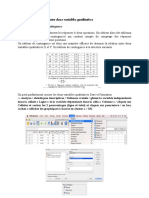
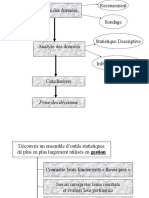
Vous aimerez peut-être aussi
- L' ETALONNAGE ET LA DECISION PSYCHOMETRIQUE, 2E EDITION: Exemples et tablesD'EverandL' ETALONNAGE ET LA DECISION PSYCHOMETRIQUE, 2E EDITION: Exemples et tablesPas encore d'évaluation
- Question de Recherche Hypothèses de Recherche Variables Et Échelles de Mesure Types de Données Nombre D'échantillonsDocument20 pagesQuestion de Recherche Hypothèses de Recherche Variables Et Échelles de Mesure Types de Données Nombre D'échantillonsClosed WayPas encore d'évaluation
- Stat1an06 Principe - Tests Laoussati PDFDocument5 pagesStat1an06 Principe - Tests Laoussati PDFImen MestarPas encore d'évaluation
- Résumé Anova Et Manova-1 PDFDocument4 pagesRésumé Anova Et Manova-1 PDFNorah SahwanePas encore d'évaluation
- Cocher La Ou Les Bonne(s) Réponse(s) : 1. 6Document2 pagesCocher La Ou Les Bonne(s) Réponse(s) : 1. 6Mina KhellaPas encore d'évaluation
- Analyse Des DonnãesDocument26 pagesAnalyse Des DonnãesBayrem HarbaouiPas encore d'évaluation
- CCM2.Didactique KefDocument72 pagesCCM2.Didactique KefNoomen GalmamiPas encore d'évaluation
- Cm.2ci. EsakDocument105 pagesCm.2ci. EsakNoomen GalmamiPas encore d'évaluation
- Tests Non ParamétriquesDocument36 pagesTests Non ParamétriquesNabila Mamzlle SukiPas encore d'évaluation
- ANOVA 1F 2F Hierarchique PDFDocument158 pagesANOVA 1F 2F Hierarchique PDFmedaliPas encore d'évaluation
- CM1 Quantit - CARTHAGEDocument85 pagesCM1 Quantit - CARTHAGENoomen GalmamiPas encore d'évaluation
- CCM1Didactique. KefDocument79 pagesCCM1Didactique. KefNoomen GalmamiPas encore d'évaluation
- Analyse en Composantes PrincipalesDocument10 pagesAnalyse en Composantes PrincipalesAya El Hadri100% (1)
- CM1SH KefDocument84 pagesCM1SH KefNoomen GalmamiPas encore d'évaluation
- Méthodes Quantitatives Appliquées À L'environnementDocument113 pagesMéthodes Quantitatives Appliquées À L'environnementGvfvbgm100% (1)
- Statistiques en Recherche FondamentaleDocument53 pagesStatistiques en Recherche FondamentaleGuivis ZeufackPas encore d'évaluation
- Introduction Au Test Dhypothese de Chi DeuxDocument10 pagesIntroduction Au Test Dhypothese de Chi Deuxbouyakoubselma5Pas encore d'évaluation
- Les Critères de Choix D'un Test StatistiqueDocument3 pagesLes Critères de Choix D'un Test StatistiqueNouza MkPas encore d'évaluation
- Analyse de Données VocabulaireDocument7 pagesAnalyse de Données Vocabulairewokesik326Pas encore d'évaluation
- TE AD Ch5 2020Document28 pagesTE AD Ch5 2020Mohammed ZoubaPas encore d'évaluation
- BASDI (ED) - Module 7 (Tests Dhypothèse Paramétriques)Document70 pagesBASDI (ED) - Module 7 (Tests Dhypothèse Paramétriques)yassin ali100% (1)
- Cours Statistique 4Document53 pagesCours Statistique 4Jerbi InesPas encore d'évaluation
- Analyse Bivariee Miage Licence IIDocument75 pagesAnalyse Bivariee Miage Licence IIDonald KonePas encore d'évaluation
- Projet SPSS VFDocument8 pagesProjet SPSS VFEttalbiPas encore d'évaluation
- Chapitre 3Document60 pagesChapitre 3GEEKGHAZIPas encore d'évaluation
- Tests StatistiquesDocument11 pagesTests Statistiqueschouchou vetovet100% (1)
- Data Mining CoursDocument59 pagesData Mining CoursAdam ghaibiPas encore d'évaluation
- TP StataDocument8 pagesTP StataNiyonkuru Alain DanielPas encore d'évaluation
- Inference Statistique Resumes Et ExercicDocument57 pagesInference Statistique Resumes Et Exercicanne-marie ChampoussinPas encore d'évaluation
