
Vous aimerez peut-être aussi
- Archi 04Document22 pagesArchi 04Mohnas NassrPas encore d'évaluation
- Poly 05Document5 pagesPoly 05Mohnas NassrPas encore d'évaluation
- Notes 4 PDFDocument4 pagesNotes 4 PDFHanaaPas encore d'évaluation
- Fiche Bic A5 01 Lettres CacheesDocument2 pagesFiche Bic A5 01 Lettres Cacheesmarie-pierre AnceyPas encore d'évaluation
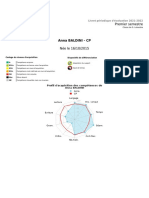
- Bulletin Anna 1er Semestre 21 22Document3 pagesBulletin Anna 1er Semestre 21 22Pauline BaldiniPas encore d'évaluation
- Documents Eleves - CLIS - Lecture - Lecteurs Débutants - Combinatoire Simple-SystematisationDocument49 pagesDocuments Eleves - CLIS - Lecture - Lecteurs Débutants - Combinatoire Simple-SystematisationMohamedPas encore d'évaluation
- Programmation Etude La Langue Et Écriture CE2Document5 pagesProgrammation Etude La Langue Et Écriture CE2Oummou TaymiyyaPas encore d'évaluation
- Analyse Syntaxique BetaDocument50 pagesAnalyse Syntaxique BetaAmine MohsniPas encore d'évaluation
- Analyse Syntaxique - BetaDocument50 pagesAnalyse Syntaxique - BetaMohamed MedPas encore d'évaluation
- Planification Annuelle 5ème AEP en CouleurDocument3 pagesPlanification Annuelle 5ème AEP en CouleurAchraf BouftouhPas encore d'évaluation
- CM1 Org Du 19 Au 23 Fev.Document2 pagesCM1 Org Du 19 Au 23 Fev.May FéghaliPas encore d'évaluation
- Prog CP ArabeDocument2 pagesProg CP ArabedianaPas encore d'évaluation
- Planification de L'unité 4Document1 pagePlanification de L'unité 4aboumya23Pas encore d'évaluation
- RappelDocument4 pagesRappelBenchehida Cherifa100% (1)
- Apprendre A Lire Et A Ecrire L Arabe TypDocument4 pagesApprendre A Lire Et A Ecrire L Arabe TypSadjidine SalifPas encore d'évaluation
- Fiche Lecriture NormaliseeDocument2 pagesFiche Lecriture NormaliseeFélix EKUKWAPas encore d'évaluation
- Leçon AlphabetDocument1 pageLeçon AlphabetGohierPas encore d'évaluation
- Feuille de Révision 2Document2 pagesFeuille de Révision 2lucciana IbrahimPas encore d'évaluation
- Periode 1 Programmation en Phonologie / Vers L'Ecriture Grande SectionDocument2 pagesPeriode 1 Programmation en Phonologie / Vers L'Ecriture Grande SectionVadim HaberPas encore d'évaluation
- Progression Langage Oral Et Ecrit GSDocument6 pagesProgression Langage Oral Et Ecrit GSjosefinedetPas encore d'évaluation
- MT Booklet YourType FRENCH4readDocument32 pagesMT Booklet YourType FRENCH4readCédric ChateauPas encore d'évaluation
- Lure - Circo70.ac Besancon - FR Tableau Des Items CPDocument2 pagesLure - Circo70.ac Besancon - FR Tableau Des Items CPMohamed HamadouPas encore d'évaluation
- 2 TheorieDesLangagesDocument22 pages2 TheorieDesLangagesMoncef ComputerPas encore d'évaluation
- Codage Cycle1 2 Prenoms Decodes Enseignants BickidsDocument4 pagesCodage Cycle1 2 Prenoms Decodes Enseignants Bickidsmarie-pierre AnceyPas encore d'évaluation
- Graphème - WikipédiaDocument8 pagesGraphème - WikipédiaBreton FLORA SOPHIEPas encore d'évaluation
- Participe Present - GerondifDocument7 pagesParticipe Present - Gerondifgalcarolina722202Pas encore d'évaluation
- Ch2 Compilation Analyse LexicaleDocument42 pagesCh2 Compilation Analyse LexicaleMorad EL MASLOUHYPas encore d'évaluation
- Carte Mentale Expression LitteraleDocument1 pageCarte Mentale Expression LitteralemyraneschoolPas encore d'évaluation
- M1 Comparaison Ferreiro FijalkowDocument1 pageM1 Comparaison Ferreiro Fijalkowgaspar 70Pas encore d'évaluation
- Aide Liste de Caractères SpéciauxDocument20 pagesAide Liste de Caractères SpéciauxMarco RodriguezPas encore d'évaluation
