Vous aimerez peut-être aussi
- Annales Maths Tle CDocument118 pagesAnnales Maths Tle CPetit Frère À Jésus100% (4)
- Exercices Corrigés Pour L'analyse Complexe - 17!03!2020Document53 pagesExercices Corrigés Pour L'analyse Complexe - 17!03!2020mannai anwerPas encore d'évaluation
- Opérateurs VectorielsDocument6 pagesOpérateurs VectorielsELOISEPas encore d'évaluation
- TH Orie L Mentaire Des Feuilletages Holomorphes Singuliers PDFDocument212 pagesTH Orie L Mentaire Des Feuilletages Holomorphes Singuliers PDFjhon franklinPas encore d'évaluation
- M.inter Analyse PDFDocument7 pagesM.inter Analyse PDFAli SalahPas encore d'évaluation
- TD 4 Méthodes ItérativesDocument4 pagesTD 4 Méthodes ItérativesfalaPas encore d'évaluation
- TD 4 Méthodes ItérativesDocument4 pagesTD 4 Méthodes Itérativesmariam.ouaaabedPas encore d'évaluation
- Fic 00026Document4 pagesFic 00026Mohand BADJOUPas encore d'évaluation
- Cor Mines Alg1Document12 pagesCor Mines Alg1yassinePas encore d'évaluation
- Examen PartielDocument10 pagesExamen PartielManal TetoPas encore d'évaluation
- Bac Cameroun 2019Document2 pagesBac Cameroun 2019Omar MakhPas encore d'évaluation
- Fic 00026Document4 pagesFic 00026MuhcinePas encore d'évaluation
- MASS3 OptiComb tp5Document4 pagesMASS3 OptiComb tp5Kodjo Gabin DEGUENONPas encore d'évaluation
- Um6p 2023 TD3Document3 pagesUm6p 2023 TD3Soufiane MoustakbalPas encore d'évaluation
- Feuille 6Document3 pagesFeuille 6AdamPas encore d'évaluation
- Devoir de Contrôle N°1 - Math - Bac Mathématiques (2017-2018) MR S-SOLADocument2 pagesDevoir de Contrôle N°1 - Math - Bac Mathématiques (2017-2018) MR S-SOLAaliPas encore d'évaluation
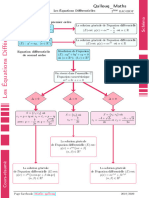
- Equation Differentielle SchemaDocument1 pageEquation Differentielle SchemaSoufiane KhaddadiPas encore d'évaluation
- Nombres Réels Et ComplexesDocument22 pagesNombres Réels Et ComplexesAlylia CattPas encore d'évaluation
- TD 1 - Compexite 2022 2023Document12 pagesTD 1 - Compexite 2022 2023Mouhamed NdiayePas encore d'évaluation
- TD 1Document4 pagesTD 1Thierry Gnasiri Godwe HinsouPas encore d'évaluation
- Exercices, Mines Ponts - Oral PDFDocument88 pagesExercices, Mines Ponts - Oral PDFMahmoudSfarHanchaPas encore d'évaluation
- Mines - Ponts - Oraux PDFDocument88 pagesMines - Ponts - Oraux PDFMahmoudSfarHanchaPas encore d'évaluation
- Controle Continu D'agbèbre. 1. L1S2. Licences PSI.: 1 Consignes (À Lire Absolument)Document11 pagesControle Continu D'agbèbre. 1. L1S2. Licences PSI.: 1 Consignes (À Lire Absolument)Nakodja BadjelPas encore d'évaluation
- TD Algà Bre Licence 1 (2021-2022)Document8 pagesTD Algà Bre Licence 1 (2021-2022)Moussa BambaPas encore d'évaluation
- Un Corrig e Du Concours Centrale-Sup Elec Math-I-2014 Fili' Ere MPDocument5 pagesUn Corrig e Du Concours Centrale-Sup Elec Math-I-2014 Fili' Ere MPRhrbrjPas encore d'évaluation
- Epreuv Bac C 2012Document2 pagesEpreuv Bac C 2012PassiziPas encore d'évaluation
- Fic 00001Document17 pagesFic 00001NOUARI mohamedPas encore d'évaluation
- Cours Equations DifferentiellesDocument5 pagesCours Equations DifferentiellesJamel RouahiPas encore d'évaluation
