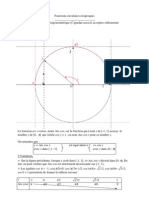
Vous aimerez peut-être aussi
- Annales de Mathématiques, Baccalauréat C et E, Cameroun, 2008 - 2018: Sujets et CorrigésD'EverandAnnales de Mathématiques, Baccalauréat C et E, Cameroun, 2008 - 2018: Sujets et CorrigésÉvaluation : 4.5 sur 5 étoiles4.5/5 (4)
- Topologie Des Espaces Vectoriels Normés Corrigé PDFDocument15 pagesTopologie Des Espaces Vectoriels Normés Corrigé PDFNHS75% (4)
- Cours - Construction Métallique - 1 - Chapitre - 3 - Eléments FléchisDocument55 pagesCours - Construction Métallique - 1 - Chapitre - 3 - Eléments FléchisMezni100% (1)
- Concours Iscae 2015 Correction Ect2Document21 pagesConcours Iscae 2015 Correction Ect2Soufian Bahia100% (1)
- Correction TD MASDocument12 pagesCorrection TD MASHassan Guenzaouz100% (4)
- Controle de Gestion PublicDocument17 pagesControle de Gestion PublicNOUHAILA BRIBERPas encore d'évaluation
- TD3+Solution Thermodynamique Et Chimie Des SolutionsDocument5 pagesTD3+Solution Thermodynamique Et Chimie Des SolutionsDoudou AminePas encore d'évaluation
- Étude de Cas de L' EntrepriseDocument16 pagesÉtude de Cas de L' EntrepriseRed Wane43% (7)
- TD 2 CorrigeDocument6 pagesTD 2 Corrigeamrane mounirPas encore d'évaluation
- 16équations Differentielles Exercices Corrigés 02Document6 pages16équations Differentielles Exercices Corrigés 02koruko basketPas encore d'évaluation
- Concours Commun Mines-Ponts (CCMP) 2020 MP Mathématiques 2 eDocument6 pagesConcours Commun Mines-Ponts (CCMP) 2020 MP Mathématiques 2 emamamia9981235Pas encore d'évaluation
- Centrale MP 2021: Epreuve 2 Un Corrig e I. in Egalit e Polynomiale de Bernstein Et ApplicationsDocument10 pagesCentrale MP 2021: Epreuve 2 Un Corrig e I. in Egalit e Polynomiale de Bernstein Et ApplicationsRhrbrjPas encore d'évaluation
- Sec Mines 2006 Mathsspe PDFDocument4 pagesSec Mines 2006 Mathsspe PDFprepamontaPas encore d'évaluation
- X Ens MP 2015 Maths 4 EpreuveDocument5 pagesX Ens MP 2015 Maths 4 EpreuvefocusssmodePas encore d'évaluation
- Composition 2nd Semestre TS1 2018 LAF WWW - Axloutoth.snDocument3 pagesComposition 2nd Semestre TS1 2018 LAF WWW - Axloutoth.snASSANE NDIRPas encore d'évaluation
- BesselDocument12 pagesBesselKadidja FofanaPas encore d'évaluation
- Examen BlancDocument3 pagesExamen BlancIbrahim CoulibalyPas encore d'évaluation
- ExamenIF CorrigeDocument2 pagesExamenIF CorrigeSADOKPas encore d'évaluation
- EquirepartitionDocument2 pagesEquirepartitionAbdellatif ElouarratePas encore d'évaluation
- EstimationSTT2700h17 PDFDocument33 pagesEstimationSTT2700h17 PDFalfredPas encore d'évaluation
- Sommes ProduitsDocument11 pagesSommes ProduitsSam DykePas encore d'évaluation
- TD 4 CorrigeDocument4 pagesTD 4 CorrigeVivo Vivoo VIPas encore d'évaluation
- M PT Ent JMF 02Document6 pagesM PT Ent JMF 02djidossePas encore d'évaluation
- Public2016 C3Document6 pagesPublic2016 C3Mohamed JamaaPas encore d'évaluation
- Algèbre GénéraleDocument48 pagesAlgèbre GénéraleFabrice ArriaPas encore d'évaluation
- Agreg 2010 - LaplacienDocument6 pagesAgreg 2010 - Laplacienbilly debasePas encore d'évaluation
- Exponentielle de MatricesDocument7 pagesExponentielle de MatricesElvis Wilfried PossiPas encore d'évaluation
