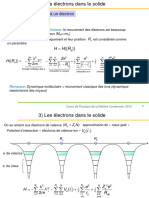
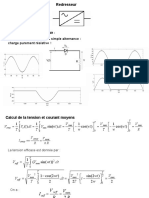
Vous aimerez peut-être aussi
- Slide 6 L'assuranceDocument59 pagesSlide 6 L'assuranceSarah SouidPas encore d'évaluation
- Algèbre Et Theorie GaloisiennesDocument3 pagesAlgèbre Et Theorie GaloisiennesSarah SouidPas encore d'évaluation
- Chapitre 1Document33 pagesChapitre 1Sarah Souid50% (2)
- Illusions D'optiqueDocument2 pagesIllusions D'optiqueThỏTúiPas encore d'évaluation
- La Littérature Comparée - Yves ChevrelDocument99 pagesLa Littérature Comparée - Yves ChevrelCharlotte Wang100% (1)
- Gestion de PortefeuilleDocument21 pagesGestion de PortefeuilleRICHI NINAPas encore d'évaluation
- Gestion de Portefeuille6 1180006633250Document16 pagesGestion de Portefeuille6 1180006633250Albert Diompy P050003Pas encore d'évaluation
- Gestion de Portefeuille6 1180006633250Document16 pagesGestion de Portefeuille6 1180006633250AmineChadiPas encore d'évaluation
- DL4 Pb4Document3 pagesDL4 Pb4Aya DriefPas encore d'évaluation
- Ar Sem12 PMCDocument46 pagesAr Sem12 PMCمحمد الأمير الحازميPas encore d'évaluation
- Cours GPFDocument80 pagesCours GPFhassanPas encore d'évaluation
- Chapitre Ii Les Efforts InternesDocument27 pagesChapitre Ii Les Efforts InternesAYADI IMEDPas encore d'évaluation
- GPF 2Document79 pagesGPF 2ikrame BenrbibePas encore d'évaluation
- Poly L1 2016 TII CorrigeDocument27 pagesPoly L1 2016 TII CorrigeLoundou ortegaPas encore d'évaluation
- ALT - Cours Et TD - Chapitre IIIDocument13 pagesALT - Cours Et TD - Chapitre IIIservice infoPas encore d'évaluation
- La Diode A Jonction PNDocument16 pagesLa Diode A Jonction PNIbrahim GakoPas encore d'évaluation
- Mecanique de Point MIP S2Document34 pagesMecanique de Point MIP S2Ikounad YassinePas encore d'évaluation
- MVA Approximation CybenkoThm Slides PDFDocument25 pagesMVA Approximation CybenkoThm Slides PDFMhiri FadouaPas encore d'évaluation
- Chapitre 2 Applications Des Amplificateurs OperationnelsDocument20 pagesChapitre 2 Applications Des Amplificateurs OperationnelsMarouane TaibiniPas encore d'évaluation
- Résumé ElectrostatiqueDocument3 pagesRésumé ElectrostatiqueAbdelfattah TefatPas encore d'évaluation
- 10 - Puissances Et HarmoniquesDocument12 pages10 - Puissances Et HarmoniquesSoumia MOULOUDIPas encore d'évaluation
- Cours6 7Document32 pagesCours6 7Eva Eva-BellaPas encore d'évaluation
- L'espace Vectoriel: 1. Vecteurs deDocument13 pagesL'espace Vectoriel: 1. Vecteurs deIssa SangarePas encore d'évaluation
- Cours de Mécanique Des Solides Version 2020 PDFDocument55 pagesCours de Mécanique Des Solides Version 2020 PDFÃh Mëd Hä MdįPas encore d'évaluation
- 2-Rappels Mathematiques PDFDocument8 pages2-Rappels Mathematiques PDFFox BenPas encore d'évaluation
- TP2 TNS RT4Document2 pagesTP2 TNS RT4Selima GadriPas encore d'évaluation
- TD C PDFDocument3 pagesTD C PDFAbelard Ricky MugishaPas encore d'évaluation
- Puissance DeformanteDocument17 pagesPuissance DeformantetliarPas encore d'évaluation
- CHMP Demi Anneau PDFDocument1 pageCHMP Demi Anneau PDFKhalid ZegPas encore d'évaluation
