
Abdrahmane AW Master II
Abdrahmane AW Master II
Vous aimerez peut-être aussi
- Rappport de Stage EspritDocument31 pagesRappport de Stage EspritRaed Bejaoui100% (2)
- Rapport de Stage - Administration Réseau Et Dévéloppement WebDocument41 pagesRapport de Stage - Administration Réseau Et Dévéloppement Webnajm3dPas encore d'évaluation
- Rapport de Stage - Akli Wisseme - Nouar Rania ManelDocument33 pagesRapport de Stage - Akli Wisseme - Nouar Rania ManelMouna AmmaliPas encore d'évaluation
- Gestion Demploi Du Temps Des SoutenancesDocument39 pagesGestion Demploi Du Temps Des Soutenancesachref bouadilaPas encore d'évaluation
- Rapport PFE 2019 Final PDFDocument95 pagesRapport PFE 2019 Final PDFHamzaChouChéne100% (1)
- ESTM - Rapport Externe - Master Teleinnformatique - À PublierDocument21 pagesESTM - Rapport Externe - Master Teleinnformatique - À PublierSouley LyPas encore d'évaluation
- TLILI GhadaDocument92 pagesTLILI GhadaDestinPas encore d'évaluation
- Conception Système de Gestion Des ÉtablissementsDocument120 pagesConception Système de Gestion Des ÉtablissementsHassamPas encore d'évaluation
- Memoire Finale 3Document75 pagesMemoire Finale 3josianesage1Pas encore d'évaluation
- EntreprenariatDocument29 pagesEntreprenariatwakeurboromsam mbackéPas encore d'évaluation
- Projet s4Document21 pagesProjet s421514Pas encore d'évaluation
- Rapport FinalDocument64 pagesRapport FinalHiba Aissaoui IdrissiPas encore d'évaluation
- MemoireDocument77 pagesMemoireAHMED LEHYANI100% (1)
- Rapport El Alaoui Imane Version Finale WordDocument102 pagesRapport El Alaoui Imane Version Finale WordAISSI RIHABPas encore d'évaluation
- Referentiel Developpement SI CAMES PDFDocument116 pagesReferentiel Developpement SI CAMES PDFCEFOPAMPas encore d'évaluation
- MehdyDocument72 pagesMehdyCrazy movisePas encore d'évaluation
- MEDDAH MustaphaDocument50 pagesMEDDAH Mustaphadev cPas encore d'évaluation
- Lawali RabiouDocument24 pagesLawali RabiouLawali Rabiou BinaddoPas encore d'évaluation
- Orca Share Media1663072180177 6975430297608539328Document51 pagesOrca Share Media1663072180177 6975430297608539328Andriamihaja RASOANARIVOPas encore d'évaluation
- Sow Mémoire 2022Document67 pagesSow Mémoire 2022Mamadou NiangPas encore d'évaluation
- Rapport de StageDocument32 pagesRapport de StageMonassir Mohamed Charaf100% (3)
- Mémoire Letembet ChrysDocument141 pagesMémoire Letembet Chrysnfinda ivanPas encore d'évaluation
- Stage-Pfe Dut JouhalDocument27 pagesStage-Pfe Dut JouhalkhadijaPas encore d'évaluation
- Mamadou Bhoye Diallo Memoire Final v1Document95 pagesMamadou Bhoye Diallo Memoire Final v1Aboubacry KANEPas encore d'évaluation
- ACFrOgBUXT-zNE441K5Cah-esHaCilYUcc9WyO1kMgHoE1pyw0 CXM HDwb9sxQhnYXEtMCAxWnojvV8GyfJGDlsXqVwhDzxeASKVFT42g2MbRhY7 nhOrYI pVrC6sDocument72 pagesACFrOgBUXT-zNE441K5Cah-esHaCilYUcc9WyO1kMgHoE1pyw0 CXM HDwb9sxQhnYXEtMCAxWnojvV8GyfJGDlsXqVwhDzxeASKVFT42g2MbRhY7 nhOrYI pVrC6sFRANCK OLIVIERPas encore d'évaluation
- Soutenance Licence ProDocument61 pagesSoutenance Licence Proeaka4016Pas encore d'évaluation
- Rapport JavaDocument16 pagesRapport JavaOussama MoustarzikPas encore d'évaluation