- Les Méthodes Quantitatives Explicatives de Traitement Des DonnéesDocument6 pagesLes Méthodes Quantitatives Explicatives de Traitement Des DonnéesMohamed Reda HammadiaPas encore d'évaluation
- Val Rech Essaia 2021 Partie 2Document45 pagesVal Rech Essaia 2021 Partie 2amina imenePas encore d'évaluation
- Choisir Le Test Statistique AppropriéDocument6 pagesChoisir Le Test Statistique Appropriépat170571Pas encore d'évaluation
- ANOVA A 1 Facteur Analyse de Variance OnDocument24 pagesANOVA A 1 Facteur Analyse de Variance Onkata brhPas encore d'évaluation
- Le Traitement Statistique PDFDocument5 pagesLe Traitement Statistique PDFZandry BefitiaPas encore d'évaluation
- Relation Entre Deux Variables QualitativesDocument10 pagesRelation Entre Deux Variables QualitativesDantePas encore d'évaluation
- GénétiqueDocument14 pagesGénétiqueSteph Christ VembePas encore d'évaluation
- Whitepaper StatisticalTest FRDocument15 pagesWhitepaper StatisticalTest FRdexpsogbPas encore d'évaluation
- Le Test de LeveneDocument2 pagesLe Test de Levenenguessan lassiePas encore d'évaluation
- A02-Analyses Statistiques de Base 181001Document50 pagesA02-Analyses Statistiques de Base 181001Fernando Jorge BadePas encore d'évaluation
- 2022-2023-LE-Biostatistique-1-Statistiques Descriptives-V0Document10 pages2022-2023-LE-Biostatistique-1-Statistiques Descriptives-V0paracelse.lyonPas encore d'évaluation
- Cours Stat LP-S5 Partie 2Document103 pagesCours Stat LP-S5 Partie 2Douâa BmPas encore d'évaluation
- Notion de Test D - HypotheseDocument6 pagesNotion de Test D - HypotheseMahdi El BahiPas encore d'évaluation
- Test D'Hypotheses: Ecole Des Hautes Etudes CommercialesDocument14 pagesTest D'Hypotheses: Ecole Des Hautes Etudes Commercialesالتهامي التهاميPas encore d'évaluation
- TEST STAT m1BDocument15 pagesTEST STAT m1Bmonecole2018Pas encore d'évaluation
- Leçon3 Test ParametriquesDocument27 pagesLeçon3 Test ParametriquesMamadou TouréPas encore d'évaluation
- Trait Stat Avec SPSSDocument20 pagesTrait Stat Avec SPSSJoseph Blaise DONGMO LEKAGNEPas encore d'évaluation
- Analyses Statitistiques Master Recherche 2020Document41 pagesAnalyses Statitistiques Master Recherche 2020FELICITE FODNE WAASOPas encore d'évaluation
- Cours 02Document26 pagesCours 02WoxPas encore d'évaluation
- Test de Student PDFDocument5 pagesTest de Student PDFVie PrivéPas encore d'évaluation
- Test de Student PDFDocument5 pagesTest de Student PDFVie PrivéPas encore d'évaluation
- 03 Estimation PDFDocument20 pages03 Estimation PDFBawba AbdallahPas encore d'évaluation
- Valider Un Processus de Contrôle: Presenté Par Baba-Aissa Chourouk WeãmDocument22 pagesValider Un Processus de Contrôle: Presenté Par Baba-Aissa Chourouk WeãmweamPas encore d'évaluation
- Lca GlossaireDocument28 pagesLca GlossaireamazedPas encore d'évaluation
- Cahier - 28 - 78017Document69 pagesCahier - 28 - 78017Emmanuel DemosthenePas encore d'évaluation
- Bio StatistiqueDocument14 pagesBio StatistiqueFeriel BereksiPas encore d'évaluation
- Chapitre 6Document29 pagesChapitre 6bvn6789Pas encore d'évaluation
- TD 3Document6 pagesTD 3Jingjing ShaPas encore d'évaluation
- Chap6 2122Document4 pagesChap6 2122Berenger MabéléPas encore d'évaluation
- Correction Examen EDM 2015 S6Document4 pagesCorrection Examen EDM 2015 S6Raiaa ElmamiPas encore d'évaluation
- Kama Sutra Illustré-Julie Laurent 2020 FRENCHDocument90 pagesKama Sutra Illustré-Julie Laurent 2020 FRENCHMarcellus Olivier60% (5)
