Vous aimerez peut-être aussi
- Mi-Les Rseaux de Neurones Artificiels PDFDocument49 pagesMi-Les Rseaux de Neurones Artificiels PDFYouva H.APas encore d'évaluation
- Presentahion Reseau de NeuroneDocument53 pagesPresentahion Reseau de NeuroneHmz OussamaPas encore d'évaluation
- Réseau de NeuronDocument37 pagesRéseau de NeuronHoussam HPas encore d'évaluation
- Le Réseau de Neurones Artificiel: PR A. Majda - FST - FesDocument82 pagesLe Réseau de Neurones Artificiel: PR A. Majda - FST - Fesramzi ayadiPas encore d'évaluation
- Expose de Machine Learning Final g7Document14 pagesExpose de Machine Learning Final g7Audrey Leons TsayemPas encore d'évaluation
- Partie 1Document29 pagesPartie 1Shams On PersonnePas encore d'évaluation
- Modélisation D'une Machine Asynchrone Par Réseau de NeuroneDocument29 pagesModélisation D'une Machine Asynchrone Par Réseau de NeuroneHachemi Bhe80% (10)
- Introduction Au Réseau de Neurones ArtificielDocument30 pagesIntroduction Au Réseau de Neurones ArtificielNemiPas encore d'évaluation
- Cours RNADocument24 pagesCours RNAmichelPas encore d'évaluation
- Réseaux DE Neurone2022Document33 pagesRéseaux DE Neurone2022nadjib100% (1)
- TP 5 Les Reseaux de Neurones ArtificielsDocument6 pagesTP 5 Les Reseaux de Neurones ArtificielsBaha BechikhPas encore d'évaluation
- Chapitre 3Document26 pagesChapitre 3Bilou MenderPas encore d'évaluation
- RNA ARTISéance20octobreDocument35 pagesRNA ARTISéance20octobreSara DhahriPas encore d'évaluation
- Chapitre III-partie 1Document15 pagesChapitre III-partie 1Yosr LenglizPas encore d'évaluation
- Réseau de NeuronesDocument49 pagesRéseau de NeuronesOualid ZaouichPas encore d'évaluation
- Chapitre 04 - Réseaux de NeuronesDocument17 pagesChapitre 04 - Réseaux de NeuronesAhmed Ayoub OsmaniPas encore d'évaluation
- RN Sec3Document16 pagesRN Sec3akramPas encore d'évaluation
- Chapitre 4Document11 pagesChapitre 4MehdiPas encore d'évaluation
- Introduction Aux Réseaux de Neurones 23062023Document13 pagesIntroduction Aux Réseaux de Neurones 23062023Euloge ABOUDOUPas encore d'évaluation
- Cours RNDocument46 pagesCours RNkhalilPas encore d'évaluation
- Data Mining Cours 7Document39 pagesData Mining Cours 7Salem AmiratPas encore d'évaluation
- Cours Reseaux de NeuronesDocument20 pagesCours Reseaux de NeuronesPatrick Marcial Etata Mandjouk100% (1)
- Réseau Neuronal Recurrent "Recurrent Neural Network" (RNN)Document9 pagesRéseau Neuronal Recurrent "Recurrent Neural Network" (RNN)kasmi zoubeirPas encore d'évaluation
- Cours PerceptronDocument58 pagesCours PerceptrongraPas encore d'évaluation
- Neural NetworkV2Document46 pagesNeural NetworkV2ChaymaePas encore d'évaluation
- Séance 5 - Réseaux de Neurones 21 Avril 2014Document30 pagesSéance 5 - Réseaux de Neurones 21 Avril 2014ayoubhaouasPas encore d'évaluation
- L3 Cours Reseauneurones Part1Document23 pagesL3 Cours Reseauneurones Part1Mardochee ROBNDOHPas encore d'évaluation
- Deep Learning Cours 1Document12 pagesDeep Learning Cours 1blacktools2Pas encore d'évaluation
- Chap 2 - Réseaux de Neurones - 2017-2018Document81 pagesChap 2 - Réseaux de Neurones - 2017-2018Âh MèdPas encore d'évaluation
- Rseauxdeneurones2 150218132026 Conversion Gate02Document19 pagesRseauxdeneurones2 150218132026 Conversion Gate02ZãkăŘįą SadratiPas encore d'évaluation
- Cours TIA - Chapitre 2 PDFDocument11 pagesCours TIA - Chapitre 2 PDFHoussine GuePas encore d'évaluation
