Vous aimerez peut-être aussi
- AAP Chapitre 1Document30 pagesAAP Chapitre 1Gharsellaoui MuhamedPas encore d'évaluation
- Les macros avec OpenOffice CALC: La programmation BASIC pour tousD'EverandLes macros avec OpenOffice CALC: La programmation BASIC pour tousPas encore d'évaluation
- Informatique ParallèleDocument18 pagesInformatique ParallèleNoblaPas encore d'évaluation
- Bien débuter avec SQL: Exercices dans l'interface PhpMyAdmin et MySQLD'EverandBien débuter avec SQL: Exercices dans l'interface PhpMyAdmin et MySQLPas encore d'évaluation
- Corrige 1Document29 pagesCorrige 1Bila100% (1)
- Ado1 5-1Document71 pagesAdo1 5-1Mouad JbelPas encore d'évaluation
- Architecture ParalleleDocument21 pagesArchitecture ParalleleAmine Gigi100% (1)
- Introduction Aux Systèmes À Base de MicrocontroleursDocument3 pagesIntroduction Aux Systèmes À Base de Microcontroleursdubonson30Pas encore d'évaluation
- Chapitre4 PDFDocument44 pagesChapitre4 PDFAmina NouriPas encore d'évaluation
- Leçon N°1: Presentation de L'Informatique Industrielle Et Des Systemes Micro-Programmes I - L'Informatique IndustrielleDocument120 pagesLeçon N°1: Presentation de L'Informatique Industrielle Et Des Systemes Micro-Programmes I - L'Informatique IndustrielleFulbert FissouPas encore d'évaluation
- Chapitre 1 SEDocument6 pagesChapitre 1 SEAmine ElmPas encore d'évaluation
- Cours Microcontrôleurs-Tres ImportantDocument132 pagesCours Microcontrôleurs-Tres ImportantNabil Dakhli0% (1)
- Chapitre 3 - P APIDocument9 pagesChapitre 3 - P APIMohammed ALMUSHIAAPas encore d'évaluation
- Cours Pic 2010 LST IEEADocument40 pagesCours Pic 2010 LST IEEAomarchrifPas encore d'évaluation
- TP Systeme DistribuéDocument2 pagesTP Systeme DistribuéPablo SenePas encore d'évaluation
- Informatique Industrielle 1Document12 pagesInformatique Industrielle 1alainPas encore d'évaluation
- Distributed Parallel Systems-Chapitre2Document164 pagesDistributed Parallel Systems-Chapitre2ZINEBPas encore d'évaluation
- Cao VHDL Mpse PDFDocument99 pagesCao VHDL Mpse PDFInes HattabPas encore d'évaluation
- Cours SM en Ligne-ConvertiDocument72 pagesCours SM en Ligne-ConvertiAnfel CPas encore d'évaluation
- ch1 ch2 STRDocument26 pagesch1 ch2 STRfsmadnenPas encore d'évaluation
- Cours 1 CDA MicroprocesseursDocument18 pagesCours 1 CDA MicroprocesseursYoussef YoussefPas encore d'évaluation
- Cours MicrocontrrolleurDocument65 pagesCours MicrocontrrolleurCrypto Sylvain100% (1)
- 2015 Cours1 Intro MicroDocument4 pages2015 Cours1 Intro MicrobouchenebPas encore d'évaluation
- Nouveau Présentation Microsoft PowerPointDocument22 pagesNouveau Présentation Microsoft PowerPointmaiz100% (1)
- Support Cours Asi IdaDocument78 pagesSupport Cours Asi Idaoboumou100% (2)
- SMI C1 IntroductionDocument17 pagesSMI C1 IntroductionsezonovaldesPas encore d'évaluation
- Chapitre 2 Etudiants Architectures Des P Et C LEA2 Octobre 2023Document17 pagesChapitre 2 Etudiants Architectures Des P Et C LEA2 Octobre 2023maymoun jabnouniPas encore d'évaluation
- Support Cours MicrocontroleursDocument80 pagesSupport Cours MicrocontroleursJrk MukalayPas encore d'évaluation
- IUGET ArchitectureMicroprocesseurDocument21 pagesIUGET ArchitectureMicroprocesseurFabrice FotsoPas encore d'évaluation
- Cours UpDocument9 pagesCours Upram frPas encore d'évaluation
- Cours DSP AB AsmDocument23 pagesCours DSP AB AsmIly'as En-naouiPas encore d'évaluation
