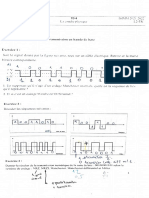
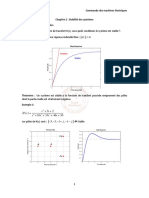
Vous aimerez peut-être aussi
- Presenatationassembleur 2010Document169 pagesPresenatationassembleur 2010NOURDINE EZZALMADIPas encore d'évaluation
- Twistronics: Le saint graal de la physique, des matériaux quantiques et des nanotechnologiesD'EverandTwistronics: Le saint graal de la physique, des matériaux quantiques et des nanotechnologiesPas encore d'évaluation
- Microprocess Eur 68000Document7 pagesMicroprocess Eur 68000N.NASRI MatlablogPas encore d'évaluation
- Théorie et conception des filtres analogiques, 2e édition: Avec MatlabD'EverandThéorie et conception des filtres analogiques, 2e édition: Avec MatlabPas encore d'évaluation
- Chapitre 3Document49 pagesChapitre 3Hamza BeninePas encore d'évaluation
- MAITRISER Python : De l'Apprentissage aux Projets ProfessionnelsD'EverandMAITRISER Python : De l'Apprentissage aux Projets ProfessionnelsPas encore d'évaluation
- Chapitre 4 Alimentation - Moteur - Pas - À - PasDocument37 pagesChapitre 4 Alimentation - Moteur - Pas - À - Paskhaled100% (1)
- TP3: Conception Schématique Des Microprocesseurs: ObjectifDocument6 pagesTP3: Conception Schématique Des Microprocesseurs: ObjectifDor SafPas encore d'évaluation
- Examen IE5 Janvier 2020 FinalDocument14 pagesExamen IE5 Janvier 2020 FinalDhafer MezghaniPas encore d'évaluation
- Temporisation - Les Variables en AssembleurDocument16 pagesTemporisation - Les Variables en AssembleurMolka ABIDPas encore d'évaluation
- TP MicroprocesseurDocument2 pagesTP Microprocesseurben houria yassinePas encore d'évaluation
- SE Gestion MemoireDocument6 pagesSE Gestion MemoireFadwa ZedPas encore d'évaluation
- Un - Syst - Me - Microprocesseur - PDF Filename - UTF-8''Un Système À MicroprocesseurDocument11 pagesUn - Syst - Me - Microprocesseur - PDF Filename - UTF-8''Un Système À MicroprocesseurLynda MOKRANIPas encore d'évaluation
- Corrigé Du TD2Document2 pagesCorrigé Du TD2youssef BohaPas encore d'évaluation
- Chapitre 3Document13 pagesChapitre 3Dhafer MezghaniPas encore d'évaluation
- Analyses VH DDocument10 pagesAnalyses VH DMustapha El IdrissiPas encore d'évaluation
- La Programmation en Assembleur Du Microprocesseur 8086Document18 pagesLa Programmation en Assembleur Du Microprocesseur 8086Abdou Bensalek100% (1)
- Partie-2-Microprocesseur + MemoireDocument14 pagesPartie-2-Microprocesseur + MemoireyaoPas encore d'évaluation
- TD Exam PDFDocument12 pagesTD Exam PDFpapPas encore d'évaluation
- Exam - ARCHITECTURE - Jan - 2021-V3 - CorrigéDocument2 pagesExam - ARCHITECTURE - Jan - 2021-V3 - CorrigéGANG SHOOTPas encore d'évaluation
- Codage ManchesterDocument18 pagesCodage ManchesterRACHID100% (2)
- TD N - 1architecture PDFDocument2 pagesTD N - 1architecture PDFABDELKARIM AINPas encore d'évaluation
- Mini Projet Recherche Operationnelle Programmation Dans CDocument10 pagesMini Projet Recherche Operationnelle Programmation Dans CBitote ADPas encore d'évaluation
- Modes D'adressage 6800Document9 pagesModes D'adressage 6800N.NASRI Matlablog100% (1)
- Chapitre 3Document163 pagesChapitre 3nourPas encore d'évaluation
- Programmation Assembleur 8086Document51 pagesProgrammation Assembleur 8086zied harchayPas encore d'évaluation
- IjDocument7 pagesIjAbderrahmane WardiPas encore d'évaluation
