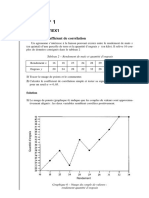
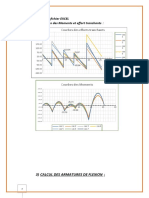
Vous aimerez peut-être aussi
- Bulletin de Lille, 1916-03 Publié sous le contrôle de l'autorité allemandeD'EverandBulletin de Lille, 1916-03 Publié sous le contrôle de l'autorité allemandePas encore d'évaluation
- Malick SeipairDocument2 pagesMalick SeipairMalick GueyePas encore d'évaluation
- Devis PDFDocument1 pageDevis PDFWalter FopaPas encore d'évaluation
- Econometrie Exercices Corriges OptimizeDocument211 pagesEconometrie Exercices Corriges OptimizeDramane CoulibalyPas encore d'évaluation
- ExpériencesDocument27 pagesExpériencesNickolas Gaouette BédardPas encore d'évaluation
- DCE - PJX - CVP - MNT - N6-A - C - Feuille - 112 - PLAN D'IMPLANTATION DES EQUIPEMENTS ET DES RESEAUXDocument1 pageDCE - PJX - CVP - MNT - N6-A - C - Feuille - 112 - PLAN D'IMPLANTATION DES EQUIPEMENTS ET DES RESEAUXTunisianoCAPas encore d'évaluation
- Pass Vec 240209 VEC 2Document6 pagesPass Vec 240209 VEC 2bimleaders.servicesPas encore d'évaluation
- SituaTion DeSTra VauxDocument10 pagesSituaTion DeSTra Vauxmedzo77Pas encore d'évaluation
- مكتبة الارشاد العيونDocument2 pagesمكتبة الارشاد العيونhouria.tarikPas encore d'évaluation
- Corrigé Méthode Chainon TADILIDocument6 pagesCorrigé Méthode Chainon TADILIHassan SaPas encore d'évaluation
- Chap4complet ImpDocument20 pagesChap4complet Impamine boukhedennaPas encore d'évaluation
- Fermator - Instructions de Montage Et Reglage Portes BusDocument12 pagesFermator - Instructions de Montage Et Reglage Portes Busrezgui houssem100% (2)
- LICENCE Ps AIIDocument2 pagesLICENCE Ps AIIrichard mauricePas encore d'évaluation
- Plan D'Electricite D'Appartement + Electricite AutoCAD 2023 ModelDocument15 pagesPlan D'Electricite D'Appartement + Electricite AutoCAD 2023 Modelfatimati0069Pas encore d'évaluation
- Facture EEGCI 0059Document1 pageFacture EEGCI 0059mahprince02Pas encore d'évaluation
- Les Résultats Du Challenge Du NombreDocument3 pagesLes Résultats Du Challenge Du NombreStéphanie ZEIMETPas encore d'évaluation
- Point ProvisoirDocument2 pagesPoint ProvisoirEdjenam SamaniPas encore d'évaluation
- Devis Plomberie Micheal YaoundeDocument4 pagesDevis Plomberie Micheal YaoundeEmmanuel FoyetPas encore d'évaluation
- LMC 001 202112 Fa 01626966Document2 pagesLMC 001 202112 Fa 01626966Chloe MourierPas encore d'évaluation
- Guide Des ProducteursDocument48 pagesGuide Des Producteurshui blablaPas encore d'évaluation
- Les Marchés Financiers La Logique Du HasardDocument256 pagesLes Marchés Financiers La Logique Du HasardmaximesilatchomPas encore d'évaluation
- Electronique-Pratique-105 1987-06Document71 pagesElectronique-Pratique-105 1987-06Jorge AgariePas encore d'évaluation
- Ba 22Document17 pagesBa 22OumarPas encore d'évaluation
- Silos SIV AGRITECHDocument1 pageSilos SIV AGRITECHAnton SozykinPas encore d'évaluation
- Analyse de DonneesDocument12 pagesAnalyse de DonneesNathaniel Van PeeblePas encore d'évaluation
- Poyage Payage Poyage Poyage Poyage Poyage: UnglaisDocument1 pagePoyage Payage Poyage Poyage Poyage Poyage: Unglaisزينب زينبPas encore d'évaluation
