Vous aimerez peut-être aussi
- Serie1 Variables Aléatoires RéellesDocument4 pagesSerie1 Variables Aléatoires RéellesIbtissem BtnPas encore d'évaluation
- Chapitre IDocument4 pagesChapitre IAyoub HmitouPas encore d'évaluation
- Serie DiscretDocument7 pagesSerie DiscretMêry ÊmPas encore d'évaluation
- Proba CorrectionsDocument95 pagesProba CorrectionsAbdelhaq LahlaliPas encore d'évaluation
- Rappel VA 24Document9 pagesRappel VA 24MD HM BCPas encore d'évaluation
- Cours de Proba 2 2 1Document16 pagesCours de Proba 2 2 1ayumihyesu2Pas encore d'évaluation
- Cours - Math Résumé - Probabilités - Bac Informatique - Bac Informatique (2011-2012) MR Benjeddou Saber PDFDocument7 pagesCours - Math Résumé - Probabilités - Bac Informatique - Bac Informatique (2011-2012) MR Benjeddou Saber PDFAyoub ToujeniPas encore d'évaluation
- Nombres Complexes: Page 1 Sur 16Document16 pagesNombres Complexes: Page 1 Sur 16maryem hamzaPas encore d'évaluation
- Rappel Proba-24Document10 pagesRappel Proba-24MD HM BCPas encore d'évaluation
- Logique Et RaisonnementDocument4 pagesLogique Et RaisonnementYoussouf KoandaPas encore d'évaluation
- Suite Chapitre 1Document3 pagesSuite Chapitre 1Zakaria Ghrissi alouiPas encore d'évaluation
- Cours 1Document5 pagesCours 1FeidangamoPas encore d'évaluation
- Centrale MP 2020-CorrectionDocument5 pagesCentrale MP 2020-Correctionsebastien loyePas encore d'évaluation
- Mathématiques 2: I Décompositions de MatricesDocument4 pagesMathématiques 2: I Décompositions de Matricesabdel dalilPas encore d'évaluation
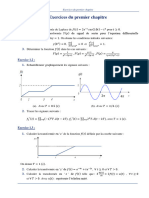
- Exercices Du Premier Chapitre: Exercice 1.1: 1. 2Document2 pagesExercices Du Premier Chapitre: Exercice 1.1: 1. 2Med Djameleddine BougrinePas encore d'évaluation
- P.M.s 15-11-2017Document48 pagesP.M.s 15-11-2017Sana AnesPas encore d'évaluation
- Chapitre 4. Variables AléatoiresDocument11 pagesChapitre 4. Variables Aléatoireslili hadjouraPas encore d'évaluation
- Nombres Complexes CoursDocument8 pagesNombres Complexes Coursthe knowledge is powerPas encore d'évaluation
- Statistique-Non Paramétrique-et-Robustesse-Série Exercices N°2Document11 pagesStatistique-Non Paramétrique-et-Robustesse-Série Exercices N°2karlaugustt1230% (2)
- Devoir 1 Icorp PDFDocument3 pagesDevoir 1 Icorp PDFMathieu Hervé yongouePas encore d'évaluation
- Correction Des Concours 2011 2019Document36 pagesCorrection Des Concours 2011 2019M100% (8)
- Corrigé Examen de Remplacement PST (L3) 22 Féveier 2022Document3 pagesCorrigé Examen de Remplacement PST (L3) 22 Féveier 2022mayar mimiPas encore d'évaluation
- C - Chapitre 2Document4 pagesC - Chapitre 2Mohamed BougatayaPas encore d'évaluation
- BPF TD - OPTIMISATION - DYNAMIQUEDocument24 pagesBPF TD - OPTIMISATION - DYNAMIQUEDivine Djikeng100% (1)
- III Et IV Dérivée Produit QuotientDocument2 pagesIII Et IV Dérivée Produit QuotientUlysse HubertPas encore d'évaluation
- Mathématiques 1: 4 Heures Calculatrice AutoriséeDocument4 pagesMathématiques 1: 4 Heures Calculatrice AutoriséeYahya BelbassiPas encore d'évaluation
- DS 3Document4 pagesDS 3clementdufau5e6Pas encore d'évaluation
- Chapitre 2Document4 pagesChapitre 2kadimiskalliikramPas encore d'évaluation
- TD1 Résolution de Systèmes D'équations LinéairesDocument2 pagesTD1 Résolution de Systèmes D'équations Linéairesjouhaina nasri100% (1)
- TDDenombrementProbabilites CorrigeDocument56 pagesTDDenombrementProbabilites CorrigemayssamPas encore d'évaluation