- Modèles À Effets Mixtes en Pratique Dans RDocument28 pagesModèles À Effets Mixtes en Pratique Dans RBernard HounnouvePas encore d'évaluation
- Cours Modele Lineaire1 2022 2023 ImpDocument107 pagesCours Modele Lineaire1 2022 2023 ImpBernard HounnouvePas encore d'évaluation
- Les Clés Du 7 Ème CielDocument42 pagesLes Clés Du 7 Ème CielBernard Hounnouve100% (1)
- L'art Du MougouliDocument60 pagesL'art Du MougouliBernard HounnouvePas encore d'évaluation
- 101 Idees RomantiquesDocument42 pages101 Idees RomantiquesBernard HounnouvePas encore d'évaluation
- Le Copywriting - SlidesDocument29 pagesLe Copywriting - SlidesBernard HounnouvePas encore d'évaluation
- Naissance D'une Civilisation: Yves Brunsvick Et André DanzinDocument105 pagesNaissance D'une Civilisation: Yves Brunsvick Et André DanzinBernard HounnouvePas encore d'évaluation
- Memoire 2Document24 pagesMemoire 2Bernard HounnouvePas encore d'évaluation
- Handicap Moteur Megeve 2012Document16 pagesHandicap Moteur Megeve 2012Bernard HounnouvePas encore d'évaluation
- Sept Règles D'or Pour Réussir en BourseDocument10 pagesSept Règles D'or Pour Réussir en BourseBernard HounnouvePas encore d'évaluation
- Session 05 - Money Management PDFDocument8 pagesSession 05 - Money Management PDFSnow jonPas encore d'évaluation
- Magie SorcellerieDocument12 pagesMagie SorcellerieKadiyogo IssoufPas encore d'évaluation
- 4 6010277144104536028Document12 pages4 6010277144104536028Bernard HounnouvePas encore d'évaluation
- Message Des AngesDocument59 pagesMessage Des AngesBernard Hounnouve100% (1)
- 1 5150182154642129463Document53 pages1 5150182154642129463Bernard HounnouvePas encore d'évaluation
- Ebook Gratuit - 11 Points Pour Commencer À MaigrirDocument25 pagesEbook Gratuit - 11 Points Pour Commencer À MaigrirBernard HounnouvePas encore d'évaluation
- WhatsApp Miracl - Business Modèles Sur WHATS'APP Module 2Document8 pagesWhatsApp Miracl - Business Modèles Sur WHATS'APP Module 2Bernard HounnouvePas encore d'évaluation
- 1 5150182154642129471Document22 pages1 5150182154642129471Bernard HounnouvePas encore d'évaluation
- Cours No 01 Présentation D'un OrdinateurDocument2 pagesCours No 01 Présentation D'un OrdinateurBernard Hounnouve100% (1)
- Professional Branding: Développer Sa Marque PersonnelleDocument30 pagesProfessional Branding: Développer Sa Marque PersonnelleBernard HounnouvePas encore d'évaluation
- Cours No 08 Les MicroprocesseursDocument7 pagesCours No 08 Les MicroprocesseursBernard HounnouvePas encore d'évaluation
- Cours No 07 Le Bloc D'alimentationDocument5 pagesCours No 07 Le Bloc D'alimentationBernard Hounnouve100% (5)
- 65 Bonnes Idées de Création D'entreprise 2019-1 PDFDocument8 pages65 Bonnes Idées de Création D'entreprise 2019-1 PDFPierre Thermitus Garindy100% (1)
- 110 Conseils Pour Ameliorer Sa Vie Et Etre Plus Heureux PDFDocument128 pages110 Conseils Pour Ameliorer Sa Vie Et Etre Plus Heureux PDFsaraPas encore d'évaluation
- Cest Vraiment Moi Qui DécideDocument208 pagesCest Vraiment Moi Qui DécideBernard HounnouvePas encore d'évaluation
- Commerce InternationalDocument183 pagesCommerce InternationalMasseant ErnstPas encore d'évaluation
- Amenagement Des PêchesDocument17 pagesAmenagement Des PêchesBernard Hounnouve100% (1)
- Ch04 TP Salinite Titrage ConductimetriqueDocument1 pageCh04 TP Salinite Titrage Conductimetriquesylvain zuchiattiPas encore d'évaluation
- Ba00444cfr 2721Document176 pagesBa00444cfr 2721hassanPas encore d'évaluation