- Rapport Stage Licence Genie Informatique 2009Document80 pagesRapport Stage Licence Genie Informatique 2009Larbi AmranePas encore d'évaluation
- Rapport de Stage - RAMDocument53 pagesRapport de Stage - RAMABAASOUF100% (3)
- RapportNewFinalCopieMed KlibiDocument79 pagesRapportNewFinalCopieMed KlibiAymen TouihriPas encore d'évaluation
- DIC - 2012 - Conception Et Réalisation D́un Framework Pour Le Développement de Systèmes de Réservation en LigneDocument103 pagesDIC - 2012 - Conception Et Réalisation D́un Framework Pour Le Développement de Systèmes de Réservation en LigneSamirSaSamirPas encore d'évaluation
- Cours GED Stagaire Ver 9Document50 pagesCours GED Stagaire Ver 9obob9058Pas encore d'évaluation
- Rapport - PFE - Gestion de Stock - SEMMANEDocument51 pagesRapport - PFE - Gestion de Stock - SEMMANEOmar El Mejnaoui80% (5)
- Guide de L'étudiant - EPT - 2023Document17 pagesGuide de L'étudiant - EPT - 2023khadimdadocoumbaPas encore d'évaluation
- DHET - Mémoire Stage Certification QSE Roullier - Auteur Lucas TernynckDocument48 pagesDHET - Mémoire Stage Certification QSE Roullier - Auteur Lucas TernynckAbdellah EL MOUATASSIMPas encore d'évaluation
- DeschênesDocument124 pagesDeschênesLaila LailaPas encore d'évaluation
- Pfe RareDocument97 pagesPfe RareSimo Azrou0% (1)
- Rapport de Stage Anadi JacquelineDocument47 pagesRapport de Stage Anadi Jacquelineellamassinou007Pas encore d'évaluation
- PFE MOPIL Maintenance AMDEC Yasmine HAJJAJI 2020Document101 pagesPFE MOPIL Maintenance AMDEC Yasmine HAJJAJI 2020hajri BouthainaPas encore d'évaluation
- Conception Et Implémentation D'une Application de Suivie Du Parc InformatiqueDocument26 pagesConception Et Implémentation D'une Application de Suivie Du Parc InformatiqueElisabete Grasia AminaPas encore d'évaluation
- PFEL3Document43 pagesPFEL3Bouthaina MezgPas encore d'évaluation
- Rapport Dossier D'ese BMCEDocument67 pagesRapport Dossier D'ese BMCEMohammed RissaliPas encore d'évaluation
- Redaction de Mon Rapport de StageDocument51 pagesRedaction de Mon Rapport de StageNianmissou Mienwa100% (1)
- Mise en Place D'un Réseau EthernetDocument66 pagesMise en Place D'un Réseau EthernetJames Ulrich100% (1)
- FormationsDocument212 pagesFormationswinrak ddnsPas encore d'évaluation
- Rapport de Visite Yazaki Mohamed OUBIKHIRDocument6 pagesRapport de Visite Yazaki Mohamed OUBIKHIRmohamed.oubikhirPas encore d'évaluation
- Rapport PFE Asbayo HamzaDocument59 pagesRapport PFE Asbayo HamzaHamza AsbaYoPas encore d'évaluation
- Etude Et Mise en Place D'une S - Mohamed FARTITCHOU - 2743 PDFDocument121 pagesEtude Et Mise en Place D'une S - Mohamed FARTITCHOU - 2743 PDFSébastien OuédraogoPas encore d'évaluation
- Rapport de StageDocument19 pagesRapport de Stageimane amimiPas encore d'évaluation
- Memoire de Magister HacianeDocument144 pagesMemoire de Magister HacianezaghdoudiPas encore d'évaluation
- Rapport de Stage (Faculté Des Sciences Oujda)Document27 pagesRapport de Stage (Faculté Des Sciences Oujda)187med100% (1)
- .Archivetemprapport de Stage PFE (Benkacem - Med)Document82 pages.Archivetemprapport de Stage PFE (Benkacem - Med)Khaoula RAZZAKIPas encore d'évaluation