- Sin TítuloDocument11 pagesSin TítuloivanbodeantPas encore d'évaluation
- Vetr Rod Exe Arc Det TN 700 0Document111 pagesVetr Rod Exe Arc Det TN 700 0DumoutierPas encore d'évaluation
- Devis Des Materiels Kingabwa 2022Document1 pageDevis Des Materiels Kingabwa 2022Félix EKUKWAPas encore d'évaluation
- Chapitre 2.2Document19 pagesChapitre 2.2nohackplz90Pas encore d'évaluation
- ValoracionDocument1 pageValoracionchafik.benyellesPas encore d'évaluation
- Phénomène de Turbulence: Tp-Sujet 2Document9 pagesPhénomène de Turbulence: Tp-Sujet 2Nabil El haririPas encore d'évaluation
- Copie de Inventaire Magasin Nkomo Valorisé (1) DVFDocument62 pagesCopie de Inventaire Magasin Nkomo Valorisé (1) DVFfridolin sombesPas encore d'évaluation
- Vetr Rod Exe Arc Det TN 800 0Document60 pagesVetr Rod Exe Arc Det TN 800 0DumoutierPas encore d'évaluation
- Valeurs Numeriques UsuellesDocument2 pagesValeurs Numeriques UsuellesazzamPas encore d'évaluation
- Libro Compras y Ventas EsikaDocument2 pagesLibro Compras y Ventas Esikacharlie ubaquiPas encore d'évaluation
- Cegelec Arrosage Lot 3a Att2 JuilletDocument18 pagesCegelec Arrosage Lot 3a Att2 JuilletSouhail HaddadiPas encore d'évaluation
- 999 FRDocument120 pages999 FRCédric LOUISPas encore d'évaluation
- PdM5 SN Guide Corrige Vrac Section4-4Document6 pagesPdM5 SN Guide Corrige Vrac Section4-4stephanePas encore d'évaluation
- 3 Arr SurfaceDocument24 pages3 Arr SurfaceIlyas AissiPas encore d'évaluation
- Electronique Pratique 098 1986 11Document69 pagesElectronique Pratique 098 1986 11Jorge Agarie100% (1)
- Valeur Sondes DaikinDocument1 pageValeur Sondes Daikinrocax99696Pas encore d'évaluation
- City 1500.60Document20 pagesCity 1500.60BareillePas encore d'évaluation
- Aides Associations 2016Document57 pagesAides Associations 2016Breizh InfoPas encore d'évaluation
- Vetr Wma Exe Arc Det TN 000 0Document28 pagesVetr Wma Exe Arc Det TN 000 0DumoutierPas encore d'évaluation
- Devis Du R+1 de Madame BaloDocument2 pagesDevis Du R+1 de Madame Balosouleymane zeye100% (1)
- Projet SeckeDocument3 pagesProjet SeckekarlPas encore d'évaluation
- Facture PT Wijaya Karia NewDocument2 pagesFacture PT Wijaya Karia Newarouf8152Pas encore d'évaluation
- Sites MR BelarbiDocument3 pagesSites MR Belarbicelsio caracciPas encore d'évaluation
- Factura 4031604Document1 pageFactura 4031604bureau valleePas encore d'évaluation
- EX04Document11 pagesEX04andreichirita59Pas encore d'évaluation
- Be BougouniDocument2 pagesBe BougouniMoussa OuédraogoPas encore d'évaluation
- 2023-10 Bulletin de Paie RANDSTAD DIGITAL 0057446-001-001-0057446311020231Document1 page2023-10 Bulletin de Paie RANDSTAD DIGITAL 0057446-001-001-0057446311020231manalmana974Pas encore d'évaluation
- Aco - 02047929 RF 2023Document1 pageAco - 02047929 RF 2023SportsFuture ClubBeniMellalPas encore d'évaluation
- TP 7 - Cinematique Du Mouvement RectiligneDocument4 pagesTP 7 - Cinematique Du Mouvement Rectilignemeriemkroubi2004Pas encore d'évaluation
- Copie de SOLUTION-EXAMEN MP-MSDG-23-24-VDDocument10 pagesCopie de SOLUTION-EXAMEN MP-MSDG-23-24-VDmeryem.sabirPas encore d'évaluation