- 17 Compo 2Document4 pages17 Compo 2Ibzo ProPas encore d'évaluation
- Ds 2 UIR 2012-2013Document2 pagesDs 2 UIR 2012-2013sorayuki1427Pas encore d'évaluation
- Matrices 5 Matrice Identite PDFDocument5 pagesMatrices 5 Matrice Identite PDFSaliou NdourPas encore d'évaluation
- Chapitre IIIDocument11 pagesChapitre IIIAutumn Assirem TrefoilPas encore d'évaluation
- AM Partiel Nov20Document3 pagesAM Partiel Nov20Mahdi BhrPas encore d'évaluation
- Problème I: ExerciceDocument2 pagesProblème I: ExerciceMossaab EssafiPas encore d'évaluation
- TD1 CorrectionDocument4 pagesTD1 CorrectionTombemine TombeminePas encore d'évaluation
- Centrale-Sup SARAHDocument22 pagesCentrale-Sup SARAHSARAH ASSIMPas encore d'évaluation
- TD Endoeveucl PDFDocument2 pagesTD Endoeveucl PDFAlgèbre PC - PTPas encore d'évaluation
- CCP MP 2019 Maths 2 CorrigeDocument5 pagesCCP MP 2019 Maths 2 CorrigeAnowar SaleinePas encore d'évaluation
- ch1 Div EuclidienneDocument6 pagesch1 Div EuclidienneCrypto SylvainPas encore d'évaluation
- Bacblanc29 2 2008turbergueDocument3 pagesBacblanc29 2 2008turbergueChanelChanelPas encore d'évaluation
- CCPPC 2011Document9 pagesCCPPC 2011Hassan RahoumPas encore d'évaluation
- TD 4: Notions Élémentaires de Géométrie AnalytiqueDocument3 pagesTD 4: Notions Élémentaires de Géométrie Analytiquefatima zaharPas encore d'évaluation
- Comment Faire ComplexesDocument1 pageComment Faire Complexesfrank sopPas encore d'évaluation
- Serie 1Document3 pagesSerie 1EL Mahdi AlPas encore d'évaluation
- Ac BlancDocument5 pagesAc BlancAziz Benamor100% (1)
- Exercice I: CCP - Tsi - 2005 - 1 1Document6 pagesExercice I: CCP - Tsi - 2005 - 1 1api-3762501Pas encore d'évaluation
- Concours National Commun: Première Partie: Expression D'un DéterminantDocument5 pagesConcours National Commun: Première Partie: Expression D'un DéterminantSALAH EDDINE ABBASSIPas encore d'évaluation
- TD5-03 - Calcul MatricielDocument4 pagesTD5-03 - Calcul MatricielAlaa Din AL-khwarizmiPas encore d'évaluation
- La Te X15Document5 pagesLa Te X15almarfawi664Pas encore d'évaluation
- Sujet Et Corrigé Théorie de RégularitéDocument2 pagesSujet Et Corrigé Théorie de RégularitéNourdine BelkenadilPas encore d'évaluation
- Exam Opti 1 2007Document2 pagesExam Opti 1 2007api-3773410Pas encore d'évaluation
- DM Equation de BesselDocument2 pagesDM Equation de Besselhoussamelghazioui85Pas encore d'évaluation
- Combinepdf (2) WatermarkDocument11 pagesCombinepdf (2) WatermarktorkitaherPas encore d'évaluation
- Solutions TD2 Dispositifs RFDocument4 pagesSolutions TD2 Dispositifs RFLE BARON100% (1)
- Analyse Examen Remplacement CorrigeDocument4 pagesAnalyse Examen Remplacement CorrigeNawel SlimaniPas encore d'évaluation
- ENI Geipi Polytech 2013Document4 pagesENI Geipi Polytech 2013Cheick Oumar SamakéPas encore d'évaluation
- TD14 ArithmétiquesDocument3 pagesTD14 ArithmétiquesMamoudou MballoPas encore d'évaluation
- Serie1 AN Maticiel 22 23Document2 pagesSerie1 AN Maticiel 22 23koukou kikiPas encore d'évaluation
- Cours Complexes GeometrieDocument9 pagesCours Complexes GeometrieOthniel MeignanPas encore d'évaluation