- Cours5 HandoutDocument105 pagesCours5 HandoutChristian KapelaPas encore d'évaluation
- Planning MSDocument5 pagesPlanning MSAna ÏssePas encore d'évaluation
- Chap II Analyse LexicaleDocument17 pagesChap II Analyse LexicaleAchraf DebailiaPas encore d'évaluation
- Analyser Un ManuelDocument1 pageAnalyser Un Manuelvincent.legallPas encore d'évaluation
- Cours 3Document38 pagesCours 3zakaria el kazdamPas encore d'évaluation
- توزيع سنوي فرنسية المستوى السادس Le Français PratiqueDocument2 pagesتوزيع سنوي فرنسية المستوى السادس Le Français PratiqueMohamed El OuahdaniPas encore d'évaluation
- Outil de Transcription Phonétique À Partir Du Texte Arabe: Fayçal Imedjdouben Amrane HouacineDocument8 pagesOutil de Transcription Phonétique À Partir Du Texte Arabe: Fayçal Imedjdouben Amrane HouacineedouardPas encore d'évaluation
- Choixtypo ExtraitDocument90 pagesChoixtypo ExtraitismailasriPas encore d'évaluation
- GS FrancaisDocument3 pagesGS FrancaisVenuti AnnalisaPas encore d'évaluation
- Resultat Demande de Psi en CoursDocument3 pagesResultat Demande de Psi en Courskalinka.galaudPas encore d'évaluation
- GARS TranscriptionsDocument3 pagesGARS Transcriptionssirine WhbsPas encore d'évaluation
- Les Sons 2Document15 pagesLes Sons 2elaiche imanePas encore d'évaluation
- Chapitre 4Document65 pagesChapitre 4info plusPas encore d'évaluation
- Exercices Fascicule Phonologie Valeur Des LettresDocument4 pagesExercices Fascicule Phonologie Valeur Des LettresvanialaPas encore d'évaluation
- Chapitre2 Comp2018Document26 pagesChapitre2 Comp2018Nahrawess SlamaPas encore d'évaluation
- Déroulement4AP Projet1 Séquence1Document2 pagesDéroulement4AP Projet1 Séquence1Hicham30100% (1)
- Théorie Des Langages.Document23 pagesThéorie Des Langages.fatima elfaghirPas encore d'évaluation
- Répartition 1A TCL (V2)Document1 pageRépartition 1A TCL (V2)Randa MelPas encore d'évaluation
- Cours de Compilation FDocument137 pagesCours de Compilation FouthmaneoudrhiriPas encore d'évaluation
- Cours - Compilation SMI S5Document130 pagesCours - Compilation SMI S5Ahmed kingPas encore d'évaluation
- Didactique Du Français Prim PhonologieDocument75 pagesDidactique Du Français Prim PhonologielajouPas encore d'évaluation
- Répartition 4APDocument3 pagesRépartition 4APEnseignante MahmoudiPas encore d'évaluation
- Choixtypo 2022 ExtraitDocument62 pagesChoixtypo 2022 ExtraitAm HajjiPas encore d'évaluation
- Progfrce 1Document3 pagesProgfrce 1TouvenantPas encore d'évaluation
- Serie2TLAIng2013 2014Document2 pagesSerie2TLAIng2013 2014Ghazouani HaythemPas encore d'évaluation
- CoursDocument167 pagesCoursimaneeaouattaheePas encore d'évaluation
- Analyseur SyntaxiqueLL1Document51 pagesAnalyseur SyntaxiqueLL1yahya bennisPas encore d'évaluation
- 1 A 12 Ex CP Graphemes BDG 09 Light 2020 PDFDocument13 pages1 A 12 Ex CP Graphemes BDG 09 Light 2020 PDFNourdine MAOULIDA100% (1)
- Poly 01Document8 pagesPoly 01Mohnas NassrPas encore d'évaluation
- Poly 02Document6 pagesPoly 02Mohnas NassrPas encore d'évaluation
- Poly 03Document5 pagesPoly 03Mohnas NassrPas encore d'évaluation
- Archi 01Document45 pagesArchi 01Mohnas NassrPas encore d'évaluation
- Archi 03Document36 pagesArchi 03Mohnas NassrPas encore d'évaluation
- Archi 02Document67 pagesArchi 02Mohnas NassrPas encore d'évaluation
- Archi 05Document26 pagesArchi 05Mohnas NassrPas encore d'évaluation
- Arenal 2016Document2 pagesArenal 2016Mohnas NassrPas encore d'évaluation