- Cours JDBC PDFDocument13 pagesCours JDBC PDFSanae BerrahoPas encore d'évaluation
- TP2 MicroprocesseurDocument14 pagesTP2 MicroprocesseurAdem AounPas encore d'évaluation
- Projet Tutoré FinalDocument31 pagesProjet Tutoré FinalJun JunPas encore d'évaluation
- Examen Rattrapage IE5 2020 FinalDocument9 pagesExamen Rattrapage IE5 2020 FinalDhafer MezghaniPas encore d'évaluation
- Architecture Et Programmation Des Micro-Contrôleurs: Khaled - Taouil@enetcom - Usf.tnDocument47 pagesArchitecture Et Programmation Des Micro-Contrôleurs: Khaled - Taouil@enetcom - Usf.tnamalPas encore d'évaluation
- Correc BD TD1Document3 pagesCorrec BD TD1Mariem Sayedi100% (1)
- Exercices Commandes Ms Dos PDF CompressDocument2 pagesExercices Commandes Ms Dos PDF CompressAvahouin NicaisePas encore d'évaluation
- TD1 DSP 2GT 2014-2015Document14 pagesTD1 DSP 2GT 2014-2015AĦmedǤĦaffariPas encore d'évaluation
- Travaux Dirigés: Exercice 1Document1 pageTravaux Dirigés: Exercice 1Oussama ObPas encore d'évaluation
- Exercices Architecture Des Processeurs Et MicroprocesseursDocument4 pagesExercices Architecture Des Processeurs Et MicroprocesseursGeorges Le Mignon Ole100% (1)
- Examen SOC Session Rattrapage LEEA3 Janvier 2022Document6 pagesExamen SOC Session Rattrapage LEEA3 Janvier 2022Dhafer MezghanniPas encore d'évaluation
- MMO Corrigé Sujet 1synthèse M21Document3 pagesMMO Corrigé Sujet 1synthèse M21Abdou KarimPas encore d'évaluation
- C Memoire2 PDFDocument5 pagesC Memoire2 PDFMohammed ElbachiriPas encore d'évaluation
- Poly TP en Tp2 Geii 2019Document12 pagesPoly TP en Tp2 Geii 2019sdfPas encore d'évaluation
- 7segments VHDLDocument5 pages7segments VHDLSoufiane BoulachgourPas encore d'évaluation
- 04 Microprocesseur 8086Document18 pages04 Microprocesseur 8086nesrine ninaPas encore d'évaluation
- Le Microprocesseur 8086 8088Document16 pagesLe Microprocesseur 8086 8088Nassimos YalanosPas encore d'évaluation
- TD 1Document2 pagesTD 1Hary YoskovichPas encore d'évaluation
- DauphinDocument48 pagesDauphinAnas KertyPas encore d'évaluation
- CoursAssembleur - Chap1 Et 2Document28 pagesCoursAssembleur - Chap1 Et 2Achraf ElkhodariPas encore d'évaluation
- Transmission de Donnée TDDocument19 pagesTransmission de Donnée TDOmri yosraPas encore d'évaluation
- Exercice Programmation Assembleur PDFDocument2 pagesExercice Programmation Assembleur PDFTonyaPas encore d'évaluation
- CH 2 CodageDocument5 pagesCH 2 CodageSaid Ait MansourPas encore d'évaluation
- TP1Document5 pagesTP1Oumayma AmiriPas encore d'évaluation
- Programmation Avancée Avec Les Microcontrôleurs STM32Document70 pagesProgrammation Avancée Avec Les Microcontrôleurs STM32El Hassane MakboubPas encore d'évaluation
- Enoncé Mini Projet POODocument2 pagesEnoncé Mini Projet POOyassine gabsi100% (1)
- Chapitre1 Evolution Des OrdinateursDocument45 pagesChapitre1 Evolution Des OrdinateursidemPas encore d'évaluation
- Jeu D - Instructions Du PIC16F84ADocument9 pagesJeu D - Instructions Du PIC16F84AOMAR ENNAJIPas encore d'évaluation
- Série 02Document5 pagesSérie 02kal joPas encore d'évaluation
- Le Schema Fonctionnel Du MicroprocesseurDocument4 pagesLe Schema Fonctionnel Du MicroprocesseurAbdeRaouf OulmiPas encore d'évaluation
- TD Assembleur Lp2 Mirtax86Document8 pagesTD Assembleur Lp2 Mirtax86Oumar Farouk Achirou ElhadjiPas encore d'évaluation