- Knowledge Management Et E-Learning Quelle ConvergenceDocument37 pagesKnowledge Management Et E-Learning Quelle ConvergenceSahbi DkhiliPas encore d'évaluation
- Rapport de Fin D Étude - Licences SIID - Hind AMARADocument26 pagesRapport de Fin D Étude - Licences SIID - Hind AMARASelma EsbPas encore d'évaluation
- Rapport de Stage AWSM Faraji-FenoDocument73 pagesRapport de Stage AWSM Faraji-Fenohamza elgarragPas encore d'évaluation
- Conception Developpement Site Web e Commerce Compte LSAT NokiaDocument73 pagesConception Developpement Site Web e Commerce Compte LSAT NokiaZakaria Tal100% (2)
- Mise en Place D'un IntranetDocument93 pagesMise en Place D'un IntranetLarissa FifalianaPas encore d'évaluation
- Realisation D'une Plateforme E-Commerce Pour Les Sites Commerciaux - Akkioui Younes - Fassih MarwaneDocument50 pagesRealisation D'une Plateforme E-Commerce Pour Les Sites Commerciaux - Akkioui Younes - Fassih MarwaneAL CHARIF0% (1)
- Guide Choisir - Collégial 2024: 36e édition - Toute l'information sur les formations collégiales (DEC, DEC-BAC et passerelles)D'EverandGuide Choisir - Collégial 2024: 36e édition - Toute l'information sur les formations collégiales (DEC, DEC-BAC et passerelles)Pas encore d'évaluation
- L' Appréciation des performances au travail: De l'individu à l'équipeD'EverandL' Appréciation des performances au travail: De l'individu à l'équipeÉvaluation : 5 sur 5 étoiles5/5 (1)
- Support TP Inf4048Document29 pagesSupport TP Inf4048Jean Louis Mélanie NdaguiPas encore d'évaluation
- TD TP PHPDocument6 pagesTD TP PHPSafae BelkhyrPas encore d'évaluation
- PageSpeed Insights 21 Janvier 2024 DesktopDocument8 pagesPageSpeed Insights 21 Janvier 2024 Desktopkyo007Pas encore d'évaluation
- Windows Server 2022 Administration Initiation Approfondissement PDFDocument4 pagesWindows Server 2022 Administration Initiation Approfondissement PDFmamadou dialloPas encore d'évaluation
- TD ProcessusDocument8 pagesTD ProcessusKhadija HaddaouiPas encore d'évaluation
- Ateliers 1 & 2 - BDDocument17 pagesAteliers 1 & 2 - BDHouneida HaddajiPas encore d'évaluation
- BC402 4.6a FRDocument246 pagesBC402 4.6a FRmhalcan1Pas encore d'évaluation
- Cours PHP ExceptionDocument40 pagesCours PHP Exceptionlosus007Pas encore d'évaluation
- QCM Si 2012 Ogi v1 CorrectionDocument4 pagesQCM Si 2012 Ogi v1 Correctioncoyote41Pas encore d'évaluation
- Institut Superieur D'Informatique Et de Gestion: Republique Democratique Du CongoDocument129 pagesInstitut Superieur D'Informatique Et de Gestion: Republique Democratique Du CongoHéritier KangelaPas encore d'évaluation
- User FormDocument23 pagesUser FormLa SadPas encore d'évaluation
- Iban FRDocument1 pageIban FRjacques.clotPas encore d'évaluation
- fb60 BapiDocument7 pagesfb60 BapiashwinPas encore d'évaluation
- Installation Et Configuration de Windows Server 2012 - 2016Document8 pagesInstallation Et Configuration de Windows Server 2012 - 2016FabouKoulibalyPas encore d'évaluation
- Gestion Des Reclamations Et de - Boukhriss Zouhair - 1443Document33 pagesGestion Des Reclamations Et de - Boukhriss Zouhair - 1443Naspr100% (1)