- DS2 2020 Num ASCII Trame Courte Distance SujetADocument3 pagesDS2 2020 Num ASCII Trame Courte Distance SujetAEvan MandjouranisPas encore d'évaluation
- Serie TD 2Document2 pagesSerie TD 2maîgaPas encore d'évaluation
- Td1 Electronic-Num Elhanaoui FSTEDocument2 pagesTd1 Electronic-Num Elhanaoui FSTEtariqPas encore d'évaluation
- Le Codage BinaireDocument20 pagesLe Codage BinaireMourad El BioudPas encore d'évaluation
- TexteDocument3 pagesTexteZaza RatsiPas encore d'évaluation
- 1-Corbeille D'exercices TransmissionDocument2 pages1-Corbeille D'exercices TransmissionBoboy YOUSSAOU ISMAILAPas encore d'évaluation
- Chap 5 Les Types de BaseDocument5 pagesChap 5 Les Types de Baseamal saidaniPas encore d'évaluation
- rdv1 Key U1Document6 pagesrdv1 Key U1MirePas encore d'évaluation
- Examen TicDocument5 pagesExamen TicHamdi BenPas encore d'évaluation
- Serie TD2Document6 pagesSerie TD2Sarah NourPas encore d'évaluation
- Devoir de Synthèse N°1 - Génie Électrique - 3ème Technique (2012-2013) MR KhiariDocument5 pagesDevoir de Synthèse N°1 - Génie Électrique - 3ème Technique (2012-2013) MR KhiariAbidi NawresPas encore d'évaluation
- Typographie Et Mise en PagesDocument14 pagesTypographie Et Mise en PagesJean Bon100% (1)
- Arithmétique BinaireDocument6 pagesArithmétique BinaireGoumidi MohamedPas encore d'évaluation
- 6 Codes CorrecteursDocument5 pages6 Codes CorrecteursAbdelaziz IzzoPas encore d'évaluation
- Cri td1Document2 pagesCri td1Douceur D'étéPas encore d'évaluation
- Ao 1 TDDocument2 pagesAo 1 TDBerbaoui KamelPas encore d'évaluation
- Systemes de Numeration Et CodageDocument3 pagesSystemes de Numeration Et CodageBader BelhamoumiaPas encore d'évaluation
- Test n2 Correction Reduit2 PDFDocument10 pagesTest n2 Correction Reduit2 PDFSoufiane BoulachgourPas encore d'évaluation
- Controle Terminal 2019 2020 RSTDocument3 pagesControle Terminal 2019 2020 RSTHachette MapedPas encore d'évaluation
- Recueil 2Document5 pagesRecueil 2Salah KmadouPas encore d'évaluation
- Caracteres - Codes ASCIIDocument4 pagesCaracteres - Codes ASCIIpegojunior2Pas encore d'évaluation
- Série D'exercices N°1 Operations Arithmétiques - CorrectionDocument3 pagesSérie D'exercices N°1 Operations Arithmétiques - CorrectionEllios EMAILPas encore d'évaluation
- Share RibDocument1 pageShare RibBabaye BabayePas encore d'évaluation
- Systèmes de Numération ExoDocument4 pagesSystèmes de Numération ExoIrie Fabrice ZRO100% (1)
- Intro Réseaux - 05 - Calcul Binaire Et HexadécimalDocument15 pagesIntro Réseaux - 05 - Calcul Binaire Et HexadécimalAbderrahman ZianiPas encore d'évaluation
- TNBB 31Document43 pagesTNBB 31Amina BoujeglatPas encore d'évaluation
- Programmation Lecteur Code BarreDocument41 pagesProgrammation Lecteur Code BarreTsara Mahaliana Mety AmikoPas encore d'évaluation
- Chapitre 1 Cours Algorithmique Et Programmation 1Document36 pagesChapitre 1 Cours Algorithmique Et Programmation 1asmae el haiadPas encore d'évaluation
- Examen Codage Compression M1 2019Document2 pagesExamen Codage Compression M1 2019ranacheurfaPas encore d'évaluation
- ELE1300 JCours 02Document32 pagesELE1300 JCours 02Amal MostahfidPas encore d'évaluation
- Le trading en ligne facile à apprendre: Comment devenir un trader en ligne et apprendre à investir avec succèsD'EverandLe trading en ligne facile à apprendre: Comment devenir un trader en ligne et apprendre à investir avec succèsÉvaluation : 3.5 sur 5 étoiles3.5/5 (19)
