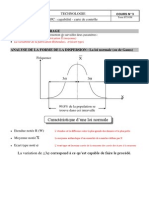
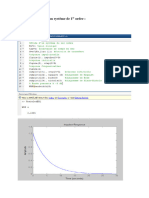
Vous aimerez peut-être aussi
- M Ethodologie de Box Et JenkinsDocument6 pagesM Ethodologie de Box Et Jenkinssoufram1993Pas encore d'évaluation
- TP AsservissementDocument9 pagesTP Asservissementghellai younesPas encore d'évaluation
- Regression LogistiqueDocument7 pagesRegression LogistiqueTourePas encore d'évaluation
- Compte Rendu MatlabDocument35 pagesCompte Rendu MatlabSanae OuferkachPas encore d'évaluation
- Econometrie PanelsDocument67 pagesEconometrie PanelsMØha MédPas encore d'évaluation
- R Cours7Document37 pagesR Cours7Abdo ElmamounPas encore d'évaluation
- Application Des Lois de Probabilité-Variable Aléatoire Continue-Loi NormaleDocument17 pagesApplication Des Lois de Probabilité-Variable Aléatoire Continue-Loi NormaleBMA-medecine100% (2)
- Devoir 1Document21 pagesDevoir 1septimus.pierrePas encore d'évaluation
- Coupe InstantanéeDocument11 pagesCoupe InstantanéeMustaphaKachiche100% (2)
- La Loi NormaleDocument45 pagesLa Loi Normalealpha ASVPPas encore d'évaluation
- Corrigé TD 2Document20 pagesCorrigé TD 2Mohamed BoujnahPas encore d'évaluation
- Maitrise Statistique de ProcedesDocument9 pagesMaitrise Statistique de ProcedesAbdelatif Hr100% (2)
- Hasil SPSSDocument187 pagesHasil SPSSHeldasari SianturiPas encore d'évaluation
- Exam KabbajDocument6 pagesExam KabbajYoussef FahmyPas encore d'évaluation
- Correction Examen AsservissementDocument8 pagesCorrection Examen Asservissementdriss bouycharanPas encore d'évaluation
- Solution TD de Genetique QuantitativeDocument4 pagesSolution TD de Genetique QuantitativePekoJhames08gmail.comPas encore d'évaluation
- ANOVA 2 Facteurs Master FPTDocument14 pagesANOVA 2 Facteurs Master FPTRim AbouttiPas encore d'évaluation
- Modèles Linéaires Généralisés - Régression Logistique: M2 STD - Laurent Léger Exemple - CHDDocument9 pagesModèles Linéaires Généralisés - Régression Logistique: M2 STD - Laurent Léger Exemple - CHDlu luPas encore d'évaluation
- Méthodologie de La Recherche Expérimentale: 'Plans D'expériences'' 'Plans D'expériences''Document42 pagesMéthodologie de La Recherche Expérimentale: 'Plans D'expériences'' 'Plans D'expériences''Lahcen Ait idirPas encore d'évaluation
- Olah DataDocument9 pagesOlah DataNickelNafa GamingPas encore d'évaluation
- Maitrise Que de Procedes 9Document9 pagesMaitrise Que de Procedes 9Ait El Caid AbdellatifPas encore d'évaluation
- Amina MouslihDocument11 pagesAmina MouslihGhoufrane EL MONTASERPas encore d'évaluation
- receuil-Exo-corrigés-Chapitre 1Document14 pagesreceuil-Exo-corrigés-Chapitre 1Samah JabriPas encore d'évaluation
- TD RevDocument16 pagesTD RevHa MZaPas encore d'évaluation
- 379Document12 pages379Mounir FrijaPas encore d'évaluation
- Rendu MatlabDocument12 pagesRendu MatlabIbra YAACOUBIPas encore d'évaluation
- Exemples de RégressionDocument13 pagesExemples de RégressionInsafe AarabPas encore d'évaluation
- Econometri 2019Document4 pagesEconometri 2019Saadaoui MayssaPas encore d'évaluation
- 4 ExamenCorrection Rattrapage 2022 2023 3Document7 pages4 ExamenCorrection Rattrapage 2022 2023 3Oumaima DhbeibiPas encore d'évaluation
- Analyse de L'impact Des Vibrations Sur La Durée de Vie Des Outils de Coupe en TournageDocument4 pagesAnalyse de L'impact Des Vibrations Sur La Durée de Vie Des Outils de Coupe en Tournageait mimounePas encore d'évaluation
- CibleDocument13 pagesCiblelu luPas encore d'évaluation
- PERCOBAAN4Document7 pagesPERCOBAAN4Sahar OfficialPas encore d'évaluation
- Série 3Document1 pageSérie 3Jean Philippe MoroPas encore d'évaluation
- Corrigé Maths BT2Document4 pagesCorrigé Maths BT2VIEUXDANDI100% (1)
- CombinepdfDocument21 pagesCombinepdfMortadha HosniPas encore d'évaluation
- KooooooooooooooooooDocument2 pagesKooooooooooooooooootafrnoutPas encore d'évaluation
- Peak FtirDocument4 pagesPeak FtiragnitaPas encore d'évaluation
- Aguilar Ordaz - Gauss SeidelDocument3 pagesAguilar Ordaz - Gauss SeidelEstefania Guadalupe Aguilar PérezPas encore d'évaluation
- TP2 Signaux Et SystemesDocument10 pagesTP2 Signaux Et Systemesyasser bensedjadPas encore d'évaluation
- Econométrie Des Données de Panel 1Document4 pagesEconométrie Des Données de Panel 1rey.payne12Pas encore d'évaluation