- Cours 02Document6 pagesCours 02Wiam KhettabPas encore d'évaluation
- Liste FiguresDocument15 pagesListe Figuresmohamed Amine TiferninePas encore d'évaluation
- Chapter1 DSPDocument76 pagesChapter1 DSPsperatePas encore d'évaluation
- Cours PDFDocument149 pagesCours PDFKnowlegde2016Pas encore d'évaluation
- Introduction À LembarquéDocument82 pagesIntroduction À LembarquéSamira cherifPas encore d'évaluation
- ESE 12 Cha 1 DSPDocument18 pagesESE 12 Cha 1 DSPجعفر زعرور Djaafer ZarourPas encore d'évaluation
- Tres Interessant Syst - C3 - A8mes - C3 - A0 - C2 - B5c - Chapitre1 - 1-MergedDocument55 pagesTres Interessant Syst - C3 - A8mes - C3 - A0 - C2 - B5c - Chapitre1 - 1-MergedbouchenebPas encore d'évaluation
- Chapitre 2 Processeurs EmbarquessDocument15 pagesChapitre 2 Processeurs EmbarquessManissa BelaliaPas encore d'évaluation
- Cours Partie 1 Microprocesseur-2Document6 pagesCours Partie 1 Microprocesseur-2Mrad BelhasenPas encore d'évaluation
- PIC LeçonN°0Document7 pagesPIC LeçonN°0Smart ClassePas encore d'évaluation
- MCIL3 - C - Chapitre 1 - IIDocument5 pagesMCIL3 - C - Chapitre 1 - IITurbo NSXPas encore d'évaluation
- Chapitre 2 Systemes A Base de Microprocesseurs - C2I2S - S1Document29 pagesChapitre 2 Systemes A Base de Microprocesseurs - C2I2S - S1Karym ElhoussinePas encore d'évaluation
- 2 Ao Uf 21 22Document38 pages2 Ao Uf 21 22Ha JarPas encore d'évaluation
- Cours DSPDocument44 pagesCours DSPchfakht100% (1)
- Info - Indus - Chap I - ARCHITECTURE DES SYSTEMES A MICROPROCESSEUR - ISGE - 2ADocument24 pagesInfo - Indus - Chap I - ARCHITECTURE DES SYSTEMES A MICROPROCESSEUR - ISGE - 2AThierry OuedraogoPas encore d'évaluation
- DSP Fpga-1Document43 pagesDSP Fpga-1Chochoo BoumzdPas encore d'évaluation
- Chapitre 1 DSP 2019-2020Document113 pagesChapitre 1 DSP 2019-2020M'hamed Saadi BachirPas encore d'évaluation
- Chapitr 001Document5 pagesChapitr 001oussama bouguerraPas encore d'évaluation
- Travaux Dirigés01Document5 pagesTravaux Dirigés01soltaniPas encore d'évaluation
- Cours ParallelismeDocument63 pagesCours ParallelismeChafik BerdjouhPas encore d'évaluation
- CI & MemoiresDocument14 pagesCI & MemoiresMehdi AmmouPas encore d'évaluation
- Cours 1 ASP GBM3-LMDDocument38 pagesCours 1 ASP GBM3-LMDDONIA JBELI100% (1)
- Traitement Du Signal. DSPDocument45 pagesTraitement Du Signal. DSPIbrahimFaroukSolarPas encore d'évaluation
- Electrotechnique II Specificites Et Caracteristiques Des DSPDocument31 pagesElectrotechnique II Specificites Et Caracteristiques Des DSPOuzennouPas encore d'évaluation
- Micro 02Document19 pagesMicro 02EL Alaoui YoussefPas encore d'évaluation
- Un Microcontrôleur Est Un Circuit Intégré Rassemblant Dans Un Même Boitier Un MicroprocesseurDocument9 pagesUn Microcontrôleur Est Un Circuit Intégré Rassemblant Dans Un Même Boitier Un MicroprocesseuromarPas encore d'évaluation
- Architecture Des Ordinateurs, Les MemoiresDocument20 pagesArchitecture Des Ordinateurs, Les Memoireshiba elouajdiPas encore d'évaluation
- Cours 8 ProcesseursUsageGeneralDocument48 pagesCours 8 ProcesseursUsageGeneralAnass OkhitaPas encore d'évaluation
- Série1.Cmtd Rse 2021-2022Document2 pagesSérie1.Cmtd Rse 2021-2022Yasmine ChihabPas encore d'évaluation
- Architecture Parallèle TD: Université Alger 1 2022/2023 Faculté Des Sciences Département MI M2 RseDocument2 pagesArchitecture Parallèle TD: Université Alger 1 2022/2023 Faculté Des Sciences Département MI M2 RseYasmine ChihabPas encore d'évaluation