- Réseaux de Neurones Artificiels By: Abdelouahid ELYAHYAOUIDocument35 pagesRéseaux de Neurones Artificiels By: Abdelouahid ELYAHYAOUIRachid ZinePas encore d'évaluation
- Réseaux de Neurones Artificiels: Hélène Paugam-MoisyDocument56 pagesRéseaux de Neurones Artificiels: Hélène Paugam-MoisyCyrille LamasséPas encore d'évaluation
- Réseaux de NeuronesDocument54 pagesRéseaux de NeuronesSouhaib LoudaPas encore d'évaluation
- Les Réseaux de NeuronesDocument11 pagesLes Réseaux de Neuronessaidista2021Pas encore d'évaluation
- Réseaux de NeuroneDocument73 pagesRéseaux de NeuroneIbrahim Ben AbderrahmenPas encore d'évaluation
- ChapitreAA RN 5Document19 pagesChapitreAA RN 5Meryem KachaniPas encore d'évaluation
- IATIC4 FBC CM2 v1.0Document24 pagesIATIC4 FBC CM2 v1.0classic.boy211Pas encore d'évaluation
- Module09 Deep Learning 02-Part01Document29 pagesModule09 Deep Learning 02-Part01syslinux2000Pas encore d'évaluation
- Cours de Magister Reseaux de NeuronesDocument27 pagesCours de Magister Reseaux de NeuronesAnonymous KhhapQJVYtPas encore d'évaluation
- ANN Part 1Document6 pagesANN Part 1Ouail MakhebiPas encore d'évaluation
- Introduction AuxDocument36 pagesIntroduction AuxImad NassiriPas encore d'évaluation
- Les Reseaux de NeuronesDocument3 pagesLes Reseaux de Neuronesgha0% (1)
- Réseau Neronnes Et Logique FloueDocument11 pagesRéseau Neronnes Et Logique FloueKHAOULA WISSALE HARIKIPas encore d'évaluation
- Chapitre 5Document16 pagesChapitre 5Bilou Mender100% (1)
- RNDocument4 pagesRNSofiene GuedriPas encore d'évaluation
- Cours RNNDocument28 pagesCours RNNKen ZaPas encore d'évaluation
- Chap 1 RNADocument32 pagesChap 1 RNAfahd ghabiPas encore d'évaluation
- Chap 4 RNADocument24 pagesChap 4 RNAfahd ghabiPas encore d'évaluation
- Chapitre IIDocument9 pagesChapitre IIbennoui houssemPas encore d'évaluation
- R Eseaux de Neuronnes Artificielles Ann For Datamining: Pr. Khadija SadikDocument46 pagesR Eseaux de Neuronnes Artificielles Ann For Datamining: Pr. Khadija SadiklbibazbibaPas encore d'évaluation
- Commande NeuronalDocument15 pagesCommande NeuronalÑo ÑaměPas encore d'évaluation
- RapportDocument16 pagesRapportFät MãPas encore d'évaluation
- coursRNA Master19 PDFDocument61 pagescoursRNA Master19 PDFTOUFIKPas encore d'évaluation
- 6 NN RPDocument99 pages6 NN RPRebhi AchrefPas encore d'évaluation
- Projetrseauxdeneurones V3Document62 pagesProjetrseauxdeneurones V3oumaimaPas encore d'évaluation
- 04 - Les Reseaux de Neurones Formels Pour Le Pilotage de Robots MobilesDocument11 pages04 - Les Reseaux de Neurones Formels Pour Le Pilotage de Robots MobilesDOTSYS DevPas encore d'évaluation
- Le Perceptron Multicouche Back PropagationDocument17 pagesLe Perceptron Multicouche Back PropagationFatima AbdiPas encore d'évaluation
- Neurobiologie: Les Grands Articles d'UniversalisD'EverandNeurobiologie: Les Grands Articles d'UniversalisPas encore d'évaluation
- TD ProbaDocument11 pagesTD ProbaMayssoun chaimaaPas encore d'évaluation
- Crypto BIBDADocument138 pagesCrypto BIBDAMayssoun chaimaaPas encore d'évaluation
- Thèse de Doctorat en InformatiqueDocument156 pagesThèse de Doctorat en InformatiqueMayssoun chaimaaPas encore d'évaluation
- CoursTI2 BIBDADocument31 pagesCoursTI2 BIBDAMayssoun chaimaaPas encore d'évaluation
- CoursTI1 BIBDADocument47 pagesCoursTI1 BIBDAMayssoun chaimaaPas encore d'évaluation
- 2 - Algo GenetiquesDocument35 pages2 - Algo GenetiquesMayssoun chaimaaPas encore d'évaluation
- NominalisationDocument2 pagesNominalisationMed izdarPas encore d'évaluation