- Devoir ECN2260Document18 pagesDevoir ECN2260sophianebabali.proPas encore d'évaluation
- Asservissement 2Document10 pagesAsservissement 2Sofiane MehadjiPas encore d'évaluation
- Économétrie Appliquée - Estimation D Un VEC Sur EViews Et StataDocument16 pagesÉconométrie Appliquée - Estimation D Un VEC Sur EViews Et StataJessyPas encore d'évaluation
- ExamsDocument7 pagesExamsHaythem MzoughiPas encore d'évaluation
- Corrige Plan ConDocument8 pagesCorrige Plan ConYosra MessaoudiPas encore d'évaluation
- TD Modele Lineaire Gaussien SimpleDocument17 pagesTD Modele Lineaire Gaussien SimpleAbdelaziz BEN KHALIFAPas encore d'évaluation
- Cours Cnam Generalites CaptDocument71 pagesCours Cnam Generalites CaptNoureddinePas encore d'évaluation
- TP GhmbazaDocument7 pagesTP GhmbazaRym OuchaPas encore d'évaluation
- Correction Maths BacD 2010Document9 pagesCorrection Maths BacD 2010Coul Adamo100% (1)
- TP1 MatlabDocument8 pagesTP1 MatlabemmaPas encore d'évaluation
- TP 01Document6 pagesTP 01Męlį SsæPas encore d'évaluation
- Examen Principal Eco 2019-2020Document4 pagesExamen Principal Eco 2019-2020Mariem FourtiPas encore d'évaluation
- لtude sismiqueDocument6 pagesلtude sismiqueAmine Hadj MoussaPas encore d'évaluation
- Tp01 - DerhamouneDocument100 pagesTp01 - Derhamounederhamoune93Pas encore d'évaluation
- Correction Des CasDocument11 pagesCorrection Des CasHalima SadokPas encore d'évaluation
- TD AfcDocument5 pagesTD AfcNisrin AkarPas encore d'évaluation
- Statist Econom Trie AES 1997 Exo 1Document4 pagesStatist Econom Trie AES 1997 Exo 1Irene Petula KolokoPas encore d'évaluation
- ExerciceDocument24 pagesExerciceAbdellatif Elloumi100% (1)
- Logistic 5Document11 pagesLogistic 5lu luPas encore d'évaluation
- Logistic 5Document11 pagesLogistic 5lu luPas encore d'évaluation
- CibleDocument13 pagesCiblelu luPas encore d'évaluation
- Modèles Linéaires Généralisés - Régression Logistique: M2 STD - Laurent Léger Exemple - CHDDocument9 pagesModèles Linéaires Généralisés - Régression Logistique: M2 STD - Laurent Léger Exemple - CHDlu luPas encore d'évaluation
- Programme: UE S3. 1 - Big Data 1: Analyse Des DonnéesDocument1 pageProgramme: UE S3. 1 - Big Data 1: Analyse Des Donnéeslu luPas encore d'évaluation
- Exam M1esa Dec14Document6 pagesExam M1esa Dec14Lambourn VoafidisoaPas encore d'évaluation
- Organisation Et Controle de DonneesDocument15 pagesOrganisation Et Controle de DonneesChaymaa MrharPas encore d'évaluation
- Stat1an06 Principe - Tests Laoussati PDFDocument5 pagesStat1an06 Principe - Tests Laoussati PDFImen MestarPas encore d'évaluation
- Examen 2007 - 2008Document2 pagesExamen 2007 - 2008oujaha100% (1)
- Ajustement Des Débits Moyens AnnuelsDocument7 pagesAjustement Des Débits Moyens AnnuelsferhatiPas encore d'évaluation
- ECS2-05-Série Dexercices N°5 - Statistique Exhaustive Et Information de FisherDocument2 pagesECS2-05-Série Dexercices N°5 - Statistique Exhaustive Et Information de FisherikhlasPas encore d'évaluation
- Rapport TP Modelisation Statistique - Hamza AHBACHDocument27 pagesRapport TP Modelisation Statistique - Hamza AHBACHhamza.ahbachPas encore d'évaluation
- Les Etudes de Cas. de Pierre-Jean BarlatierDocument13 pagesLes Etudes de Cas. de Pierre-Jean BarlatierSami SamPas encore d'évaluation
- ANOVA 1F Didactique Avec Post HocDocument33 pagesANOVA 1F Didactique Avec Post HocmedaliPas encore d'évaluation
- TD Estimation 2020Document14 pagesTD Estimation 2020fouziaPas encore d'évaluation
- Sondage CoursDocument154 pagesSondage CoursMeda100% (1)
- Formulaire StatistiqueDocument15 pagesFormulaire StatistiqueSanae KerzaziPas encore d'évaluation
- Cours - Modélisation-Statistique - Test D - IndépendanceDocument22 pagesCours - Modélisation-Statistique - Test D - IndépendanceTahiri LahcenPas encore d'évaluation
- Statis SI 2020-2021 RésuméDocument178 pagesStatis SI 2020-2021 RésuméabdelwahabPas encore d'évaluation
- Capabilite ProcessDocument32 pagesCapabilite ProcessHadja SavanéPas encore d'évaluation
- CHAP1SER2Document2 pagesCHAP1SER2Eduardo EspinoPas encore d'évaluation
- Etude de Capabilité de Moyen de Mesure1Document10 pagesEtude de Capabilité de Moyen de Mesure1AminChaariPas encore d'évaluation
- Support Du Cours - Modélisation StatistiqueDocument175 pagesSupport Du Cours - Modélisation Statistiquehasna balhassanPas encore d'évaluation