- Support Cours MEPS 2022 FADocument8 pagesSupport Cours MEPS 2022 FAYasmine ChihabPas encore d'évaluation
- Cours RDPDocument5 pagesCours RDPYasmine ChihabPas encore d'évaluation
- Support Cours MEPS 2021 Chaines de MarkovDocument9 pagesSupport Cours MEPS 2021 Chaines de MarkovYasmine ChihabPas encore d'évaluation
- Chapitre 5 CapteurDocument36 pagesChapitre 5 CapteurYasmine ChihabPas encore d'évaluation
- Persistance de DonnéesDocument6 pagesPersistance de DonnéesYasmine ChihabPas encore d'évaluation
- Coherence de CacheDocument22 pagesCoherence de CacheYasmine ChihabPas encore d'évaluation
- Ordonnancement 1012Document17 pagesOrdonnancement 1012Yasmine ChihabPas encore d'évaluation
- Architectures ParallelesDocument15 pagesArchitectures ParallelesYasmine ChihabPas encore d'évaluation
- Parallel Is MeDocument139 pagesParallel Is MeYasmine ChihabPas encore d'évaluation
- 10 Anti VirusDocument22 pages10 Anti VirusYasmine ChihabPas encore d'évaluation
- MISDDocument10 pagesMISDYasmine ChihabPas encore d'évaluation
- ENTREPRENARIATDocument10 pagesENTREPRENARIATYasmine ChihabPas encore d'évaluation
- Les ThreadsDocument90 pagesLes ThreadsYasmine ChihabPas encore d'évaluation
- Interface Graphique MobileDocument64 pagesInterface Graphique MobileYasmine ChihabPas encore d'évaluation
- Microsoft PowerPoint - Introduction Au FragmentDocument9 pagesMicrosoft PowerPoint - Introduction Au FragmentYasmine ChihabPas encore d'évaluation
- CommunicationsDocument116 pagesCommunicationsYasmine ChihabPas encore d'évaluation
- Cours 04Document27 pagesCours 04Yasmine ChihabPas encore d'évaluation
- Réseaux de NeuronesDocument27 pagesRéseaux de NeuronesYasmine ChihabPas encore d'évaluation
- La SynchronisationDocument92 pagesLa SynchronisationYasmine ChihabPas encore d'évaluation
- 12 BDDDocument17 pages12 BDDYasmine ChihabPas encore d'évaluation
- La SynchronisationDocument92 pagesLa SynchronisationYasmine ChihabPas encore d'évaluation
- InterfaceDocument16 pagesInterfaceYasmine ChihabPas encore d'évaluation
- 6 - PolitiqueDocument23 pages6 - PolitiqueYasmine ChihabPas encore d'évaluation
- 6 - PolitiqueDocument23 pages6 - PolitiqueYasmine ChihabPas encore d'évaluation
- TP1openssl PDFDocument2 pagesTP1openssl PDFAntonio RodrigoPas encore d'évaluation
- 5 AuthentificationDocument12 pages5 AuthentificationYasmine ChihabPas encore d'évaluation
- 7 - Gestion de RisqueDocument15 pages7 - Gestion de RisqueYasmine Chihab100% (1)
- Unite de StockageDocument13 pagesUnite de StockageNadjib TabaniPas encore d'évaluation
- TD BCT Corrigé v3 FinalDocument30 pagesTD BCT Corrigé v3 FinalCheick Saïd KouroumaPas encore d'évaluation
- Cahier Technique Du Parc InformatiqueDocument8 pagesCahier Technique Du Parc Informatiquenkorounaaudrey3Pas encore d'évaluation
- Chapitre4 InterconnexionsDocument20 pagesChapitre4 InterconnexionsNouhaila AtabetPas encore d'évaluation
- Systeme de Gestion Des FichiersDocument27 pagesSysteme de Gestion Des FichierspenkablessingPas encore d'évaluation
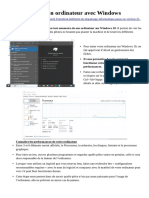
- Tester Son Ordinateur Avec WindowsDocument2 pagesTester Son Ordinateur Avec WindowsWendyPas encore d'évaluation
- Conception LogicielDocument8 pagesConception Logicielwed babaPas encore d'évaluation