- Compte Rendu TP2Document6 pagesCompte Rendu TP2Bensalem Mohamed assilPas encore d'évaluation
- Vetr Rod Exe Arc Det TN 600 0Document15 pagesVetr Rod Exe Arc Det TN 600 0DumoutierPas encore d'évaluation
- Amcrps Gen Cat FR 2008 Rev 1 2009Document52 pagesAmcrps Gen Cat FR 2008 Rev 1 2009Elsa TrincalPas encore d'évaluation
- Ru Mar Dce CCTP Lot 01 Gros OeuvreDocument42 pagesRu Mar Dce CCTP Lot 01 Gros OeuvreGwenPas encore d'évaluation
- Comparaison Méthodes SuperviséesDocument18 pagesComparaison Méthodes SuperviséesayoubhaouasPas encore d'évaluation
- Reality About PLSDocument8 pagesReality About PLSayoubhaouasPas encore d'évaluation
- Introduction StataDocument20 pagesIntroduction StataayoubhaouasPas encore d'évaluation
- Introduction StataDocument20 pagesIntroduction StataayoubhaouasPas encore d'évaluation
- Séance 4 - Régression Logistique 7 Avril 2014Document37 pagesSéance 4 - Régression Logistique 7 Avril 2014ayoubhaouasPas encore d'évaluation
- Formation StataDocument60 pagesFormation Stataayoubhaouas100% (1)
- Séance 06Document18 pagesSéance 06ayoubhaouasPas encore d'évaluation
- Séance 6 - Modèle À Double Erreurs ComposéesDocument26 pagesSéance 6 - Modèle À Double Erreurs ComposéesayoubhaouasPas encore d'évaluation
- Séance 5 - Réseaux de Neurones 21 Avril 2014Document30 pagesSéance 5 - Réseaux de Neurones 21 Avril 2014ayoubhaouasPas encore d'évaluation
- Séance 1 - Introduction Données de PanelDocument31 pagesSéance 1 - Introduction Données de PanelayoubhaouasPas encore d'évaluation
- Séance 7 - Tests D'hypothèses en Données de PanelDocument28 pagesSéance 7 - Tests D'hypothèses en Données de PanelayoubhaouasPas encore d'évaluation
- 70 Fiches Pour Préparer Les Epreuves de Culture Générale Et Les QCMDocument139 pages70 Fiches Pour Préparer Les Epreuves de Culture Générale Et Les QCMayoubhaouasPas encore d'évaluation
- Séance 4 - Modèle À Erreurs ComposéesDocument52 pagesSéance 4 - Modèle À Erreurs ComposéesayoubhaouasPas encore d'évaluation
- Cours Analyse Des Données Premiere Annee Master MFBDocument126 pagesCours Analyse Des Données Premiere Annee Master MFBayoubhaouasPas encore d'évaluation
- PFE Original VersionDocument89 pagesPFE Original Versionayoubhaouas100% (1)
- Séance 02Document18 pagesSéance 02ayoubhaouasPas encore d'évaluation
- Séance 05Document24 pagesSéance 05ayoubhaouasPas encore d'évaluation
- CoursSeriesTemp Chap3 PDFDocument11 pagesCoursSeriesTemp Chap3 PDFSauby LongangPas encore d'évaluation
- Données de Panel StataDocument32 pagesDonnées de Panel StataayoubhaouasPas encore d'évaluation
- Régression LogistiqueDocument16 pagesRégression LogistiqueayoubhaouasPas encore d'évaluation
- PFE Original VersionDocument89 pagesPFE Original Versionayoubhaouas100% (1)
- Analyse Financière Des Comptes Consolidés Normes IFRSDocument283 pagesAnalyse Financière Des Comptes Consolidés Normes IFRSOumar Bah100% (4)
- Méthodes de Recherche en RHDocument435 pagesMéthodes de Recherche en RHayoubhaouasPas encore d'évaluation
- Séance 01Document20 pagesSéance 01ayoubhaouasPas encore d'évaluation