- Demonstration Au Programme de La TC & TD RDocument3 pagesDemonstration Au Programme de La TC & TD RHabib CastrolePas encore d'évaluation
- Chapitre I Tribu Et Mesure Seance 3Document5 pagesChapitre I Tribu Et Mesure Seance 3Hassib YounesPas encore d'évaluation
- Mathematiques 2021-ENSA t11hAUNN1vbAwmTDocument2 pagesMathematiques 2021-ENSA t11hAUNN1vbAwmTWail Mansour MansouriPas encore d'évaluation
- Introduction A La Methode Des Elements FinisDocument71 pagesIntroduction A La Methode Des Elements FinisWilfried FaboPas encore d'évaluation
- Corrigé de La Série N°2 PDFDocument3 pagesCorrigé de La Série N°2 PDFMounaim MatiniPas encore d'évaluation
- 20VA2Document7 pages20VA2Florian DutroncPas encore d'évaluation
- ENSAE Section: AS1 Travaux Dirigés: Algèbre 1 Fiche 1 2022-2023 Exercice 1Document2 pagesENSAE Section: AS1 Travaux Dirigés: Algèbre 1 Fiche 1 2022-2023 Exercice 1BMGPas encore d'évaluation
- Optimisation 2Document7 pagesOptimisation 2Wiem MelkiPas encore d'évaluation
- Correction 1Document5 pagesCorrection 1maxime ndoumbePas encore d'évaluation
- Chapitre 1 Interpolation 1ere Seance2eme SeanceDocument17 pagesChapitre 1 Interpolation 1ere Seance2eme SeanceSofiane AdrarPas encore d'évaluation
- Loi Student Et FisherDocument5 pagesLoi Student Et FisherRayhane OUANANI100% (1)
- Chapitre 5 - InflationDocument6 pagesChapitre 5 - Inflation2bnpnwx2t9Pas encore d'évaluation
- S2 - Chapitre 1 - Section 1Document37 pagesS2 - Chapitre 1 - Section 1leilarabhi16Pas encore d'évaluation
- SuitesDocument3 pagesSuitesa89440491Pas encore d'évaluation
- Projet Calcul Scientifique-Y-EDocument8 pagesProjet Calcul Scientifique-Y-EYatoute MintoamaPas encore d'évaluation
- Cours Les Suites, Généralités ComplétéDocument3 pagesCours Les Suites, Généralités Complétéoumaymaaouragh5Pas encore d'évaluation
- Devoir Du 20 Janvier2024Document4 pagesDevoir Du 20 Janvier2024Kouassi koffi SimonPas encore d'évaluation
- Chapitre 5 - SDCP 2023Document95 pagesChapitre 5 - SDCP 2023aqwxszecdPas encore d'évaluation
- Solution-TD4 Mathématique StatistiqueDocument3 pagesSolution-TD4 Mathématique Statistiquedjennad.kh99Pas encore d'évaluation
- TD-Maths-09 Suites Num ®riques D200426Document21 pagesTD-Maths-09 Suites Num ®riques D200426M'KHEITIRATT Ahmd100% (1)
- Centrale 2019 MP M2 EnonceDocument4 pagesCentrale 2019 MP M2 EnonceHoussein EL GHARSPas encore d'évaluation
- Poly AlgebreDocument54 pagesPoly AlgebreBintou RassoulPas encore d'évaluation
- Resume Stat-1Document7 pagesResume Stat-1amourPas encore d'évaluation
- Mathématiques 1: 4 Heures Calculatrice AutoriséeDocument4 pagesMathématiques 1: 4 Heures Calculatrice Autoriséeyassirtm el outmaniPas encore d'évaluation
- Cours 1 Et 2Document6 pagesCours 1 Et 2Wala LakhalPas encore d'évaluation
- Chapitre 1Document4 pagesChapitre 1Zakaria Ghrissi alouiPas encore d'évaluation
- ANSérie 1Document2 pagesANSérie 1abahawi07Pas encore d'évaluation
- Analyse Plusieurs Variables CoursDocument98 pagesAnalyse Plusieurs Variables Coursnguyenthehoang100% (1)
- Variables Aleatoires ContinueDocument44 pagesVariables Aleatoires Continuenguyenthehoang100% (1)
- Calcul IntegralesDocument33 pagesCalcul Integralesnguyenthehoang100% (1)
- L1 MathsDocument122 pagesL1 Mathsnguyenthehoang100% (1)
- Analyse Plusieurs Variables CoursDocument98 pagesAnalyse Plusieurs Variables Coursnguyenthehoang100% (1)