- 2019 - 20 Analogique Avec Correction VisibleDocument5 pages2019 - 20 Analogique Avec Correction Visibletristan.baudlotPas encore d'évaluation
- Prep TP3 PDFDocument5 pagesPrep TP3 PDFHanane BelazizPas encore d'évaluation
- Chapitre2 Theorie Elementaire de La RDMDocument16 pagesChapitre2 Theorie Elementaire de La RDMAzertyu KaoutitPas encore d'évaluation
- Chapitre 2Document5 pagesChapitre 2Tahaer McaPas encore d'évaluation
- 6-Chapitre VIDocument8 pages6-Chapitre VIElogri AdnanePas encore d'évaluation
- Exposants de Lyapunov FrancaisDocument7 pagesExposants de Lyapunov FrancaisdougbenPas encore d'évaluation
- Cours de RDMDocument133 pagesCours de RDMRomaric TchakoutePas encore d'évaluation
- Finance de Marche Et Theorie Du PortefeuilleDocument46 pagesFinance de Marche Et Theorie Du PortefeuilleSafae BelmazouziPas encore d'évaluation
- 02.3 - Outils Mathematiques Derivee VectorielleDocument7 pages02.3 - Outils Mathematiques Derivee VectorielleAnime بالعربي 2Pas encore d'évaluation
- Cours EP S1-2Document9 pagesCours EP S1-2abdelfattah hamidouchePas encore d'évaluation
- Induction: I. Dispositifs À Induction Dans Un VéhiculeDocument1 pageInduction: I. Dispositifs À Induction Dans Un VéhiculeYouness BilouchePas encore d'évaluation
- Le MEDAFDocument6 pagesLe MEDAFmsidoPas encore d'évaluation
- Chapitre 1séance 12Document32 pagesChapitre 1séance 12Lotfi BelhadjPas encore d'évaluation
- SgnSys 04 TransfoFourierDocument19 pagesSgnSys 04 TransfoFourierCÖPA SODAZINDJIPas encore d'évaluation
- Puissance DeformanteDocument12 pagesPuissance Deformantearnaud29100% (1)
- Homo JonctionDocument32 pagesHomo JonctionSaadElHafidiPas encore d'évaluation
- °°cours Mecanique Solide FPK Sma4 2020Document43 pages°°cours Mecanique Solide FPK Sma4 2020eabdellatifPas encore d'évaluation
- Chapitre 4 Les Filtres Actifs PDFDocument12 pagesChapitre 4 Les Filtres Actifs PDFBrahim BakhachPas encore d'évaluation
- Chapitre 5Document9 pagesChapitre 5younessPas encore d'évaluation
- Corrigé E3A 2008 PSIDocument4 pagesCorrigé E3A 2008 PSIGaet MgntPas encore d'évaluation
- Corrigé de L'exercice N°1Document13 pagesCorrigé de L'exercice N°1Najile HamzaPas encore d'évaluation
- Chap5Lois ContinuesDocument7 pagesChap5Lois ContinuesNisrine SalihPas encore d'évaluation
- Chap5Lois ContinuesDocument7 pagesChap5Lois ContinuesAmir MohamedPas encore d'évaluation
- Chapitre 2 - Diodes À Jonction PNDocument50 pagesChapitre 2 - Diodes À Jonction PNSoufiane OuassouPas encore d'évaluation
- Assets PricingDocument19 pagesAssets PricingRené TchuidjangPas encore d'évaluation
- Chapitre2 Antennes 2dni PDFDocument17 pagesChapitre2 Antennes 2dni PDFkacel marzoukPas encore d'évaluation
- 5 - Fonctions Numeriques 14-15Document11 pages5 - Fonctions Numeriques 14-15ndoumaPas encore d'évaluation
- Cours Suites Numériques Partie2Document5 pagesCours Suites Numériques Partie2samvipPas encore d'évaluation
- TD1 Ray Antenne Master 2016 17Document4 pagesTD1 Ray Antenne Master 2016 17Joseph NajaPas encore d'évaluation
- Module 15: Mécanique Du Solide (Cours)Document121 pagesModule 15: Mécanique Du Solide (Cours)Mohamed SmimahPas encore d'évaluation