- Définitions Neuropsy Chap 1 À 5Document9 pagesDéfinitions Neuropsy Chap 1 À 5LisePas encore d'évaluation
- Cotedivoire Delafosse1904 oDocument296 pagesCotedivoire Delafosse1904 oReggePas encore d'évaluation
- WFB - Broschuere21 - Demoulage Boulangerie PDFDocument20 pagesWFB - Broschuere21 - Demoulage Boulangerie PDFcottePas encore d'évaluation
- ArgumentationDocument5 pagesArgumentationOum ZaydPas encore d'évaluation
- Memoire Berte Souleymane PDFDocument95 pagesMemoire Berte Souleymane PDFBadra Ali Sanogo100% (1)
- Notice Hydraulique V5Document20 pagesNotice Hydraulique V5IssifouHamdaneAdamPas encore d'évaluation
- Paa ToucheDocument53 pagesPaa ToucheNABIL100% (2)
- Stage 2020Document31 pagesStage 2020Semi Zoghlami100% (1)
- MMC TD1 EstemDocument1 pageMMC TD1 Estemmehdi HEDDAJPas encore d'évaluation
- Comment Trouver Votre Bonheur InterieurDocument58 pagesComment Trouver Votre Bonheur InterieurHawa SyPas encore d'évaluation
- TD2 ElectroDocument3 pagesTD2 Electrorgaibi mohammedPas encore d'évaluation
- Noche Serena - Oda VIII Fray Luis de León FRDocument3 pagesNoche Serena - Oda VIII Fray Luis de León FRNoémie HellerPas encore d'évaluation
- Memoire SammerDocument74 pagesMemoire Sammermathias victorien mbep100% (2)
- 1 PBDocument25 pages1 PBKhalid EzzaheryPas encore d'évaluation
- PDFDocument22 pagesPDFBrayannePas encore d'évaluation
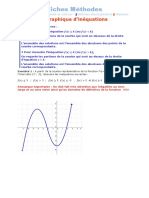
- 2de M Resolution Graphique InequationsDocument8 pages2de M Resolution Graphique InequationsIbrahima Mamadou BaPas encore d'évaluation
- AO Concours National AVIS2 PDFDocument2 pagesAO Concours National AVIS2 PDFAmine TaktakPas encore d'évaluation
- TC Maths Leçon 04 Derivabilite Et Etude de FonctionsDocument24 pagesTC Maths Leçon 04 Derivabilite Et Etude de FonctionsMinsinmo yaya FofanaPas encore d'évaluation
- TD ThermodynamiqueDocument5 pagesTD ThermodynamiqueEmmanuel KingPas encore d'évaluation
- La Nouvelle Triangulation Tunisienne: RésuméDocument30 pagesLa Nouvelle Triangulation Tunisienne: RésuméKhaled Ben MoallemPas encore d'évaluation
- Leadership Incarné, 5 Leçons de Leadership de La Vie de Jésus - Robinson, WilliamDocument114 pagesLeadership Incarné, 5 Leçons de Leadership de La Vie de Jésus - Robinson, WilliamRouah Eagle JeroiPas encore d'évaluation
- Elements de Théorie de Sondage PDFDocument155 pagesElements de Théorie de Sondage PDFMañe Rosendo MaePas encore d'évaluation
- Chapitre 2 Théorie de L'état de ContrainteDocument31 pagesChapitre 2 Théorie de L'état de ContrainteFlëūr D'espoirPas encore d'évaluation
- Cheikh ANTA DIOP - Biographie de Cheikh ANTA DIOP - JeSuisMortDocument5 pagesCheikh ANTA DIOP - Biographie de Cheikh ANTA DIOP - JeSuisMortBabacar Latgrand DioufPas encore d'évaluation
- Algerie Decret 2018 202 Attribution Permis MiniersDocument24 pagesAlgerie Decret 2018 202 Attribution Permis MiniersFarid AkifPas encore d'évaluation
- Gestion Et Contrôle de Projets de ConstructionDocument248 pagesGestion Et Contrôle de Projets de ConstructionAbdellatif ALAHYANEPas encore d'évaluation
- Reprenez Le Controle de Vos Feuilles de Style Avec Sass PDFDocument90 pagesReprenez Le Controle de Vos Feuilles de Style Avec Sass PDFFourier Cédric DanPas encore d'évaluation
- 2007-2008 Corrige Examen Session PrincipaleDocument2 pages2007-2008 Corrige Examen Session PrincipalesumaleePas encore d'évaluation
- Champ Mag FORCE L. L. INDUCT CIRCUIDocument14 pagesChamp Mag FORCE L. L. INDUCT CIRCUImk_garba_dmPas encore d'évaluation