- Algebre CorDocument4 pagesAlgebre CorEric RatsimbazafyPas encore d'évaluation
- TS SommesDocument4 pagesTS SommesGerardo Geusa100% (1)
- Exo Corrihe SuiteDocument16 pagesExo Corrihe SuiteSoufiyane BourasPas encore d'évaluation
- 5 Les Fonctions Circulaires RéciproquesDocument11 pages5 Les Fonctions Circulaires Réciproqueslvtmath100% (1)
- TD SuitesDocument4 pagesTD Suiteshamzatouhami2005Pas encore d'évaluation
- Correctionexam 1Document6 pagesCorrectionexam 1Babacar NdiayePas encore d'évaluation
- Corrige - CC2 - Calcul Des Structures 2018 - 2019Document5 pagesCorrige - CC2 - Calcul Des Structures 2018 - 2019Aya ChikerPas encore d'évaluation
- DETERMINANTSDocument10 pagesDETERMINANTSibxxxPas encore d'évaluation
- Formulaire TrigoDocument4 pagesFormulaire TrigoEric Leger100% (1)
- DST7 2019Document4 pagesDST7 2019focusssmodePas encore d'évaluation
- Cours 2012Document39 pagesCours 2012alexandre diakhatePas encore d'évaluation
- DS07 Engel SolDocument9 pagesDS07 Engel SolbhffuhPas encore d'évaluation
- Série1 Suites1Document10 pagesSérie1 Suites1bouzidi hamzaPas encore d'évaluation
- Corr TD6Document10 pagesCorr TD6KulqedraPas encore d'évaluation
- Marche Al Atoire Sur Z DDocument4 pagesMarche Al Atoire Sur Z DArthur TigreatPas encore d'évaluation
- Cours Somme Produit Binome de Newton Version ProfDocument5 pagesCours Somme Produit Binome de Newton Version ProfDavid VHOUMBYPas encore d'évaluation
- Variables Aleatoires Corrige Niveau 1Document22 pagesVariables Aleatoires Corrige Niveau 1Ed MichelPas encore d'évaluation
- Oraux 2016 Solutions SiteDocument109 pagesOraux 2016 Solutions SiteProcopiusPas encore d'évaluation
- Cos 1Document2 pagesCos 1asmatopologiePas encore d'évaluation
- Ensam Maths SVT 2015Document2 pagesEnsam Maths SVT 2015Zohra soulamiPas encore d'évaluation
- Cochran 1Document10 pagesCochran 1onuciPas encore d'évaluation
- Ds 1 MP 2022Document3 pagesDs 1 MP 2022mehdi benmassoudPas encore d'évaluation
- Semaine 03Document3 pagesSemaine 03الدعم الجامعيPas encore d'évaluation
- DL PolyDocument8 pagesDL PolyMohamed QuehlaouiPas encore d'évaluation
- Exos CorrigesDocument22 pagesExos CorrigesMohamed BenabdellahPas encore d'évaluation
- DST2 2021cDocument12 pagesDST2 2021csalima hannanePas encore d'évaluation
- dm1 CorrDocument4 pagesdm1 CorrFatima GORINEPas encore d'évaluation
- 2004Document2 pages2004Zaki RibouPas encore d'évaluation
- Exercices L19Document7 pagesExercices L19Hans HermanPas encore d'évaluation
- TD MatlabDocument5 pagesTD MatlabMbarka AadiPas encore d'évaluation
- CorrigeExamen17 18 BerradaDocument4 pagesCorrigeExamen17 18 BerradaAwatif BePas encore d'évaluation
- Cours 2Document9 pagesCours 2Zak BelPas encore d'évaluation
- DS N°05 - CorrectionDocument23 pagesDS N°05 - CorrectionEdward AdounvoPas encore d'évaluation
- TD1 EquaDiff PDFDocument5 pagesTD1 EquaDiff PDFbeckerrolandhPas encore d'évaluation
- RB2 Quelques Rappels Sur Les SeriesDocument21 pagesRB2 Quelques Rappels Sur Les SeriesghaithPas encore d'évaluation
- Banach SteinhausDocument4 pagesBanach SteinhausfocusssmodePas encore d'évaluation
- CochranDocument10 pagesCochranezzouimiimanePas encore d'évaluation