- 01 - Architecture Des OrdinateursDocument41 pages01 - Architecture Des OrdinateursMina NouhiiPas encore d'évaluation
- Questions de Cours Corrigés en Ordonnancement Des Processus (Systèmes D'exploitation 1) - Exercices en Réseaux InformatiquesDocument3 pagesQuestions de Cours Corrigés en Ordonnancement Des Processus (Systèmes D'exploitation 1) - Exercices en Réseaux InformatiquesLeroy Lionel SonfackPas encore d'évaluation
- CC - Anal - Num - ISR - 2024Document2 pagesCC - Anal - Num - ISR - 2024Leroy Lionel SonfackPas encore d'évaluation
- MethodeDocument7 pagesMethodeLeroy Lionel SonfackPas encore d'évaluation
- Bilan PuissDocument1 pageBilan PuissLeroy Lionel SonfackPas encore d'évaluation
- Ber44 08 10Document3 pagesBer44 08 10Leroy Lionel SonfackPas encore d'évaluation
- TD de Traitement Du Signal TD N 4 Signaux AléatoiresDocument11 pagesTD de Traitement Du Signal TD N 4 Signaux AléatoiresLeroy Lionel SonfackPas encore d'évaluation
- Fiche TD Reseaux 2019Document23 pagesFiche TD Reseaux 2019Leroy Lionel SonfackPas encore d'évaluation
- 3 Filtrage1Document25 pages3 Filtrage1Leroy Lionel SonfackPas encore d'évaluation
- BTS 2021 - ElectrotechniqueDocument17 pagesBTS 2021 - ElectrotechniqueLeroy Lionel SonfackPas encore d'évaluation
- Cours Commande CH 1Document5 pagesCours Commande CH 1Leroy Lionel SonfackPas encore d'évaluation
- BTS 2022 - Informatique Industrielle Et AutomatismeDocument7 pagesBTS 2022 - Informatique Industrielle Et AutomatismeLeroy Lionel SonfackPas encore d'évaluation
- Cours Commande CH 2Document4 pagesCours Commande CH 2Leroy Lionel SonfackPas encore d'évaluation
- Bilan de Puissance-1Document2 pagesBilan de Puissance-1Leroy Lionel SonfackPas encore d'évaluation
- 2 HistogrammeDocument35 pages2 HistogrammeLeroy Lionel SonfackPas encore d'évaluation
- VIB Booklet F PDFDocument36 pagesVIB Booklet F PDFMustafa MoussaouiPas encore d'évaluation
- BTS 2021 - Informatique Industrielle Et AutomatismeDocument8 pagesBTS 2021 - Informatique Industrielle Et AutomatismeLeroy Lionel SonfackPas encore d'évaluation
- 4 Filtrage2Document25 pages4 Filtrage2Leroy Lionel SonfackPas encore d'évaluation
- 1 - TD1 - Decoupe de ProfilesDocument3 pages1 - TD1 - Decoupe de ProfilesLeroy Lionel SonfackPas encore d'évaluation
- Les API - DecryptedDocument67 pagesLes API - DecryptedLeroy Lionel SonfackPas encore d'évaluation
- 2017 Exo2 SourceslumineusesDocument4 pages2017 Exo2 SourceslumineusesLeroy Lionel SonfackPas encore d'évaluation
- Guidedepriseenmainde Proces SimDocument284 pagesGuidedepriseenmainde Proces SimLeroy Lionel SonfackPas encore d'évaluation
- TP TopographieDocument30 pagesTP TopographieNizar Axel Braham100% (2)
- Papier PDFDocument23 pagesPapier PDF147896azPas encore d'évaluation
- Chapitre 2 PDFDocument24 pagesChapitre 2 PDFHadjerBenzelmatPas encore d'évaluation
- Notion Élémentaire de TopographieDocument18 pagesNotion Élémentaire de TopographieFatima BouchfarPas encore d'évaluation
- Notion Élémentaire de TopographieDocument18 pagesNotion Élémentaire de TopographieFatima BouchfarPas encore d'évaluation
- Maintenance Preventive Des Ven - Hafid BOUSRHIRI - 4238Document89 pagesMaintenance Preventive Des Ven - Hafid BOUSRHIRI - 4238Leroy Lionel SonfackPas encore d'évaluation
- Sans Titre 2Document6 pagesSans Titre 2Leroy Lionel SonfackPas encore d'évaluation