- TD Proba-Stat-UPB 2019-2020Document4 pagesTD Proba-Stat-UPB 2019-2020Mannois CharovierPas encore d'évaluation
- Cours Probabilité PDFDocument32 pagesCours Probabilité PDFMohamed OudenniPas encore d'évaluation
- ProbabilitésDocument22 pagesProbabilitésdjiddjiPas encore d'évaluation
- Exercices Corrigés de Statistiques Et ProbabilitésDocument69 pagesExercices Corrigés de Statistiques Et ProbabilitésViorica Mardari50% (2)
- Statistique DescriptiveDocument55 pagesStatistique DescriptiveKellykheirPas encore d'évaluation
- Résumé Proba Chap I Et IIDocument10 pagesRésumé Proba Chap I Et IIYassinePas encore d'évaluation
- Organisation Des Etudes 2014-2015Document152 pagesOrganisation Des Etudes 2014-2015AdahylPas encore d'évaluation
- Sommes de Variables Aléatoires - Cours 2 Correction PDFDocument3 pagesSommes de Variables Aléatoires - Cours 2 Correction PDFxeffixPas encore d'évaluation
- Fiche 1Document2 pagesFiche 1ozelhesaptirbuPas encore d'évaluation
- TDs Proba Lois Binomiale Poisson Normale VoussoirsDocument3 pagesTDs Proba Lois Binomiale Poisson Normale VoussoirsStéphanie Océane NadjiPas encore d'évaluation
- Corrigé de L'exercice 1 de Statistique DescriptiveDocument2 pagesCorrigé de L'exercice 1 de Statistique DescriptiveJean Lotus0% (1)
- Chapitre 2 Théorie Des Probabilités LahraouaDocument43 pagesChapitre 2 Théorie Des Probabilités LahraouakhadijaPas encore d'évaluation
- Pr. AIT CHEIKH Cours S2 Probabilité FSJES Casa Chap 0Document24 pagesPr. AIT CHEIKH Cours S2 Probabilité FSJES Casa Chap 0hajarPas encore d'évaluation
- Erlang-B Traffic TableDocument1 pageErlang-B Traffic TableSwifty SpotPas encore d'évaluation
- Probabilites Et Simulation AleatoireDocument173 pagesProbabilites Et Simulation Aleatoireapi-3737025Pas encore d'évaluation
- Vrai TD2Document4 pagesVrai TD2Daniel MafoutaPas encore d'évaluation
- Statistique InformatiqueDocument32 pagesStatistique InformatiquelorPas encore d'évaluation
- STATISTIQUESDocument11 pagesSTATISTIQUESNelchaël DadjoPas encore d'évaluation
- PS-CHAP 1 - Statistique DescriptiveDocument106 pagesPS-CHAP 1 - Statistique DescriptiveYoussef FahmyPas encore d'évaluation
- BTS Cours 12 EchantillonageDocument6 pagesBTS Cours 12 EchantillonageAnonymous g2H9Cd0% (1)
- Econométrie Des Séries Chronologiques Modèle ARIMA ARCH GARCHDocument35 pagesEconométrie Des Séries Chronologiques Modèle ARIMA ARCH GARCHHassan RehaimiPas encore d'évaluation
- Inferene 4Document39 pagesInferene 4anasPas encore d'évaluation
- Livre Du Professeur - Chapitre 13 - Sommes de Variables AléatoiresDocument39 pagesLivre Du Professeur - Chapitre 13 - Sommes de Variables Aléatoiresel RaphirPas encore d'évaluation
- Loi NormaleDocument8 pagesLoi Normaleali azeroualPas encore d'évaluation
- Chapitre 5Document23 pagesChapitre 5Hamza ElgadiPas encore d'évaluation
- Chapitre 2Document48 pagesChapitre 2Harold CarterPas encore d'évaluation
- 1es Loi Binomiale Exercices Corrige PDFDocument5 pages1es Loi Binomiale Exercices Corrige PDFMokhtarBensaidPas encore d'évaluation
- Annexe1 MathAppli 1aDocument30 pagesAnnexe1 MathAppli 1aRomain MeurantPas encore d'évaluation
- Resume Du Cours - Partie IIIDocument33 pagesResume Du Cours - Partie IIImotivation31102001Pas encore d'évaluation
- TP1 RosalieBerthelot IngaBasanzeDocument13 pagesTP1 RosalieBerthelot IngaBasanzeRosalie BerthelotPas encore d'évaluation