: Lecture de Différents Jeux de Données: Table Des MatièresDocument3 pagesTP2: Lecture de Différents Jeux de Données: Table Des MatièresCyrine AkachaPas encore d'évaluation
- TP 1: Basic Process: I. ObjectifDocument7 pagesTP 1: Basic Process: I. ObjectifBassem DebbabiPas encore d'évaluation
- Devoir 151Document5 pagesDevoir 151gabrielfokou26Pas encore d'évaluation
- Forensic WindowsDocument23 pagesForensic WindowsHajar Nejmaoui100% (1)
- PfeDocument7 pagesPfeSi Mohamed RahiliPas encore d'évaluation
- ModuleDocument5 pagesModuleGhaffari WalidPas encore d'évaluation
- TP MemoireDocument2 pagesTP Memoireعضوش محمدPas encore d'évaluation
- 537e07ce544ab PDFDocument17 pages537e07ce544ab PDFtangomoPas encore d'évaluation
- Processus Threads CorrigeDocument8 pagesProcessus Threads CorrigeRita Bernice ShimwePas encore d'évaluation
- TP JavaDocument4 pagesTP JavanakulPas encore d'évaluation
- TP3 SujetDocument4 pagesTP3 SujetEL StanPas encore d'évaluation
- TP1 Numpy Matplotlib CorrigeDocument14 pagesTP1 Numpy Matplotlib CorrigeFatima zahra BenmeriemePas encore d'évaluation
- Réseau Neuronal Recurrent "Recurrent Neural Network" (RNN)Document9 pagesRéseau Neuronal Recurrent "Recurrent Neural Network" (RNN)kasmi zoubeirPas encore d'évaluation
- EFM Algo V5Document2 pagesEFM Algo V5blaixmrxPas encore d'évaluation
- L'intelligence artificielle: Les machines sont-elles déjà plus intelligentes que nous?D'EverandL'intelligence artificielle: Les machines sont-elles déjà plus intelligentes que nous?Pas encore d'évaluation
- 3.1 Structure Et Propriétés Des Nucléotides Et Acis NucléiquesDocument39 pages3.1 Structure Et Propriétés Des Nucléotides Et Acis NucléiquessedighdahmanPas encore d'évaluation
- GOPM MGP Version Du 23-04-04Document36 pagesGOPM MGP Version Du 23-04-04Bouallegue Mounir0% (1)
- Britannicus de Jean RACINEDocument6 pagesBritannicus de Jean RACINEsiyeon9242100% (1)
- FICHE Nombre Et Calcul Au PrimaireDocument2 pagesFICHE Nombre Et Calcul Au PrimaireNoémie De PauwPas encore d'évaluation
- Exercices de ThermodynamiqueDocument18 pagesExercices de ThermodynamiqueBadre-ezzamen KaddourPas encore d'évaluation
- Développement D'une Applicatio - Chaimae EL GADDAR - 3989Document74 pagesDéveloppement D'une Applicatio - Chaimae EL GADDAR - 3989Mouad SaadPas encore d'évaluation
- Candidaturemaster Fsjes Uca Ma IojDocument2 pagesCandidaturemaster Fsjes Uca Ma IojBERPas encore d'évaluation
- Pic 16 F 84Document47 pagesPic 16 F 84Salah DahouathiPas encore d'évaluation
- Cas Meuble ÉcoDocument3 pagesCas Meuble Écoabdou100% (1)
- Trace Metal Analysis in Petroleum Products SampleDocument10 pagesTrace Metal Analysis in Petroleum Products SampleEssam Eldin Metwally AhmedPas encore d'évaluation
- Cours Catia v5Document28 pagesCours Catia v5Ahmed Ben YahiaPas encore d'évaluation
- Le Collectif de L Orbe - Scenario Une Page - Ondines Sur Sambre - Le Sup HDDocument1 pageLe Collectif de L Orbe - Scenario Une Page - Ondines Sur Sambre - Le Sup HDdimebagsithPas encore d'évaluation
- Opérateur de Laboratoire en Mécanique Des Sols: Programme D'étudesDocument128 pagesOpérateur de Laboratoire en Mécanique Des Sols: Programme D'étudesOuezna BahloulPas encore d'évaluation
- Le Risque La Norme ISO/IEC Guide 73 Définit Le Risque Comme: Je Peu Dire QueDocument5 pagesLe Risque La Norme ISO/IEC Guide 73 Définit Le Risque Comme: Je Peu Dire QueFerhat LadjeroudPas encore d'évaluation
- Cours D'optique Géométrique SVT - PC EnsDocument83 pagesCours D'optique Géométrique SVT - PC EnsIssouf DiabyPas encore d'évaluation
- TD Entrainement Électrique Avec SolutionDocument5 pagesTD Entrainement Électrique Avec SolutionBensalemPas encore d'évaluation
- Justificatif D'Abonnement: #ATT3060295282Document1 pageJustificatif D'Abonnement: #ATT3060295282Lydia OUALIDPas encore d'évaluation
- Product Technical SheetDocument3 pagesProduct Technical SheetRyanRwPas encore d'évaluation
- ArabeDocument7 pagesAraberanya.shaamsPas encore d'évaluation
- Calcul LitteralDocument3 pagesCalcul Litteralvangog777Pas encore d'évaluation
- Renforcement de La Sécurité Alimentaire en Afrique Centrale À Travers La Gestion Durable Des Produits Forestiers Non Ligneux (GCP/RAF/441/GER)Document2 pagesRenforcement de La Sécurité Alimentaire en Afrique Centrale À Travers La Gestion Durable Des Produits Forestiers Non Ligneux (GCP/RAF/441/GER)blaise kabeyaPas encore d'évaluation
- Comique BurlesqueDocument5 pagesComique BurlesqueABDOUPas encore d'évaluation
- C6 Chap05 - MolliexDocument19 pagesC6 Chap05 - MolliexboblenazePas encore d'évaluation
- Bekhadda Salima 2ddocposDocument2 pagesBekhadda Salima 2ddocposLina AddaPas encore d'évaluation
- Amendement Loi 13-09Document4 pagesAmendement Loi 13-09nas el ghiouanPas encore d'évaluation
- Sociologie Du Sport Duret Pascal 1Document223 pagesSociologie Du Sport Duret Pascal 1Jihed HajSalem100% (1)
- Cours MATHEMATIQUE 4eme COMPLETDocument134 pagesCours MATHEMATIQUE 4eme COMPLETRasolondraibe Jean Marie100% (2)
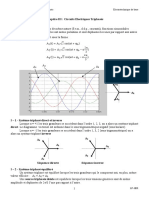
- Chap3 Circuit Triphasés-1Document15 pagesChap3 Circuit Triphasés-1azezaePas encore d'évaluation
- Lagarce Absurde Épique DistanciationDocument5 pagesLagarce Absurde Épique DistanciationLudovica PasiPas encore d'évaluation
- RC Exploitant en Informatique FINALDocument24 pagesRC Exploitant en Informatique FINALhocine fali100% (1)