- Electroméc ElectromécaniqueDocument6 pagesElectroméc ElectromécaniqueDjẹlli MẹđjadiPas encore d'évaluation
- OBS Introduction1Document14 pagesOBS Introduction1Leroy Lionel SonfackPas encore d'évaluation
- Cours ScribusDocument307 pagesCours ScribusRalaivao Dimbihary Alex DenisPas encore d'évaluation
- TP RAID MaterielDocument4 pagesTP RAID MaterielSalahAaribouPas encore d'évaluation
- L'avenir Du Plateau Nord de CaenDocument30 pagesL'avenir Du Plateau Nord de Caenmarcelbinmarcel100% (1)
- 10questions Sur La Qualite de Vie Au Travail 2016Document20 pages10questions Sur La Qualite de Vie Au Travail 2016simao_sabrosa7794Pas encore d'évaluation
- Rapport Hypertexte Les Pathologies Liees A L AlimentationDocument53 pagesRapport Hypertexte Les Pathologies Liees A L Alimentationdeziri mohamedPas encore d'évaluation
- Introduction Problèmes FameuxDocument14 pagesIntroduction Problèmes FameuxDominique HartungPas encore d'évaluation
- Projet Analyse FonctionnelleDocument102 pagesProjet Analyse Fonctionnellewatsop100% (1)
- Exemples Correspondances Administratives PDFDocument2 pagesExemples Correspondances Administratives PDFLaurenPas encore d'évaluation
- Support CHAPITRE 4 Fiabilité Systèmes MécaniquesDocument24 pagesSupport CHAPITRE 4 Fiabilité Systèmes Mécaniqueszangue billy jamesPas encore d'évaluation
- Defis CMDocument20 pagesDefis CMDE GEYTPas encore d'évaluation
- Prevision Offre de CoursDocument2 pagesPrevision Offre de CoursMohamed ArsalanPas encore d'évaluation
- Cahier Des Charges Beton PDFDocument10 pagesCahier Des Charges Beton PDFAnonymous 7OG1zAPas encore d'évaluation
- Méthodologie ch1Document47 pagesMéthodologie ch1studio linePas encore d'évaluation
- Rapport Mini Projet TopographieDocument10 pagesRapport Mini Projet Topographieأنيس بن مبروكPas encore d'évaluation
- CoursACPacmAFC Beamer 2023Document117 pagesCoursACPacmAFC Beamer 2023Joël DabiréPas encore d'évaluation
- 1816 Em27092015 PDFDocument15 pages1816 Em27092015 PDFelmoudjahid_dzPas encore d'évaluation
- Appareillagedistill PDFDocument4 pagesAppareillagedistill PDFSa RahPas encore d'évaluation
- Evalang PresentationdesitemsauxelevesDocument20 pagesEvalang PresentationdesitemsauxelevesBernadette DUMONTPas encore d'évaluation
- Production Écrite - Delf B2Document3 pagesProduction Écrite - Delf B2jkleePas encore d'évaluation
- Windows Presentation FoundationDocument61 pagesWindows Presentation FoundationAhlam MalakPas encore d'évaluation
- Evaluer La ProductionDocument14 pagesEvaluer La ProductionHeadson SantosPas encore d'évaluation
- Chapitre 3Document15 pagesChapitre 3Bouchra BourassPas encore d'évaluation
- ConflitsDocument2 pagesConflitskarlinPas encore d'évaluation
- Initiation A La Recherche ScientifiqueDocument24 pagesInitiation A La Recherche ScientifiqueBrayen Kasonga100% (19)
- Ingénieur AgronomeDocument2 pagesIngénieur Agronomeouakardous100% (1)
- Memento Prof MiDocument2 pagesMemento Prof MiLights'artsPas encore d'évaluation
- Cycle de Krebs PDFDocument9 pagesCycle de Krebs PDFMa RyPas encore d'évaluation
- Trace CohesionDocument3 pagesTrace CohesionccPas encore d'évaluation
- ComparateurDocument3 pagesComparateurOUZLIG MohamedPas encore d'évaluation
- Auguste Comte La Loi Des 3 État 2 Eme ÉtatDocument1 pageAuguste Comte La Loi Des 3 État 2 Eme ÉtathilladeclackPas encore d'évaluation