- Au Top de La Vente PDFDocument137 pagesAu Top de La Vente PDFayoubhaouasPas encore d'évaluation
- M17 Marketing Strategique AGC TSGEDocument88 pagesM17 Marketing Strategique AGC TSGEhassoube80% (5)
- M17 Marketing Strategique AGC TSGEDocument88 pagesM17 Marketing Strategique AGC TSGEhassoube80% (5)
- L'audit Social - Un Outil D'amélioration de La Qualité Du Pilotage SocialDocument22 pagesL'audit Social - Un Outil D'amélioration de La Qualité Du Pilotage Socialmehdi100% (2)
- 762 PDFDocument15 pages762 PDFayoubhaouasPas encore d'évaluation
- Td5 Lois Statistique Loi BinomialeDocument12 pagesTd5 Lois Statistique Loi BinomialeAyoub HwitéPas encore d'évaluation
- TD 3Document3 pagesTD 3Youssef JabirPas encore d'évaluation
- Coursk PDFDocument51 pagesCoursk PDFDjalal HoucinePas encore d'évaluation
- Exercice N°4-CorrDocument5 pagesExercice N°4-CorrPFEPas encore d'évaluation
- Exercices de Beton PrecontraintDocument6 pagesExercices de Beton Precontraintothman okPas encore d'évaluation
- Copulas TsDocument35 pagesCopulas TskatakitoPas encore d'évaluation
- Afc001final 201215191556Document63 pagesAfc001final 201215191556sihatasnim9Pas encore d'évaluation
- !!!!!!!!!!!!!!!!!!!!!!!!! 1 A Voir Econometrie Des Serie Temporelle !!!!!!!!!!!!!Document70 pages!!!!!!!!!!!!!!!!!!!!!!!!! 1 A Voir Econometrie Des Serie Temporelle !!!!!!!!!!!!!EI Ahmed100% (1)
- TD Est01 2021Document2 pagesTD Est01 2021Anis DjemelPas encore d'évaluation
- Serie 3-CorrectionDocument9 pagesSerie 3-Correctionmouad friginiPas encore d'évaluation
- Partie5 1Document27 pagesPartie5 1Kaoutar SEHLIPas encore d'évaluation
- SArie 1 Modes de Convergence Et ThAorA Me Limites Corriga 2023-2024Document4 pagesSArie 1 Modes de Convergence Et ThAorA Me Limites Corriga 2023-2024sabrina BessalahPas encore d'évaluation
- 7-Variable Aléatoire DiscrétesDocument11 pages7-Variable Aléatoire Discrétesbenba RiadPas encore d'évaluation
- Labarere Jose p04Document26 pagesLabarere Jose p04youness.khalfaouiPas encore d'évaluation
- Notule Grenier 37Document4 pagesNotule Grenier 37verdosPas encore d'évaluation
- Exercice StataDocument25 pagesExercice StataEya LakhdharPas encore d'évaluation
- Chapitre 1Document24 pagesChapitre 1Ayoub AzPas encore d'évaluation
- Examen ADM - ExempleDocument6 pagesExamen ADM - ExempleYasmine EleuchPas encore d'évaluation
- Relations de L'économetrieDocument32 pagesRelations de L'économetrieKarim bouazamaPas encore d'évaluation
- 437 Exercices Faisant Intervenir Des Variables Aléatoires PDFDocument2 pages437 Exercices Faisant Intervenir Des Variables Aléatoires PDFMohamed EL BERKAOUIPas encore d'évaluation
- Formulaire Theo Du SignalDocument7 pagesFormulaire Theo Du Signalinconito111Pas encore d'évaluation
- DECISION STATISTIQUeDocument23 pagesDECISION STATISTIQUeKim NewPas encore d'évaluation
- Correction Des Concours 2011 2019Document36 pagesCorrection Des Concours 2011 2019M100% (8)
- Tests de Normalité Avec RDocument4 pagesTests de Normalité Avec ROlivier OuinaPas encore d'évaluation
