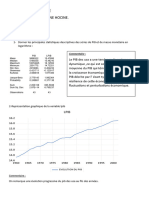
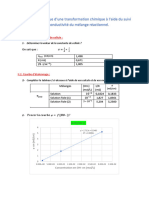
Vous aimerez peut-être aussi
- Hocine Hocine Homework grp3Document8 pagesHocine Hocine Homework grp3HOCINE HOCINEPas encore d'évaluation
- PRATIQUE1Document19 pagesPRATIQUE1fadwa elPas encore d'évaluation
- Econométrie Des Données de Panel 1Document4 pagesEconométrie Des Données de Panel 1rey.payne12Pas encore d'évaluation
- TD Etalonnage Des DébitmètresDocument6 pagesTD Etalonnage Des DébitmètresAyache KazoulaPas encore d'évaluation
- TPF Sur TPHDocument4 pagesTPF Sur TPHyasmine hamoudaPas encore d'évaluation
- Lampiran SkripsiDocument6 pagesLampiran SkripsiSalsabil CecaraniPas encore d'évaluation
- Olah DataDocument9 pagesOlah DataNickelNafa GamingPas encore d'évaluation
- Ajustement Des Débits Moyens AnnuelsDocument7 pagesAjustement Des Débits Moyens AnnuelsferhatiPas encore d'évaluation
- S6-Econométrie-Statistiques Discriptioves-19-20 PDFDocument17 pagesS6-Econométrie-Statistiques Discriptioves-19-20 PDFPPwmPas encore d'évaluation
- TD Ingéniérie de L'analyse Des DonnéesDocument23 pagesTD Ingéniérie de L'analyse Des DonnéesHodo Hodo Saad GoudenPas encore d'évaluation
- Exo6 Sortie SAS Car2Document6 pagesExo6 Sortie SAS Car2Viet NguyenPas encore d'évaluation
- Maitrise Statistique de ProcedesDocument9 pagesMaitrise Statistique de ProcedesAbdelatif Hr100% (2)
- Thermodynamique Et CinétiqueDocument21 pagesThermodynamique Et Cinétiquezahraa daherPas encore d'évaluation
- TP3Filtre RC Passe HautDocument8 pagesTP3Filtre RC Passe Hautlemouciss021Pas encore d'évaluation
- Tp2compensation de L'énergie Réactive Dans Les Réseaux de DistributionDocument7 pagesTp2compensation de L'énergie Réactive Dans Les Réseaux de DistributionsalahouchenesalahPas encore d'évaluation
- Compte Rendu TPDocument26 pagesCompte Rendu TPiramaneali4Pas encore d'évaluation
- Analyse en Composante Principale - MemoireDocument10 pagesAnalyse en Composante Principale - MemoireShedna ItalisPas encore d'évaluation
- Correction TD1Document2 pagesCorrection TD1Léopold junior NioulePas encore d'évaluation
- SlssjsDocument4 pagesSlssjsJean-François BoliPas encore d'évaluation
- StrictfulDocument28 pagesStrictfulAmoyePas encore d'évaluation
- AmarDocument8 pagesAmarwychc9t74yPas encore d'évaluation
- tp3 InstrumentationDocument8 pagestp3 Instrumentationrami kafiPas encore d'évaluation
- EconométrieDocument9 pagesEconométrieAlex MalinvernoPas encore d'évaluation
- Boli Gotre BiDocument4 pagesBoli Gotre BiJean-François BoliPas encore d'évaluation
- Série 1Document3 pagesSérie 1Gasmi KrPas encore d'évaluation
- TP3 MiDocument5 pagesTP3 Mirahim onePas encore d'évaluation
- Exo6 Sortie SAS DiabetesDocument12 pagesExo6 Sortie SAS DiabetesViet NguyenPas encore d'évaluation
- Exercice n3 ProfDocument2 pagesExercice n3 Profyassine lahninPas encore d'évaluation
- Pertes de Charge LineairesDocument12 pagesPertes de Charge LineairesRidha AbdallahPas encore d'évaluation
- Resonance_Meca (6)Document15 pagesResonance_Meca (6)riezjrif fsdjkfipsdjPas encore d'évaluation
- Formula RioDocument8 pagesFormula RioMax LópezPas encore d'évaluation
- 7shi FinalDocument6 pages7shi FinalTakieddine BenlahcenPas encore d'évaluation
- TD Chap 2 Hydraulique Maritime-1Document7 pagesTD Chap 2 Hydraulique Maritime-1Hicham FaddalPas encore d'évaluation