- 21.-Corrige Colle11 Nombres Reels SuitesDocument3 pages21.-Corrige Colle11 Nombres Reels SuitesPeuitoPas encore d'évaluation
- Montage Lobs 5921 - Mise en Page 1Document12 pagesMontage Lobs 5921 - Mise en Page 1Abdoul Aziz ManePas encore d'évaluation
- Faculté Des Sciences Et Techniques (FST) : Université Cheikh Anta Diop (Ucad)Document2 pagesFaculté Des Sciences Et Techniques (FST) : Université Cheikh Anta Diop (Ucad)Saliou DiopPas encore d'évaluation
- Mathematiques de Lassurance Non-VieDocument8 pagesMathematiques de Lassurance Non-VieFouad guennouniPas encore d'évaluation
- 2021.CoursCalculMatricielMiagDocument65 pages2021.CoursCalculMatricielMiagSebastien AssiPas encore d'évaluation
- Projectile en MVTDocument3 pagesProjectile en MVTotcs766611Pas encore d'évaluation
- Examen1 Réseaux Électriques IndustrielsDocument6 pagesExamen1 Réseaux Électriques IndustrielsGACEM KARIMPas encore d'évaluation
- Travail Memoire EspoirDocument105 pagesTravail Memoire EspoirEspoirPas encore d'évaluation
- La Maintenance Du RéseauDocument61 pagesLa Maintenance Du RéseauSTRATEGIE JEUNESSEPas encore d'évaluation
- Директен и индиректен говорDocument9 pagesДиректен и индиректен говорDejan SpasenoskiPas encore d'évaluation
- Le MarchéDocument2 pagesLe MarchéMOAD MARDASPas encore d'évaluation
- VR7887 U508218 Maint FR Rev4Document18 pagesVR7887 U508218 Maint FR Rev4Aliou SouanePas encore d'évaluation
- Gestion Du Crédit Client Des Sociétés en Difficulté Financière Et Coûts Indirects de FailliteDocument12 pagesGestion Du Crédit Client Des Sociétés en Difficulté Financière Et Coûts Indirects de FailliteMinette DEMDOUPas encore d'évaluation
- C14.1 Exclusion MutuelleDocument53 pagesC14.1 Exclusion MutuelleYoucef HaddouPas encore d'évaluation
- PTWS 820D - Tablette USP/EP Instrument de Test de DissolutionDocument66 pagesPTWS 820D - Tablette USP/EP Instrument de Test de Dissolutionmohammed younesPas encore d'évaluation
- Glossaire Francais de Qualite PDFDocument6 pagesGlossaire Francais de Qualite PDFEra!Pas encore d'évaluation
- EPS Et Citoyenneté Deouis 1925Document14 pagesEPS Et Citoyenneté Deouis 1925Annis VaranePas encore d'évaluation
- La Transformation DigitaleDocument2 pagesLa Transformation DigitaleLoubinette SKPas encore d'évaluation
- Notice Ballast Aqualight SolutionDocument5 pagesNotice Ballast Aqualight SolutionYanis MariaPas encore d'évaluation
- TD Muscle Squelettique - Activite CardiaqueDocument7 pagesTD Muscle Squelettique - Activite CardiaqueGnandi Bilanté100% (2)
- SMP DéfinitionsDocument23 pagesSMP DéfinitionsAhmed BairisPas encore d'évaluation
- Emd Archi2020-2021+corrigéDocument6 pagesEmd Archi2020-2021+corrigémahdi tahirPas encore d'évaluation
- Discours Thomas SANKARA 8 Mars 1987 PDFDocument17 pagesDiscours Thomas SANKARA 8 Mars 1987 PDFMassa SAKOPas encore d'évaluation
- 1809w Rapport2018 Analyse Bilans LotiDocument92 pages1809w Rapport2018 Analyse Bilans LotimioravahoakaPas encore d'évaluation
- Anémomètres À Fil Ou À Film Chaud PDFDocument7 pagesAnémomètres À Fil Ou À Film Chaud PDFlakehal21Pas encore d'évaluation
- PermeabiliteDocument7 pagesPermeabiliteNabil LebigPas encore d'évaluation