- Cours Echantillonnage Et Estimations 1Document105 pagesCours Echantillonnage Et Estimations 1Taoufiq Hadji100% (5)
- Calcul StochastiqueDocument168 pagesCalcul Stochastiques889mkx7jyPas encore d'évaluation
- C 2Document65 pagesC 2nguessan lassiePas encore d'évaluation
- M12 Test Khi 2Document18 pagesM12 Test Khi 2rabemanana.lucPas encore d'évaluation
- Fiabilite Des Strucutures 5Document43 pagesFiabilite Des Strucutures 5aminePas encore d'évaluation
- Probabilité (1) 121939Document17 pagesProbabilité (1) 121939brouedithnoellePas encore d'évaluation
- DELF B1 Production Orale - 150 sujets pour réussirD'EverandDELF B1 Production Orale - 150 sujets pour réussirÉvaluation : 4 sur 5 étoiles4/5 (7)
- Hypnotisme et Magnétisme, Somnambulisme, Suggestion et Télépathie, Influence personnelle: Cours Pratique completD'EverandHypnotisme et Magnétisme, Somnambulisme, Suggestion et Télépathie, Influence personnelle: Cours Pratique completÉvaluation : 4.5 sur 5 étoiles4.5/5 (8)
- Vocabulaire DELF B2 - 300 expressions pour reussirD'EverandVocabulaire DELF B2 - 300 expressions pour reussirÉvaluation : 4 sur 5 étoiles4/5 (7)
- Neuropsychologie: Les bases théoriques et pratiques du domaine d'étude (psychologie pour tous)D'EverandNeuropsychologie: Les bases théoriques et pratiques du domaine d'étude (psychologie pour tous)Pas encore d'évaluation
- Améliorer votre mémoire: Un Guide pour l'augmentation de la puissance du cerveau, utilisant des techniques et méthodesD'EverandAméliorer votre mémoire: Un Guide pour l'augmentation de la puissance du cerveau, utilisant des techniques et méthodesÉvaluation : 5 sur 5 étoiles5/5 (2)
- Géobiologie de l'habitat et Géobiologie sacrée: Pour un lieu sainD'EverandGéobiologie de l'habitat et Géobiologie sacrée: Pour un lieu sainÉvaluation : 4.5 sur 5 étoiles4.5/5 (2)
- Le livre de la mémoire libérée : Apprenez plus vite, retenez tout avec des techniques de mémorisation simples et puissantesD'EverandLe livre de la mémoire libérée : Apprenez plus vite, retenez tout avec des techniques de mémorisation simples et puissantesÉvaluation : 4 sur 5 étoiles4/5 (6)
- Comment développer l’autodiscipline: Résiste aux tentations et atteins tes objectifs à long termeD'EverandComment développer l’autodiscipline: Résiste aux tentations et atteins tes objectifs à long termeÉvaluation : 4.5 sur 5 étoiles4.5/5 (7)
- Introduction à la psychologie des émotions: De Darwin aux neurosciences: découvrir les émotions et leur mode de fonctionnementD'EverandIntroduction à la psychologie des émotions: De Darwin aux neurosciences: découvrir les émotions et leur mode de fonctionnementPas encore d'évaluation
- Aimez-Vous en 12 Étapes Pratiques: Un Manuel pour Améliorer l'Estime de Soi, Prendre Conscience de sa Valeur, se Débarrasser du Doute et Trouver un Bonheur VéritableD'EverandAimez-Vous en 12 Étapes Pratiques: Un Manuel pour Améliorer l'Estime de Soi, Prendre Conscience de sa Valeur, se Débarrasser du Doute et Trouver un Bonheur VéritableÉvaluation : 5 sur 5 étoiles5/5 (4)
- L'Interprétation des rêves de Sigmund Freud: Les Fiches de lecture d'UniversalisD'EverandL'Interprétation des rêves de Sigmund Freud: Les Fiches de lecture d'UniversalisPas encore d'évaluation