- Corrigé de L'exercice N° 1: Calcul Du Potentiel D'équilibre D'un IonDocument10 pagesCorrigé de L'exercice N° 1: Calcul Du Potentiel D'équilibre D'un IonSabo100% (1)
- Politique Linguistique Et Toponymie Quel PDFDocument21 pagesPolitique Linguistique Et Toponymie Quel PDFMassa TebaniPas encore d'évaluation
- L'expression "Historico-Critique " PDFDocument5 pagesL'expression "Historico-Critique " PDFJean-Paul Yves Le GoffPas encore d'évaluation
- NAT-1reG D5SpectroscopieIR PDFDocument10 pagesNAT-1reG D5SpectroscopieIR PDFYõůsřà LõlaPas encore d'évaluation
- 10772-EPLEFPA MATITI Fiche Espacement Et Densitã© (Nombre D Arbres Sur Ma Parcelle)Document4 pages10772-EPLEFPA MATITI Fiche Espacement Et Densitã© (Nombre D Arbres Sur Ma Parcelle)NvedaPas encore d'évaluation
- La Fin Du MalDocument120 pagesLa Fin Du MalBruno Sauniere100% (2)
- La Méthode Des 5SDocument2 pagesLa Méthode Des 5SMotassi AlexPas encore d'évaluation
- 15ème Dimanche TOB 2021Document2 pages15ème Dimanche TOB 2021christian parfait yanda belingaPas encore d'évaluation
- Convexite CoursDocument3 pagesConvexite CoursCédric VergneriePas encore d'évaluation
- Reins1 Sionneau Com PDFDocument13 pagesReins1 Sionneau Com PDFlexpoPas encore d'évaluation
- BVM.303. GaiaDocument38 pagesBVM.303. GaiaadwawdPas encore d'évaluation
- 2 Observation Médicale Et Démarche en Médecine InterneDocument60 pages2 Observation Médicale Et Démarche en Médecine InterneDalmat LambertPas encore d'évaluation
- TD Stat Inférentielle - Loi NormaleDocument2 pagesTD Stat Inférentielle - Loi NormaleSalma SabwatPas encore d'évaluation
- LMU - Problèmes Macroéconomiques - TD 1 - Corrigé - Chapitre 1 PDFDocument12 pagesLMU - Problèmes Macroéconomiques - TD 1 - Corrigé - Chapitre 1 PDFAndy RAKOTOARISONPas encore d'évaluation
- NICE RobusKit 600-2Vtx Notice SimplifieeDocument9 pagesNICE RobusKit 600-2Vtx Notice SimplifieexclPas encore d'évaluation
- Ts 2Document9 pagesTs 2Ayman AssilaPas encore d'évaluation
- Guide Des Medicaments Rembourses DciDocument129 pagesGuide Des Medicaments Rembourses DciAsmaa TznPas encore d'évaluation
- La Logistique Des RetoursDocument8 pagesLa Logistique Des RetoursAbdo EłPas encore d'évaluation
- Modélisation Des SystèmesDocument7 pagesModélisation Des Systèmestenere comPas encore d'évaluation
- Cours Gestion Des AT&MP Doc Stagiaire BI5 - 03&042022Document42 pagesCours Gestion Des AT&MP Doc Stagiaire BI5 - 03&042022science du futurPas encore d'évaluation
- UE1 Comptabilité InternationaleDocument2 pagesUE1 Comptabilité Internationalefathia100% (1)
- DS Dossier Gratuit HypertensionDocument11 pagesDS Dossier Gratuit HypertensionFrancoisPas encore d'évaluation
- Cours Milieux Poreux Et DispersésDocument23 pagesCours Milieux Poreux Et DispersésAbdallah abdellaoui91% (11)
- Tous Les Calculs de Bac Pro Commerce PDFDocument3 pagesTous Les Calculs de Bac Pro Commerce PDFHiSo DaanPas encore d'évaluation
- Devoir Communal Tle A2Document2 pagesDevoir Communal Tle A2Wilfried OboPas encore d'évaluation
- 2 - Comment Prescrire Et Surveiller Un Traitement Anti-InfectieuxDocument155 pages2 - Comment Prescrire Et Surveiller Un Traitement Anti-InfectieuxchadelkettPas encore d'évaluation
- Master I - Gestion de Projets - Seance 1B PDFDocument27 pagesMaster I - Gestion de Projets - Seance 1B PDFSarah ManouPas encore d'évaluation
- Effet Thérapeutique D'ailDocument252 pagesEffet Thérapeutique D'ailtasnime haninePas encore d'évaluation