- TP 2Document2 pagesTP 2jouililiPas encore d'évaluation
- Java de BaseDocument126 pagesJava de BaseMoussa SyPas encore d'évaluation
- Java EE - TP 1 (Corrige)Document4 pagesJava EE - TP 1 (Corrige)Merniz Abdelkader100% (1)
- TP4 Curseur ExceptionDocument2 pagesTP4 Curseur ExceptionAdda Issa Abdoul RazakPas encore d'évaluation
- Developpeur Web - OpenclassroomDocument24 pagesDeveloppeur Web - OpenclassroomsefPas encore d'évaluation
- Partie 1 Up ProDocument13 pagesPartie 1 Up Projean5no5l5kangaPas encore d'évaluation
- TP 2 CorrectionDocument2 pagesTP 2 CorrectionMili GiliPas encore d'évaluation
- Dynamisez Vos Sites Avec JavaScriptDocument1 pageDynamisez Vos Sites Avec JavaScriptMartine KenfackPas encore d'évaluation
- Notions de Base en Java (Partie 1)Document94 pagesNotions de Base en Java (Partie 1)YassminaPas encore d'évaluation
- Slides Integration ContinueDocument22 pagesSlides Integration ContinueReda CZPas encore d'évaluation
- Chapitre IDocument102 pagesChapitre Iهداية مسلمةPas encore d'évaluation
- Cours Procedures Et FonctionsDocument11 pagesCours Procedures Et FonctionsChristian EhouanouPas encore d'évaluation
- Les FichiersDocument3 pagesLes Fichiersaicha GuefrachiPas encore d'évaluation
- Cours Et Exemples de Fonctions PHPDocument5 pagesCours Et Exemples de Fonctions PHPAyoub AcresPas encore d'évaluation
- Chapitre2 JavaFxDocument70 pagesChapitre2 JavaFxgaming for funPas encore d'évaluation






























































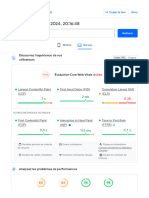



























Télécharger au format pdf ou txt
Vous aimerez peut-être aussi
- Rappport de Stage EspritDocument31 pagesRappport de Stage EspritRaed Bejaoui100% (2)
- Rapport de Stage - Administration Réseau Et Dévéloppement WebDocument41 pagesRapport de Stage - Administration Réseau Et Dévéloppement Webnajm3dPas encore d'évaluation
- Rapport de Stage - Akli Wisseme - Nouar Rania ManelDocument33 pagesRapport de Stage - Akli Wisseme - Nouar Rania ManelMouna AmmaliPas encore d'évaluation
- Gestion Demploi Du Temps Des SoutenancesDocument39 pagesGestion Demploi Du Temps Des Soutenancesachref bouadilaPas encore d'évaluation
- Rapport PFE 2019 Final PDFDocument95 pagesRapport PFE 2019 Final PDFHamzaChouChéne100% (1)
- ESTM - Rapport Externe - Master Teleinnformatique - À PublierDocument21 pagesESTM - Rapport Externe - Master Teleinnformatique - À PublierSouley LyPas encore d'évaluation
- TLILI GhadaDocument92 pagesTLILI GhadaDestinPas encore d'évaluation
- Conception Système de Gestion Des ÉtablissementsDocument120 pagesConception Système de Gestion Des ÉtablissementsHassamPas encore d'évaluation
- Memoire Finale 3Document75 pagesMemoire Finale 3josianesage1Pas encore d'évaluation
- EntreprenariatDocument29 pagesEntreprenariatwakeurboromsam mbackéPas encore d'évaluation
- Projet s4Document21 pagesProjet s421514Pas encore d'évaluation
- Rapport FinalDocument64 pagesRapport FinalHiba Aissaoui IdrissiPas encore d'évaluation
- MemoireDocument77 pagesMemoireAHMED LEHYANI100% (1)