- Force Mentale et Maîtrise de la Discipline: Renforcez votre Confiance en vous pour Débloquer votre Courage et votre Résilience ! (Comprend un Manuel Pratique en 10 Étapes et 15 Puissants Exercices)D'EverandForce Mentale et Maîtrise de la Discipline: Renforcez votre Confiance en vous pour Débloquer votre Courage et votre Résilience ! (Comprend un Manuel Pratique en 10 Étapes et 15 Puissants Exercices)Évaluation : 4.5 sur 5 étoiles4.5/5 (28)
- Anglais ( L’Anglais Facile a Lire ) 400 Mots Fréquents (4 Livres en 1 Super Pack): 400 mots fréquents en anglais expliqués en français avec texte bilingueD'EverandAnglais ( L’Anglais Facile a Lire ) 400 Mots Fréquents (4 Livres en 1 Super Pack): 400 mots fréquents en anglais expliqués en français avec texte bilingueÉvaluation : 5 sur 5 étoiles5/5 (2)
- Le fa, entre croyances et science: Pour une epistemologie des savoirs africainsD'EverandLe fa, entre croyances et science: Pour une epistemologie des savoirs africainsÉvaluation : 3.5 sur 5 étoiles3.5/5 (6)
- Anglais Pour Les Nulles - Livre Anglais Français Facile A Lire: 50 dialogues facile a lire et photos de los Koalas pour apprendre anglais vocabulaireD'EverandAnglais Pour Les Nulles - Livre Anglais Français Facile A Lire: 50 dialogues facile a lire et photos de los Koalas pour apprendre anglais vocabulaireÉvaluation : 5 sur 5 étoiles5/5 (1)
- DELF B2 Production Orale - Méthode complète pour réussirD'EverandDELF B2 Production Orale - Méthode complète pour réussirÉvaluation : 4 sur 5 étoiles4/5 (5)
- Réfléchissez et devenez riche: Le grand livre de l’esprit maîtreD'EverandRéfléchissez et devenez riche: Le grand livre de l’esprit maîtreÉvaluation : 4 sur 5 étoiles4/5 (509)
- DELF B1 - Production Orale - 2800 mots pour réussirD'EverandDELF B1 - Production Orale - 2800 mots pour réussirÉvaluation : 4.5 sur 5 étoiles4.5/5 (12)
- Vocabulaire DELF B2 - 3000 mots pour réussirD'EverandVocabulaire DELF B2 - 3000 mots pour réussirÉvaluation : 4.5 sur 5 étoiles4.5/5 (34)
- Manipulation et Persuasion: Apprenez à influencer le comportement humain, la psychologie noire, l'hypnose, le contrôle mental et l'analyse des personnes.D'EverandManipulation et Persuasion: Apprenez à influencer le comportement humain, la psychologie noire, l'hypnose, le contrôle mental et l'analyse des personnes.Évaluation : 4.5 sur 5 étoiles4.5/5 (13)
- le vocabulaire anglais pour comprendre 80% des conversations: parlez et comprendre l'anglaisD'Everandle vocabulaire anglais pour comprendre 80% des conversations: parlez et comprendre l'anglaisÉvaluation : 5 sur 5 étoiles5/5 (2)
- Le TDA/H chez l'adulte: Apprendre à vivre sereinement avec son trouble de l'attentionD'EverandLe TDA/H chez l'adulte: Apprendre à vivre sereinement avec son trouble de l'attentionPas encore d'évaluation
- Apprendre l’allemand - Texte parallèle - Collection drôle histoire (Français - Allemand)D'EverandApprendre l’allemand - Texte parallèle - Collection drôle histoire (Français - Allemand)Évaluation : 3.5 sur 5 étoiles3.5/5 (2)