- Technologie automobile: Les Grands Articles d'UniversalisD'EverandTechnologie automobile: Les Grands Articles d'UniversalisPas encore d'évaluation
- L'analyse technique facile à apprendre: Comment construire et interpréter des graphiques d'analyse technique pour améliorer votre activité de trading en ligne.D'EverandL'analyse technique facile à apprendre: Comment construire et interpréter des graphiques d'analyse technique pour améliorer votre activité de trading en ligne.Évaluation : 3.5 sur 5 étoiles3.5/5 (6)
- Secrets du Marketing des Médias Sociaux 2021: Conseils et Stratégies Extrêmement Efficaces votre Facebook (Stimulez votre Engagement et Gagnez des Clients Fidèles)D'EverandSecrets du Marketing des Médias Sociaux 2021: Conseils et Stratégies Extrêmement Efficaces votre Facebook (Stimulez votre Engagement et Gagnez des Clients Fidèles)Évaluation : 4 sur 5 étoiles4/5 (2)
- Tests de grammaire française: 400 questions pour évaluer vos connaissancesD'EverandTests de grammaire française: 400 questions pour évaluer vos connaissancesÉvaluation : 5 sur 5 étoiles5/5 (3)
- Vocabulaire DELF B2 - 300 expressions pour reussirD'EverandVocabulaire DELF B2 - 300 expressions pour reussirÉvaluation : 4 sur 5 étoiles4/5 (7)
- Dark Python : Apprenez à créer vos outils de hacking.D'EverandDark Python : Apprenez à créer vos outils de hacking.Évaluation : 3 sur 5 étoiles3/5 (1)
- Apprendre Python rapidement: Le guide du débutant pour apprendre tout ce que vous devez savoir sur Python, même si vous êtes nouveau dans la programmationD'EverandApprendre Python rapidement: Le guide du débutant pour apprendre tout ce que vous devez savoir sur Python, même si vous êtes nouveau dans la programmationPas encore d'évaluation
- Wi-Fi Hacking avec kali linux Guide étape par étape : apprenez à pénétrer les réseaux Wifi et les meilleures stratégies pour les sécuriserD'EverandWi-Fi Hacking avec kali linux Guide étape par étape : apprenez à pénétrer les réseaux Wifi et les meilleures stratégies pour les sécuriserPas encore d'évaluation
- L'analyse fondamentale facile à apprendre: Le guide d'introduction aux techniques et stratégies d'analyse fondamentale pour anticiper les événements qui font bouger les marchésD'EverandL'analyse fondamentale facile à apprendre: Le guide d'introduction aux techniques et stratégies d'analyse fondamentale pour anticiper les événements qui font bouger les marchésÉvaluation : 3.5 sur 5 étoiles3.5/5 (4)
- Anglais ( L’Anglais Facile a Lire ) 400 Mots Fréquents (4 Livres en 1 Super Pack): 400 mots fréquents en anglais expliqués en français avec texte bilingueD'EverandAnglais ( L’Anglais Facile a Lire ) 400 Mots Fréquents (4 Livres en 1 Super Pack): 400 mots fréquents en anglais expliqués en français avec texte bilingueÉvaluation : 5 sur 5 étoiles5/5 (2)
- Anglais Pour Les Nulles - Livre Anglais Français Facile A Lire: 50 dialogues facile a lire et photos de los Koalas pour apprendre anglais vocabulaireD'EverandAnglais Pour Les Nulles - Livre Anglais Français Facile A Lire: 50 dialogues facile a lire et photos de los Koalas pour apprendre anglais vocabulaireÉvaluation : 5 sur 5 étoiles5/5 (1)
- Le guide du hacker : le guide simplifié du débutant pour apprendre les bases du hacking avec Kali LinuxD'EverandLe guide du hacker : le guide simplifié du débutant pour apprendre les bases du hacking avec Kali LinuxÉvaluation : 5 sur 5 étoiles5/5 (2)
- DELF B1 - Production Orale - 2800 mots pour réussirD'EverandDELF B1 - Production Orale - 2800 mots pour réussirÉvaluation : 4.5 sur 5 étoiles4.5/5 (12)