- Rapport El Alaoui Imane Version Finale WordDocument102 pagesRapport El Alaoui Imane Version Finale WordAISSI RIHABPas encore d'évaluation
- Referentiel Developpement SI CAMES PDFDocument116 pagesReferentiel Developpement SI CAMES PDFCEFOPAMPas encore d'évaluation
- MehdyDocument72 pagesMehdyCrazy movisePas encore d'évaluation
- MEDDAH MustaphaDocument50 pagesMEDDAH Mustaphadev cPas encore d'évaluation
- Lawali RabiouDocument24 pagesLawali RabiouLawali Rabiou BinaddoPas encore d'évaluation
- Orca Share Media1663072180177 6975430297608539328Document51 pagesOrca Share Media1663072180177 6975430297608539328Andriamihaja RASOANARIVOPas encore d'évaluation
- Sow Mémoire 2022Document67 pagesSow Mémoire 2022Mamadou NiangPas encore d'évaluation
- Rapport de StageDocument32 pagesRapport de StageMonassir Mohamed Charaf100% (3)
- Mémoire Letembet ChrysDocument141 pagesMémoire Letembet Chrysnfinda ivanPas encore d'évaluation
- Stage-Pfe Dut JouhalDocument27 pagesStage-Pfe Dut JouhalkhadijaPas encore d'évaluation
- Mamadou Bhoye Diallo Memoire Final v1Document95 pagesMamadou Bhoye Diallo Memoire Final v1Aboubacry KANEPas encore d'évaluation
- ACFrOgBUXT-zNE441K5Cah-esHaCilYUcc9WyO1kMgHoE1pyw0 CXM HDwb9sxQhnYXEtMCAxWnojvV8GyfJGDlsXqVwhDzxeASKVFT42g2MbRhY7 nhOrYI pVrC6sDocument72 pagesACFrOgBUXT-zNE441K5Cah-esHaCilYUcc9WyO1kMgHoE1pyw0 CXM HDwb9sxQhnYXEtMCAxWnojvV8GyfJGDlsXqVwhDzxeASKVFT42g2MbRhY7 nhOrYI pVrC6sFRANCK OLIVIERPas encore d'évaluation
- Soutenance Licence ProDocument61 pagesSoutenance Licence Proeaka4016Pas encore d'évaluation
- Rapport JavaDocument16 pagesRapport JavaOussama MoustarzikPas encore d'évaluation
- Rapport Stage Licence Genie Informatique 2009Document80 pagesRapport Stage Licence Genie Informatique 2009Larbi AmranePas encore d'évaluation
- Rapport de Stage - RAMDocument53 pagesRapport de Stage - RAMABAASOUF100% (3)
- RapportNewFinalCopieMed KlibiDocument79 pagesRapportNewFinalCopieMed KlibiAymen TouihriPas encore d'évaluation
- DIC - 2012 - Conception Et Réalisation D́un Framework Pour Le Développement de Systèmes de Réservation en LigneDocument103 pagesDIC - 2012 - Conception Et Réalisation D́un Framework Pour Le Développement de Systèmes de Réservation en LigneSamirSaSamirPas encore d'évaluation
- Cours GED Stagaire Ver 9Document50 pagesCours GED Stagaire Ver 9obob9058Pas encore d'évaluation
- Rapport - PFE - Gestion de Stock - SEMMANEDocument51 pagesRapport - PFE - Gestion de Stock - SEMMANEOmar El Mejnaoui80% (5)
- Guide de L'étudiant - EPT - 2023Document17 pagesGuide de L'étudiant - EPT - 2023khadimdadocoumbaPas encore d'évaluation
- DHET - Mémoire Stage Certification QSE Roullier - Auteur Lucas TernynckDocument48 pagesDHET - Mémoire Stage Certification QSE Roullier - Auteur Lucas TernynckAbdellah EL MOUATASSIMPas encore d'évaluation
- DeschênesDocument124 pagesDeschênesLaila LailaPas encore d'évaluation
- Pfe RareDocument97 pagesPfe RareSimo Azrou0% (1)
- Rapport de Stage Anadi JacquelineDocument47 pagesRapport de Stage Anadi Jacquelineellamassinou007Pas encore d'évaluation