- Algebre II PolynomesDocument12 pagesAlgebre II PolynomesYoussef MzabiPas encore d'évaluation
- Nombres RéelsDocument12 pagesNombres RéelsazerfghPas encore d'évaluation
- 2014 Polynesie Exo4 PDFDocument3 pages2014 Polynesie Exo4 PDFChristian Hippolyte N'driPas encore d'évaluation
- Mooc Elm Doc AvDocument10 pagesMooc Elm Doc AvVân Vui VẻPas encore d'évaluation
- SousouDocument2 pagesSousouSouhaib HridouchPas encore d'évaluation
- Activité Seq 6 Champs ForcesDocument4 pagesActivité Seq 6 Champs Forcesrblandine33Pas encore d'évaluation
- Mécanique Du PointDocument17 pagesMécanique Du PointMOHAMMED HADDADPas encore d'évaluation
- Wa0039.Document39 pagesWa0039.Paulin YameogoPas encore d'évaluation
- DL3 Sur 3Document7 pagesDL3 Sur 3Oussama WazzahrouPas encore d'évaluation
- Gradient A Pas OptimalDocument3 pagesGradient A Pas Optimalchaima regaiegPas encore d'évaluation
- Projecteur OrthogonauxDocument4 pagesProjecteur OrthogonauxEL Mansouri AchrafPas encore d'évaluation
- Systèmes Marériels À Deux Corps Prepa1 UilDocument48 pagesSystèmes Marériels À Deux Corps Prepa1 UilVenusia IbadiPas encore d'évaluation
- Deux VariablesDocument7 pagesDeux VariablesNisrine ZaligaPas encore d'évaluation
- TD1 Les Intégrales Multiples PDFDocument6 pagesTD1 Les Intégrales Multiples PDFRomaissa LoulhaciPas encore d'évaluation
- 11 - Produit Scalaire Exercices Corriges Niveau 2Document15 pages11 - Produit Scalaire Exercices Corriges Niveau 2Younes BelkadiPas encore d'évaluation
- (Cin) (CO) CinematiqueDocument14 pages(Cin) (CO) CinematiqueElbatouri Badr EddinePas encore d'évaluation
- Oldache Rev - Alg.phys.2!1!2015Document6 pagesOldache Rev - Alg.phys.2!1!2015Toni ManPas encore d'évaluation
- GeomDiff PDFDocument7 pagesGeomDiff PDFVincent ISOZ100% (1)
- 2 Introduction À La Relativité RestreinteDocument9 pages2 Introduction À La Relativité Restreinteاقوال و حكمPas encore d'évaluation
- Equation de SchrodingerDocument8 pagesEquation de SchrodingerKader MilanoPas encore d'évaluation
- Mathematiques5 Concours Amcpe 2013Document2 pagesMathematiques5 Concours Amcpe 2013Indigo PaperPas encore d'évaluation
- 04 Composition Des Vitesses Et AccélérationsDocument8 pages04 Composition Des Vitesses Et AccélérationsNitos IncoPas encore d'évaluation
- Algèbre de LieDocument5 pagesAlgèbre de Lieabdelaaa100% (1)
- Calcul MatricielDocument41 pagesCalcul MatricielMohamed AziatPas encore d'évaluation
- AMPHI 2 Chapitre2 2015 Cinématique Poutres Et Lois de Comportement17 Mars SakaiDocument22 pagesAMPHI 2 Chapitre2 2015 Cinématique Poutres Et Lois de Comportement17 Mars SakaiMohamed SalemPas encore d'évaluation
- CH 1 Cours Cinématique Du Point Matériel - ModifiéDocument69 pagesCH 1 Cours Cinématique Du Point Matériel - ModifiéKhalid ChrisPas encore d'évaluation
- Chapitre1.Force Champ Et PotentielDocument13 pagesChapitre1.Force Champ Et PotentielSaid LartistPas encore d'évaluation
- DS 1 20 21Document3 pagesDS 1 20 21MRayoub AbtPas encore d'évaluation
- Formulaire TopoDocument12 pagesFormulaire TopoSabriRemremPas encore d'évaluation
- EqudiffDocument16 pagesEqudiffRachid FaizPas encore d'évaluation