- TAHWILLDocument8 pagesTAHWILLdriciPas encore d'évaluation
- Antoine CoefficientsDocument36 pagesAntoine CoefficientsAsadPas encore d'évaluation
- CR Re Master 1 UsthbDocument4 pagesCR Re Master 1 UsthbFlenneo WOCPas encore d'évaluation
- ProductionFunction 2 2Document4 pagesProductionFunction 2 2Hai Tran Minh TuePas encore d'évaluation
- Etude de CasDocument8 pagesEtude de CasYasmine HammamiPas encore d'évaluation
- tp4_fluideDocument6 pagestp4_fluidesayemoumaymaPas encore d'évaluation
- H3 PO4 BisDocument47 pagesH3 PO4 BisZaineb AbbadPas encore d'évaluation
- TP Acp2Document7 pagesTP Acp2FadiPas encore d'évaluation
- M Ethodologie de Box Et JenkinsDocument6 pagesM Ethodologie de Box Et Jenkinssoufram1993Pas encore d'évaluation
- travail à rendre3Document16 pagestravail à rendre3Walid Hamza OuakhirPas encore d'évaluation
- But Du TPDocument7 pagesBut Du TPAsma MensiPas encore d'évaluation
- Correction Cas 15Document6 pagesCorrection Cas 15Imane LKPas encore d'évaluation
- TP Mecanique Des Fluides Mesure de DébitDocument9 pagesTP Mecanique Des Fluides Mesure de Débitkhalfallah hamza100% (1)
- Arbre Analyste Debordemnt Du ResrvoirDocument4 pagesArbre Analyste Debordemnt Du ResrvoirOussama RemaliPas encore d'évaluation
- Devoir 1Document21 pagesDevoir 1septimus.pierrePas encore d'évaluation
- TP n05 metrologieDocument3 pagesTP n05 metrologieNada GherbiPas encore d'évaluation
- Spc-Four 05Document22 pagesSpc-Four 05Michael T-mic TshitengePas encore d'évaluation
- Partie BDocument5 pagesPartie BKhaled RemchiPas encore d'évaluation
- Grafik NaOHDocument4 pagesGrafik NaOHNovita Ardian KrisgiyantiPas encore d'évaluation
- GLmizM73Pdg Calcul-AbaqueDocument50 pagesGLmizM73Pdg Calcul-AbaqueMajdi JerbiPas encore d'évaluation
- Matrice Dalot DoubleDocument11 pagesMatrice Dalot DoubleBadra Ali SanogoPas encore d'évaluation
- Thema 32Document26 pagesThema 32yassinemPas encore d'évaluation
- GP - Application Du CoursDocument20 pagesGP - Application Du CoursDoc Padraig CharafeddinePas encore d'évaluation
- Tp CinetiqueDocument8 pagesTp CinetiquebahriaafraouiPas encore d'évaluation
- TP2 DernierDocument9 pagesTP2 Dernierchaymaa MRHARPas encore d'évaluation
- Compte Rendue TP 1Document30 pagesCompte Rendue TP 1Abd el kayoumPas encore d'évaluation
- Le syndrome périodique associé à la cryopyrine (CAPS)D'EverandLe syndrome périodique associé à la cryopyrine (CAPS)Pas encore d'évaluation
- exercice111Document2 pagesexercice111stephane anonPas encore d'évaluation
- BASEDEVOIRANOVADocument1 pageBASEDEVOIRANOVAstephane anonPas encore d'évaluation
- Methode-de-Newton-RaphsonDocument8 pagesMethode-de-Newton-Raphsonstephane anonPas encore d'évaluation
- Introduction Au Mythe de ProméthéeDocument8 pagesIntroduction Au Mythe de Prométhéestephane anonPas encore d'évaluation
- TD_2Document2 pagesTD_2stephane anonPas encore d'évaluation
- Kiyosaki Robert T. Le Quadrant Du Cashflow PDFDocument178 pagesKiyosaki Robert T. Le Quadrant Du Cashflow PDFADJOUMANI87% (15)
- ExamDocument2 pagesExamanibelsoul100% (1)
- Série N°4 Gestion Comptable Des Stocks Bac 2022-2023Document4 pagesSérie N°4 Gestion Comptable Des Stocks Bac 2022-2023maaloulfarah8Pas encore d'évaluation
- Exercice Compta KchiriDocument9 pagesExercice Compta KchiriTàHàà ZRPas encore d'évaluation
