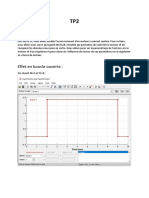
Vous aimerez peut-être aussi
- Analyse Mathématique pour l'ingénieur: Analyse Mathématique pour l'ingénieur, #2D'EverandAnalyse Mathématique pour l'ingénieur: Analyse Mathématique pour l'ingénieur, #2Pas encore d'évaluation
- TP MatlabDocument29 pagesTP Matlabmed84% (19)
- 1 s2.0 S1631073X17301450 Main - 2Document7 pages1 s2.0 S1631073X17301450 Main - 2Mahendra PerdanaPas encore d'évaluation
- TP2 El Mariky Salim, Glandieres Louis, Habre KarlDocument7 pagesTP2 El Mariky Salim, Glandieres Louis, Habre KarlSalim El MarikyPas encore d'évaluation
- Boukhris Marrakech 98Document4 pagesBoukhris Marrakech 98Hicham FouraijiPas encore d'évaluation
- Compte Rendu MatlabDocument29 pagesCompte Rendu MatlabHana ElPas encore d'évaluation
- HTML To PDFDocument13 pagesHTML To PDFMerou ndiayePas encore d'évaluation
- Algo Handout Etudiants 15Document144 pagesAlgo Handout Etudiants 15calabi mozartPas encore d'évaluation
- DLPDocument34 pagesDLPYu KikoPas encore d'évaluation
- Ilide - Info TP Matlab PRDocument29 pagesIlide - Info TP Matlab PRAbdoulaye baPas encore d'évaluation
- Cour Stat Edgdrn2021 Part2Document9 pagesCour Stat Edgdrn2021 Part2zosamoela4Pas encore d'évaluation
- Amphi 1 Resume Optimisation Et Analyse NumeriqueDocument45 pagesAmphi 1 Resume Optimisation Et Analyse NumeriqueFrank FacundoPas encore d'évaluation
- Compte Rendu Auto - CopieDocument18 pagesCompte Rendu Auto - CopieHanae MenounyPas encore d'évaluation
- TP 2 Version FinaleDocument12 pagesTP 2 Version FinaleZH HamzaPas encore d'évaluation
- Chapitre 2 - (Modèles ARMA Et ARIMA - )Document25 pagesChapitre 2 - (Modèles ARMA Et ARIMA - )adivelmycryPas encore d'évaluation
- TP3 Estimation CorrigeDocument14 pagesTP3 Estimation CorrigeElise fvPas encore d'évaluation
- TP 1 Version FinaleDocument10 pagesTP 1 Version FinaleZH HamzaPas encore d'évaluation
- Chapitreiintroductionetmotivations 140116154906 Phpapp01Document16 pagesChapitreiintroductionetmotivations 140116154906 Phpapp01zaki nygmaPas encore d'évaluation
- Travaux Pratiques de Traitement Du Signal Avancé: Filtrage AdaptatifDocument33 pagesTravaux Pratiques de Traitement Du Signal Avancé: Filtrage AdaptatifazizPas encore d'évaluation
- C Auto AnalyseDocument38 pagesC Auto AnalyseBerragouba BerragoubaPas encore d'évaluation
- تيبي 1عيباش ماستار دو - CopieDocument9 pagesتيبي 1عيباش ماستار دو - CopieMohamed AminePas encore d'évaluation
- TP 1 A RendreDocument6 pagesTP 1 A RendreDia Mouhamadou NabyPas encore d'évaluation
- TD01 Test Et ValidationDocument2 pagesTD01 Test Et Validationkhaled19lmdPas encore d'évaluation
- TP2 A RendreDocument5 pagesTP2 A RendreDia Mouhamadou NabyPas encore d'évaluation
- TP Identif 2018 QDocument14 pagesTP Identif 2018 QHichaam EnaPas encore d'évaluation
- TP2 Signaux Et SystemesDocument10 pagesTP2 Signaux Et Systemesyasser bensedjadPas encore d'évaluation
- Master TheoremDocument14 pagesMaster TheoremCOMBAGNI TVPas encore d'évaluation
- Utomatique Ravaux Pratiques Éance N: 1 Réponse ImpulsionnelleDocument4 pagesUtomatique Ravaux Pratiques Éance N: 1 Réponse ImpulsionnellePRIMEMYTHOPas encore d'évaluation