- Zynq Cours TP Vivado Zc702Document332 pagesZynq Cours TP Vivado Zc702Mounira TarhouniPas encore d'évaluation
- Désactiver Secure Boot Et Activer Legacy ModeDocument9 pagesDésactiver Secure Boot Et Activer Legacy ModeBrali DIOULSON NGUEMAPas encore d'évaluation
- QCM Ite 6.0 N°6Document5 pagesQCM Ite 6.0 N°6loffy hackerPas encore d'évaluation
- CH 4 HAL Programmation GPIO Par HALDocument46 pagesCH 4 HAL Programmation GPIO Par HALCode CodeurPas encore d'évaluation
- Les VIS CorrigeDocument4 pagesLes VIS CorrigesaidtounektiPas encore d'évaluation
- Le Micro-ProcesseurDocument1 pageLe Micro-ProcesseurFabien LebaigneurPas encore d'évaluation
- Exo Logique Niv1 CorrectionDocument6 pagesExo Logique Niv1 CorrectionDorian Sellier100% (1)
- Structure Des Ordinateurs EpfcDocument63 pagesStructure Des Ordinateurs EpfcTarik El MahtouchiPas encore d'évaluation
- Livre de L'enseignant 2ADocument110 pagesLivre de L'enseignant 2ACharles Steven MbomPas encore d'évaluation
- TP3 RI Laila MoufakkerDocument13 pagesTP3 RI Laila MoufakkerLaila MoufakkerPas encore d'évaluation
- m07 Logiciels+Et+Domaines+d'ApplicationDocument2 pagesm07 Logiciels+Et+Domaines+d'ApplicationdakirPas encore d'évaluation
- Virtualisation - 1Document196 pagesVirtualisation - 1ZAIDAN DIDIPas encore d'évaluation
- Ordinateur 05Document16 pagesOrdinateur 05Mehieddine Asloun100% (1)
- Introduction A La Virtualisation Chap1 (Enregistrement Automatique) - CopieDocument171 pagesIntroduction A La Virtualisation Chap1 (Enregistrement Automatique) - CopieAngélica DEKEPas encore d'évaluation
- Série2 2021Document2 pagesSérie2 2021CAMPUS TIZI OUZOUPas encore d'évaluation
- Plicopié MicroprocesseurDocument114 pagesPlicopié Microprocesseurinstru MentationPas encore d'évaluation
- Chapitre 2 Architecture Des OrdinateursDocument32 pagesChapitre 2 Architecture Des Ordinateursaya ni miniPas encore d'évaluation
- Nettoyage Physique DDocument2 pagesNettoyage Physique DAzedine SariyePas encore d'évaluation
- Chapitre I PDFDocument8 pagesChapitre I PDFIkram ZaghdoudiPas encore d'évaluation
- Chapitre I Architecture Générale de L'unité Centrale D'un OrdinateurDocument22 pagesChapitre I Architecture Générale de L'unité Centrale D'un OrdinateurOuramdanePas encore d'évaluation
- L2 Architecture DordinateurDocument5 pagesL2 Architecture DordinateurMichel MusasaPas encore d'évaluation
- Chapitre 4 - La CommutationDocument2 pagesChapitre 4 - La CommutationBeugre AndrePas encore d'évaluation
- Chapitre 3 - Reseaux WAN Et RouteursDocument17 pagesChapitre 3 - Reseaux WAN Et RouteursDrissa Michael CoulibalyPas encore d'évaluation
- Le trading en ligne facile à apprendre: Comment devenir un trader en ligne et apprendre à investir avec succèsD'EverandLe trading en ligne facile à apprendre: Comment devenir un trader en ligne et apprendre à investir avec succèsÉvaluation : 3.5 sur 5 étoiles3.5/5 (19)
- Dark Python : Apprenez à créer vos outils de hacking.D'EverandDark Python : Apprenez à créer vos outils de hacking.Évaluation : 3 sur 5 étoiles3/5 (1)
- Secrets du Marketing des Médias Sociaux 2021: Conseils et Stratégies Extrêmement Efficaces votre Facebook (Stimulez votre Engagement et Gagnez des Clients Fidèles)D'EverandSecrets du Marketing des Médias Sociaux 2021: Conseils et Stratégies Extrêmement Efficaces votre Facebook (Stimulez votre Engagement et Gagnez des Clients Fidèles)Évaluation : 4 sur 5 étoiles4/5 (2)