- PFE MOPIL Maintenance AMDEC Yasmine HAJJAJI 2020Document101 pagesPFE MOPIL Maintenance AMDEC Yasmine HAJJAJI 2020hajri BouthainaPas encore d'évaluation
- Conception Et Implémentation D'une Application de Suivie Du Parc InformatiqueDocument26 pagesConception Et Implémentation D'une Application de Suivie Du Parc InformatiqueElisabete Grasia AminaPas encore d'évaluation
- PFEL3Document43 pagesPFEL3Bouthaina MezgPas encore d'évaluation
- Rapport Dossier D'ese BMCEDocument67 pagesRapport Dossier D'ese BMCEMohammed RissaliPas encore d'évaluation
- Redaction de Mon Rapport de StageDocument51 pagesRedaction de Mon Rapport de StageNianmissou Mienwa100% (1)
- Mise en Place D'un Réseau EthernetDocument66 pagesMise en Place D'un Réseau EthernetJames Ulrich100% (1)
- FormationsDocument212 pagesFormationswinrak ddnsPas encore d'évaluation
- Rapport de Visite Yazaki Mohamed OUBIKHIRDocument6 pagesRapport de Visite Yazaki Mohamed OUBIKHIRmohamed.oubikhirPas encore d'évaluation
- Rapport PFE Asbayo HamzaDocument59 pagesRapport PFE Asbayo HamzaHamza AsbaYoPas encore d'évaluation
- Etude Et Mise en Place D'une S - Mohamed FARTITCHOU - 2743 PDFDocument121 pagesEtude Et Mise en Place D'une S - Mohamed FARTITCHOU - 2743 PDFSébastien OuédraogoPas encore d'évaluation
- Rapport de StageDocument19 pagesRapport de Stageimane amimiPas encore d'évaluation
- Memoire de Magister HacianeDocument144 pagesMemoire de Magister HacianezaghdoudiPas encore d'évaluation
- Rapport de Stage (Faculté Des Sciences Oujda)Document27 pagesRapport de Stage (Faculté Des Sciences Oujda)187med100% (1)
- .Archivetemprapport de Stage PFE (Benkacem - Med)Document82 pages.Archivetemprapport de Stage PFE (Benkacem - Med)Khaoula RAZZAKIPas encore d'évaluation
- Knowledge Management Et E-Learning Quelle ConvergenceDocument37 pagesKnowledge Management Et E-Learning Quelle ConvergenceSahbi DkhiliPas encore d'évaluation
- Rapport de Fin D Étude - Licences SIID - Hind AMARADocument26 pagesRapport de Fin D Étude - Licences SIID - Hind AMARASelma EsbPas encore d'évaluation
- Rapport de Stage AWSM Faraji-FenoDocument73 pagesRapport de Stage AWSM Faraji-Fenohamza elgarragPas encore d'évaluation
- Conception Developpement Site Web e Commerce Compte LSAT NokiaDocument73 pagesConception Developpement Site Web e Commerce Compte LSAT NokiaZakaria Tal100% (2)
- Mise en Place D'un IntranetDocument93 pagesMise en Place D'un IntranetLarissa FifalianaPas encore d'évaluation
- Realisation D'une Plateforme E-Commerce Pour Les Sites Commerciaux - Akkioui Younes - Fassih MarwaneDocument50 pagesRealisation D'une Plateforme E-Commerce Pour Les Sites Commerciaux - Akkioui Younes - Fassih MarwaneAL CHARIF0% (1)
- Guide Choisir - Collégial 2024: 36e édition - Toute l'information sur les formations collégiales (DEC, DEC-BAC et passerelles)D'EverandGuide Choisir - Collégial 2024: 36e édition - Toute l'information sur les formations collégiales (DEC, DEC-BAC et passerelles)Pas encore d'évaluation
- L' Appréciation des performances au travail: De l'individu à l'équipeD'EverandL' Appréciation des performances au travail: De l'individu à l'équipeÉvaluation : 5 sur 5 étoiles5/5 (1)