- Dsge PDFDocument36 pagesDsge PDFseydinaPas encore d'évaluation
- Serie TP Hydro Infor 1Document7 pagesSerie TP Hydro Infor 1Hammou MorsliPas encore d'évaluation
- C Auto AnalyseDocument39 pagesC Auto Analysesouad laribiPas encore d'évaluation
- Chapitre 1 ComplexiteDocument15 pagesChapitre 1 ComplexiteÅýå ŔîfîPas encore d'évaluation
- Series ChronologiquesDocument14 pagesSeries ChronologiquesMaria Amina100% (1)
- TP AutomatiqueDocument14 pagesTP AutomatiqueMANAL ALILOUPas encore d'évaluation
- TP1 AutomatiqueDocument29 pagesTP1 AutomatiqueMaryPas encore d'évaluation
- ComplexitéDocument27 pagesComplexitéYves JordanPas encore d'évaluation
- Lesmodles ARDLDocument18 pagesLesmodles ARDLBIENVENU ALIMASIPas encore d'évaluation
- Chapitre III GraphesDocument18 pagesChapitre III GraphesjamilaPas encore d'évaluation
- Presentation 2 1Document25 pagesPresentation 2 1Imane GhanouPas encore d'évaluation
- Polycope Commande Optimaleet Prdective 2019Document70 pagesPolycope Commande Optimaleet Prdective 2019Oussama LazebPas encore d'évaluation
- Electronique Numerique 1Document121 pagesElectronique Numerique 1guyguychouPas encore d'évaluation
- Be Maer Projet Cim PaDocument20 pagesBe Maer Projet Cim PaMahamat Saleh Idriss IbrahimPas encore d'évaluation
- SLCI RevisionsDocument9 pagesSLCI RevisionsKais BahrouniPas encore d'évaluation
- Exer Corrigés RLMDocument6 pagesExer Corrigés RLMNajwa LakhalPas encore d'évaluation
- (TP7) Problème Stationnaire-Dichotomie2Document11 pages(TP7) Problème Stationnaire-Dichotomie2ochifarnckPas encore d'évaluation
- ModsimDocument16 pagesModsimHanene Kohinoor BrahmiaPas encore d'évaluation
- Compte Rendu TP4 CSDDocument9 pagesCompte Rendu TP4 CSDRyzeFrodexPas encore d'évaluation
- CC2 2022 2023Document2 pagesCC2 2022 2023kouassi A. Nathan EBROTIEPas encore d'évaluation
- RapportDocument7 pagesRapportYassine ZitouniPas encore d'évaluation
- Cours 2Document104 pagesCours 2vcklthgcghjlcPas encore d'évaluation
- Intro DeepLearningDocument51 pagesIntro DeepLearningDr. Chekir AmiraPas encore d'évaluation
- Sujet AUT104Document3 pagesSujet AUT104Oussama SadkiPas encore d'évaluation
- Chap2 Regression Logi ClassDocument27 pagesChap2 Regression Logi ClassImane LOUKILIPas encore d'évaluation
- Correction A 12Document17 pagesCorrection A 12Amine AzaoumPas encore d'évaluation
- TP3 Sys EchantDocument33 pagesTP3 Sys Echantamal mezliniPas encore d'évaluation
- P: P - TSP: Rojet Roblème Du Voyageur de CommerceDocument13 pagesP: P - TSP: Rojet Roblème Du Voyageur de Commercelicia attouchePas encore d'évaluation
- Suppression des lignes cachées: Dévoiler l'invisible : les secrets de la vision par ordinateurD'EverandSuppression des lignes cachées: Dévoiler l'invisible : les secrets de la vision par ordinateurPas encore d'évaluation
- Coupes de graphiques de vision par ordinateur: Explorer les coupes graphiques en vision par ordinateurD'EverandCoupes de graphiques de vision par ordinateur: Explorer les coupes graphiques en vision par ordinateurPas encore d'évaluation