- Wi-Fi Hacking avec kali linux Guide étape par étape : apprenez à pénétrer les réseaux Wifi et les meilleures stratégies pour les sécuriserD'EverandWi-Fi Hacking avec kali linux Guide étape par étape : apprenez à pénétrer les réseaux Wifi et les meilleures stratégies pour les sécuriserPas encore d'évaluation
- Python | Programmer pas à pas: Le guide du débutant pour une initiation simple & rapide à la programmationD'EverandPython | Programmer pas à pas: Le guide du débutant pour une initiation simple & rapide à la programmationPas encore d'évaluation
- Apprendre Python rapidement: Le guide du débutant pour apprendre tout ce que vous devez savoir sur Python, même si vous êtes nouveau dans la programmationD'EverandApprendre Python rapidement: Le guide du débutant pour apprendre tout ce que vous devez savoir sur Python, même si vous êtes nouveau dans la programmationPas encore d'évaluation
- WiFi Hacking : Le guide simplifié du débutant pour apprendre le hacking des réseaux WiFi avec Kali LinuxD'EverandWiFi Hacking : Le guide simplifié du débutant pour apprendre le hacking des réseaux WiFi avec Kali LinuxÉvaluation : 3 sur 5 étoiles3/5 (1)
- L'analyse fondamentale facile à apprendre: Le guide d'introduction aux techniques et stratégies d'analyse fondamentale pour anticiper les événements qui font bouger les marchésD'EverandL'analyse fondamentale facile à apprendre: Le guide d'introduction aux techniques et stratégies d'analyse fondamentale pour anticiper les événements qui font bouger les marchésÉvaluation : 3.5 sur 5 étoiles3.5/5 (4)
- Technologie automobile: Les Grands Articles d'UniversalisD'EverandTechnologie automobile: Les Grands Articles d'UniversalisPas encore d'évaluation
- Hacking pour débutants : Le guide complet du débutant pour apprendre les bases du hacking avec Kali LinuxD'EverandHacking pour débutants : Le guide complet du débutant pour apprendre les bases du hacking avec Kali LinuxÉvaluation : 4.5 sur 5 étoiles4.5/5 (4)
- L'analyse technique facile à apprendre: Comment construire et interpréter des graphiques d'analyse technique pour améliorer votre activité de trading en ligne.D'EverandL'analyse technique facile à apprendre: Comment construire et interpréter des graphiques d'analyse technique pour améliorer votre activité de trading en ligne.Évaluation : 3.5 sur 5 étoiles3.5/5 (6)
- Wireshark pour les débutants : Le guide ultime du débutant pour apprendre les bases de l’analyse réseau avec Wireshark.D'EverandWireshark pour les débutants : Le guide ultime du débutant pour apprendre les bases de l’analyse réseau avec Wireshark.Pas encore d'évaluation
- La psychologie du travail facile à apprendre: Le guide d'introduction à l'utilisation des connaissances psychologiques dans le domaine du travail et des organisationsD'EverandLa psychologie du travail facile à apprendre: Le guide d'introduction à l'utilisation des connaissances psychologiques dans le domaine du travail et des organisationsPas encore d'évaluation
- Comment analyser les gens : Introduction à l’analyse du langage corporel et les types de personnalité.D'EverandComment analyser les gens : Introduction à l’analyse du langage corporel et les types de personnalité.Pas encore d'évaluation