- Wireshark pour les débutants : Le guide ultime du débutant pour apprendre les bases de l’analyse réseau avec Wireshark.D'EverandWireshark pour les débutants : Le guide ultime du débutant pour apprendre les bases de l’analyse réseau avec Wireshark.Pas encore d'évaluation
- Le Bon Accord avec le Bon Fournisseur: Comment Mobiliser Toute la Puissance de vos Partenaires Commerciaux pour Réaliser vos ObjectifsD'EverandLe Bon Accord avec le Bon Fournisseur: Comment Mobiliser Toute la Puissance de vos Partenaires Commerciaux pour Réaliser vos ObjectifsÉvaluation : 4 sur 5 étoiles4/5 (2)
- Python | Programmer pas à pas: Le guide du débutant pour une initiation simple & rapide à la programmationD'EverandPython | Programmer pas à pas: Le guide du débutant pour une initiation simple & rapide à la programmationPas encore d'évaluation
- Vocabulaire DELF B2 - 3000 mots pour réussirD'EverandVocabulaire DELF B2 - 3000 mots pour réussirÉvaluation : 4.5 sur 5 étoiles4.5/5 (34)
- Guide Pour Les Débutants En Matière De Piratage Informatique: Comment Pirater Un Réseau Sans Fil, Sécurité De Base Et Test De Pénétration, Kali LinuxD'EverandGuide Pour Les Débutants En Matière De Piratage Informatique: Comment Pirater Un Réseau Sans Fil, Sécurité De Base Et Test De Pénétration, Kali LinuxÉvaluation : 1 sur 5 étoiles1/5 (1)
- Une femme d'Annie Ernaux (Fiche de lecture): Analyse complète et résumé détaillé de l'oeuvreD'EverandUne femme d'Annie Ernaux (Fiche de lecture): Analyse complète et résumé détaillé de l'oeuvreÉvaluation : 5 sur 5 étoiles5/5 (2)
- Réunions gagnantes [Organisation, discussion et communication, soyez performant et constructif]D'EverandRéunions gagnantes [Organisation, discussion et communication, soyez performant et constructif]Pas encore d'évaluation
- Apprendre le turc - Texte parallèle (Français - Turc) Histoires courtesD'EverandApprendre le turc - Texte parallèle (Français - Turc) Histoires courtesÉvaluation : 5 sur 5 étoiles5/5 (1)
- Frankenstein de Mary Shelley (Analyse de l'oeuvre): Comprendre la littérature avec lePetitLittéraire.frD'EverandFrankenstein de Mary Shelley (Analyse de l'oeuvre): Comprendre la littérature avec lePetitLittéraire.frPas encore d'évaluation
- Conception & Modélisation CAO: Le guide ultime du débutantD'EverandConception & Modélisation CAO: Le guide ultime du débutantPas encore d'évaluation
- Apprendre l’allemand - Texte parallèle - Collection drôle histoire (Français - Allemand)D'EverandApprendre l’allemand - Texte parallèle - Collection drôle histoire (Français - Allemand)Évaluation : 3.5 sur 5 étoiles3.5/5 (2)
- Hacking pour débutants : Le guide complet du débutant pour apprendre les bases du hacking avec Kali LinuxD'EverandHacking pour débutants : Le guide complet du débutant pour apprendre les bases du hacking avec Kali LinuxÉvaluation : 4.5 sur 5 étoiles4.5/5 (4)
- Les genres littéraires - Le roman, la poésie et le théâtre (Bac de français)): Réussir le bac de françaisD'EverandLes genres littéraires - Le roman, la poésie et le théâtre (Bac de français)): Réussir le bac de françaisÉvaluation : 1 sur 5 étoiles1/5 (1)





















































































































![Réunions gagnantes [Organisation, discussion et communication, soyez performant et constructif]](https://imgv2-2-f.scribdassets.com/img/word_document/329166427/149x198/15f69349af/1677122311?v=1)