- Les Règles D'associationDocument55 pagesLes Règles D'associationKaouther BenaliPas encore d'évaluation
- Examen Codage Compression M1 2019Document2 pagesExamen Codage Compression M1 2019ranacheurfaPas encore d'évaluation
- Examen S2 2018 2019Document4 pagesExamen S2 2018 2019Amir HamzaPas encore d'évaluation
- TD 4Document9 pagesTD 4likePas encore d'évaluation
- FIltrage Amelioration TraitementDocument63 pagesFIltrage Amelioration TraitementRiad BachaPas encore d'évaluation
- Exercices Complementaires - Chapitreno5 - Les Polynomes - Premiere Partie - CorrigeDocument5 pagesExercices Complementaires - Chapitreno5 - Les Polynomes - Premiere Partie - CorrigeKhemais AbdallahPas encore d'évaluation
- 19 Degre 3 TMDocument4 pages19 Degre 3 TMMouhamadou NiangPas encore d'évaluation
- Corrigé de La Série2Document3 pagesCorrigé de La Série2Ikram DahmaniPas encore d'évaluation
- GELE5313 Notes5Document8 pagesGELE5313 Notes5Hadia DjeltiPas encore d'évaluation
- Optimisation NumériqueDocument32 pagesOptimisation Numériquesalah erreddafPas encore d'évaluation
- Séance 8Document47 pagesSéance 8Laaouissi AzedPas encore d'évaluation
- 4-Algo (Récursivité)Document51 pages4-Algo (Récursivité)farah AfouzarPas encore d'évaluation
- Examen Classification Dec2018Document3 pagesExamen Classification Dec2018Nadia BeraknaPas encore d'évaluation
- TP N-2 Systèmes À Temps Discret Sous MATLABDocument17 pagesTP N-2 Systèmes À Temps Discret Sous MATLABYabilMurcerPas encore d'évaluation
- TP Codage Et Compression Boukenadil PDFDocument10 pagesTP Codage Et Compression Boukenadil PDFAyoushi آيوشيPas encore d'évaluation
- Série Dexercices 01Document2 pagesSérie Dexercices 01vbzrgPas encore d'évaluation
- Elements FinisDocument56 pagesElements Finistopjob100% (1)
- InterpolationDocument40 pagesInterpolationkhalladi mustaphaPas encore d'évaluation
- Codes BarresDocument8 pagesCodes BarresYoucef MimouniPas encore d'évaluation
- Chap - 2 Chapitre Numérisation Des Signaux Vidéo Et AudioDocument7 pagesChap - 2 Chapitre Numérisation Des Signaux Vidéo Et AudioradjaaPas encore d'évaluation
- 4-MIC4220 Trans Fourier ZDocument26 pages4-MIC4220 Trans Fourier ZSouhaib LoudaPas encore d'évaluation
- Notes de Cours ELN2 SMP5Document56 pagesNotes de Cours ELN2 SMP5mohamedPas encore d'évaluation
- CoursSEL2 PDFDocument150 pagesCoursSEL2 PDFEssaid AjanaPas encore d'évaluation
- TD 5: Les Tris: 1. Le Plus PetitDocument4 pagesTD 5: Les Tris: 1. Le Plus PetitKaouther BenaliPas encore d'évaluation
- TP-Représentation D'etatDocument9 pagesTP-Représentation D'etatKooraNow HDPas encore d'évaluation
- Erreur Et ChecksumDocument5 pagesErreur Et Checksumboroy12121Pas encore d'évaluation
- Calcul Dans EXCELDocument17 pagesCalcul Dans EXCELSamira BouslimPas encore d'évaluation
- Cours CodageCanal2Document114 pagesCours CodageCanal2ceczczcPas encore d'évaluation
- L04 Les FiltresDocument6 pagesL04 Les FiltresYoussef YoussefPas encore d'évaluation
- Les Algorithmes Cryptographiques Asymétriques: Omar CheikhrouhouDocument36 pagesLes Algorithmes Cryptographiques Asymétriques: Omar CheikhrouhouAmel EspoirPas encore d'évaluation