- Normes Comptables InternationalesDocument10 pagesNormes Comptables InternationalesAbdou Diatta100% (1)
- Statuts Renault Sa Ag 15.06.17Document20 pagesStatuts Renault Sa Ag 15.06.17aminata aboudramanePas encore d'évaluation
- Eolienne CorrigeDocument6 pagesEolienne CorrigeJad AyaPas encore d'évaluation
- Liste Dépicerie VégétarienneDocument2 pagesListe Dépicerie Végétariennesandrinemode100% (1)
- Corrigé Oulala A1 - Association FPADocument16 pagesCorrigé Oulala A1 - Association FPAespoirPas encore d'évaluation
- Les Pratiques Funéraires Néolithiques Avant 3500 Av J-C en France Et Dans Les Régions LimitrophesDocument310 pagesLes Pratiques Funéraires Néolithiques Avant 3500 Av J-C en France Et Dans Les Régions LimitrophesGerardo Gómez RuizPas encore d'évaluation
- Cloud ComputingDocument25 pagesCloud ComputinghalimPas encore d'évaluation
- Dell Emc Poweredge r650xs Technical Guide FRDocument61 pagesDell Emc Poweredge r650xs Technical Guide FRImen Makhlouf Ben AyedPas encore d'évaluation
- Rapport PFE VFDocument82 pagesRapport PFE VFrarzi12100% (1)
- EN 1090-2 01-07-2010 Cle783afcDocument20 pagesEN 1090-2 01-07-2010 Cle783afcfontainePas encore d'évaluation
- Guide D Accompagnement - Le Petit PoucetDocument15 pagesGuide D Accompagnement - Le Petit Poucetآلبرت خلیلPas encore d'évaluation
- Chapitre 2 Integration NumériqueDocument18 pagesChapitre 2 Integration NumériqueSarah BardiPas encore d'évaluation
- 07 Exos Prod Scalaire Geo RepereeDocument10 pages07 Exos Prod Scalaire Geo RepereeVitaliy BushuevPas encore d'évaluation
- Chap 1Document53 pagesChap 1hamid kamalPas encore d'évaluation
- Assainissement Lit Filtrant (SOTRALENTZ) Fiche-UtilisateurPLASTEPURDocument64 pagesAssainissement Lit Filtrant (SOTRALENTZ) Fiche-UtilisateurPLASTEPURValcenyPas encore d'évaluation
- Memoire FirewallDocument97 pagesMemoire FirewallLou LoulouPas encore d'évaluation
- 0 PDFDocument3 pages0 PDFДжалала ХілаліPas encore d'évaluation
- Liste Principale Des Candidats Admis Au Concours D'accès Au Master GMPMDocument1 pageListe Principale Des Candidats Admis Au Concours D'accès Au Master GMPMOutmane KachachPas encore d'évaluation
- Firestone (Kygo)Document3 pagesFirestone (Kygo)bengt_berglundPas encore d'évaluation
- Bvah 52Document109 pagesBvah 52Harold de MoffartsPas encore d'évaluation
- Marketing Comportement Consommateur DistributionDocument83 pagesMarketing Comportement Consommateur Distributionnguyen100% (2)
- Exposé Durée Du Travail KASSOU FinalDocument27 pagesExposé Durée Du Travail KASSOU FinalAya BaroudiPas encore d'évaluation
- Bilan Hydrique Des Sols Et Recharge de La Nappe Profonde de La Plaine Du Gharb (Maroc) PDFDocument7 pagesBilan Hydrique Des Sols Et Recharge de La Nappe Profonde de La Plaine Du Gharb (Maroc) PDFBck RymPas encore d'évaluation
- Presentation SoutenanceDocument25 pagesPresentation Soutenancemorris DUKULYPas encore d'évaluation
- Lettre de Motivation NACHAT OssamaDocument1 pageLettre de Motivation NACHAT OssamaOssama NachatPas encore d'évaluation
- 14 Systeme Éducatif Algérien PDFDocument19 pages14 Systeme Éducatif Algérien PDFZeyneb Enseignante0% (1)
- TD N°3 S.AlimentairesDocument45 pagesTD N°3 S.AlimentairesSagacious IvejutenPas encore d'évaluation
- Guide RDocument797 pagesGuide RKamel KamelPas encore d'évaluation