- Support TP Inf4048Document29 pagesSupport TP Inf4048Jean Louis Mélanie NdaguiPas encore d'évaluation
- TD TP PHPDocument6 pagesTD TP PHPSafae BelkhyrPas encore d'évaluation
- PageSpeed Insights 21 Janvier 2024 DesktopDocument8 pagesPageSpeed Insights 21 Janvier 2024 Desktopkyo007Pas encore d'évaluation
- Windows Server 2022 Administration Initiation Approfondissement PDFDocument4 pagesWindows Server 2022 Administration Initiation Approfondissement PDFmamadou dialloPas encore d'évaluation
- TD ProcessusDocument8 pagesTD ProcessusKhadija HaddaouiPas encore d'évaluation
- Ateliers 1 & 2 - BDDocument17 pagesAteliers 1 & 2 - BDHouneida HaddajiPas encore d'évaluation
- BC402 4.6a FRDocument246 pagesBC402 4.6a FRmhalcan1Pas encore d'évaluation
- Cours PHP ExceptionDocument40 pagesCours PHP Exceptionlosus007Pas encore d'évaluation
- QCM Si 2012 Ogi v1 CorrectionDocument4 pagesQCM Si 2012 Ogi v1 Correctioncoyote41Pas encore d'évaluation
- Institut Superieur D'Informatique Et de Gestion: Republique Democratique Du CongoDocument129 pagesInstitut Superieur D'Informatique Et de Gestion: Republique Democratique Du CongoHéritier KangelaPas encore d'évaluation
- User FormDocument23 pagesUser FormLa SadPas encore d'évaluation
- Iban FRDocument1 pageIban FRjacques.clotPas encore d'évaluation
- fb60 BapiDocument7 pagesfb60 BapiashwinPas encore d'évaluation
- Installation Et Configuration de Windows Server 2012 - 2016Document8 pagesInstallation Et Configuration de Windows Server 2012 - 2016FabouKoulibalyPas encore d'évaluation
- Gestion Des Reclamations Et de - Boukhriss Zouhair - 1443Document33 pagesGestion Des Reclamations Et de - Boukhriss Zouhair - 1443Naspr100% (1)
- TP 2Document2 pagesTP 2jouililiPas encore d'évaluation
- Java de BaseDocument126 pagesJava de BaseMoussa SyPas encore d'évaluation
- Java EE - TP 1 (Corrige)Document4 pagesJava EE - TP 1 (Corrige)Merniz Abdelkader100% (1)
- TP4 Curseur ExceptionDocument2 pagesTP4 Curseur ExceptionAdda Issa Abdoul RazakPas encore d'évaluation
- Developpeur Web - OpenclassroomDocument24 pagesDeveloppeur Web - OpenclassroomsefPas encore d'évaluation
- Partie 1 Up ProDocument13 pagesPartie 1 Up Projean5no5l5kangaPas encore d'évaluation
- TP 2 CorrectionDocument2 pagesTP 2 CorrectionMili GiliPas encore d'évaluation
- Dynamisez Vos Sites Avec JavaScriptDocument1 pageDynamisez Vos Sites Avec JavaScriptMartine KenfackPas encore d'évaluation
- Notions de Base en Java (Partie 1)Document94 pagesNotions de Base en Java (Partie 1)YassminaPas encore d'évaluation
- Slides Integration ContinueDocument22 pagesSlides Integration ContinueReda CZPas encore d'évaluation
- Chapitre IDocument102 pagesChapitre Iهداية مسلمةPas encore d'évaluation
- Cours Procedures Et FonctionsDocument11 pagesCours Procedures Et FonctionsChristian EhouanouPas encore d'évaluation
- Les FichiersDocument3 pagesLes Fichiersaicha GuefrachiPas encore d'évaluation
- Cours Et Exemples de Fonctions PHPDocument5 pagesCours Et Exemples de Fonctions PHPAyoub AcresPas encore d'évaluation
- Chapitre2 JavaFxDocument70 pagesChapitre2 JavaFxgaming for funPas encore d'évaluation