- Piraté: Guide Ultime De Kali Linux Et De Piratage Sans Fil Avec Des Outils De Test De SécuritéD'EverandPiraté: Guide Ultime De Kali Linux Et De Piratage Sans Fil Avec Des Outils De Test De SécuritéPas encore d'évaluation
- NFT et Cryptoart: Le guide complet pour investir, créer et vendre avec succès des jetons non fongibles sur le marché de l'art numériqueD'EverandNFT et Cryptoart: Le guide complet pour investir, créer et vendre avec succès des jetons non fongibles sur le marché de l'art numériqueÉvaluation : 5 sur 5 étoiles5/5 (5)
- Le Bon Accord avec le Bon Fournisseur: Comment Mobiliser Toute la Puissance de vos Partenaires Commerciaux pour Réaliser vos ObjectifsD'EverandLe Bon Accord avec le Bon Fournisseur: Comment Mobiliser Toute la Puissance de vos Partenaires Commerciaux pour Réaliser vos ObjectifsÉvaluation : 4 sur 5 étoiles4/5 (2)
- Créer Son Propre Site Internet Et Son Blog GratuitementD'EverandCréer Son Propre Site Internet Et Son Blog GratuitementÉvaluation : 5 sur 5 étoiles5/5 (1)
- Le trading des bandes de bollinger facile à apprendre: Comment apprendre à utiliser les bandes de bollinger pour faire du commerce en ligne avec succèsD'EverandLe trading des bandes de bollinger facile à apprendre: Comment apprendre à utiliser les bandes de bollinger pour faire du commerce en ligne avec succèsÉvaluation : 5 sur 5 étoiles5/5 (1)
- Conception & Modélisation CAO: Le guide ultime du débutantD'EverandConception & Modélisation CAO: Le guide ultime du débutantPas encore d'évaluation
- Explication De La Technologie Blockchain: Guide Ultime Du Débutant Au Sujet Du Portefeuille Blockchain, Mines, Bitcoin, Ripple, EthereumD'EverandExplication De La Technologie Blockchain: Guide Ultime Du Débutant Au Sujet Du Portefeuille Blockchain, Mines, Bitcoin, Ripple, EthereumPas encore d'évaluation
- Guide Pour Les Débutants En Matière De Piratage Informatique: Comment Pirater Un Réseau Sans Fil, Sécurité De Base Et Test De Pénétration, Kali LinuxD'EverandGuide Pour Les Débutants En Matière De Piratage Informatique: Comment Pirater Un Réseau Sans Fil, Sécurité De Base Et Test De Pénétration, Kali LinuxÉvaluation : 1 sur 5 étoiles1/5 (1)
- Le marketing d'affiliation en 4 étapes: Comment gagner de l'argent avec des affiliés en créant des systèmes commerciaux qui fonctionnentD'EverandLe marketing d'affiliation en 4 étapes: Comment gagner de l'argent avec des affiliés en créant des systèmes commerciaux qui fonctionnentPas encore d'évaluation
- Forex Trading facile à apprendre: Le guide d'introduction au marché des changes et aux stratégies de négociation les plus efficaces dans l'industrie des devises.D'EverandForex Trading facile à apprendre: Le guide d'introduction au marché des changes et aux stratégies de négociation les plus efficaces dans l'industrie des devises.Évaluation : 4 sur 5 étoiles4/5 (1)
- La communication professionnelle facile à apprendre: Le guide pratique de la communication professionnelle et des meilleures stratégies de communication d'entrepriseD'EverandLa communication professionnelle facile à apprendre: Le guide pratique de la communication professionnelle et des meilleures stratégies de communication d'entrepriseÉvaluation : 5 sur 5 étoiles5/5 (1)
- Création d'une start-up à succès de A à Z: Réussir votre Start-up 2.0 Web et MobileD'EverandCréation d'une start-up à succès de A à Z: Réussir votre Start-up 2.0 Web et MobileÉvaluation : 3.5 sur 5 étoiles3.5/5 (4)