- TH5317Document106 pagesTH5317Sarah SouidPas encore d'évaluation
- Poly Stat Bay 123Document45 pagesPoly Stat Bay 123Sarah SouidPas encore d'évaluation
- 444-1797-Aissani Boukhetala Modelisation Stochastique Statistique MSS4 2018NDocument262 pages444-1797-Aissani Boukhetala Modelisation Stochastique Statistique MSS4 2018NSarah SouidPas encore d'évaluation
- Les Emprunts IndivisDocument57 pagesLes Emprunts IndivisSarah SouidPas encore d'évaluation
- L'intérêt Simple Et L'intérêt ComposéDocument92 pagesL'intérêt Simple Et L'intérêt ComposéSarah SouidPas encore d'évaluation
- Les AnnuitésDocument37 pagesLes AnnuitésSarah SouidPas encore d'évaluation
- 141 Ec1vent3aDocument11 pages141 Ec1vent3afatma addemiPas encore d'évaluation
- Echtd-TD12 Filtrage LineaireDocument16 pagesEchtd-TD12 Filtrage LineaireAmine El messrarPas encore d'évaluation
- 5b37261d3d9b3 PDFDocument116 pages5b37261d3d9b3 PDFIssa KABOREPas encore d'évaluation
- EDO EDP m1-td5-2020Document4 pagesEDO EDP m1-td5-2020Marc TentiPas encore d'évaluation
- Les Éolienne Et Leur ÉtymologieDocument4 pagesLes Éolienne Et Leur ÉtymologieAlex YaddadenPas encore d'évaluation
- TD Andre JelicicDocument59 pagesTD Andre JelicicTôha MaïgaPas encore d'évaluation
- Messagerie Esprit - (1ALINFO) - Programme de La Formation 2022 - 2023Document4 pagesMessagerie Esprit - (1ALINFO) - Programme de La Formation 2022 - 2023Safwen SokerPas encore d'évaluation
- Projet Urbain A NWDocument20 pagesProjet Urbain A NWwassima mebrekPas encore d'évaluation
- Dossier Projet YaplukaDocument30 pagesDossier Projet Yaplukasteve gael MezuiPas encore d'évaluation
- D4.13.Ch3.Exoconduction2 CorrigeDocument7 pagesD4.13.Ch3.Exoconduction2 Corrigehicham0% (1)
- Droit+de+préemption FranceDocument3 pagesDroit+de+préemption FranceoliviacarenekPas encore d'évaluation
- Inventaire de La Ferme AubergeDocument2 pagesInventaire de La Ferme AubergeAli SaadPas encore d'évaluation
- 1.4.2 Representation Des Nombres Au Complement Restreint Ou Logique B-1Document5 pages1.4.2 Representation Des Nombres Au Complement Restreint Ou Logique B-1DialloPas encore d'évaluation
- Mémoire BABA HASSANE Final PDFDocument127 pagesMémoire BABA HASSANE Final PDFSoumana Abdou100% (1)
- La Transamerica Pyramid de San Francisco Et L'école de ChicagoDocument1 pageLa Transamerica Pyramid de San Francisco Et L'école de Chicagojunior_noelPas encore d'évaluation
- Coutume KabylieDocument34 pagesCoutume KabylieSo' FinePas encore d'évaluation
- Matériaux IfpDocument64 pagesMatériaux Ifpsinou.25100% (1)
- IMFCS01Document39 pagesIMFCS01Dang JinlongPas encore d'évaluation
- HD 701s ISO B DC00713Document2 pagesHD 701s ISO B DC00713tazjuan1Pas encore d'évaluation
- Hour Mohamed PresentationDocument34 pagesHour Mohamed PresentationHamza IBAARARENPas encore d'évaluation
- ArtDocument3 pagesArtAnna PapageorgiouPas encore d'évaluation
- Zeneo Notice Installation Utilisation Atlantic PDFDocument84 pagesZeneo Notice Installation Utilisation Atlantic PDFCorentin GuerpinPas encore d'évaluation
- Developpement SensorielleDocument7 pagesDeveloppement Sensoriellezoheir ouffroukhPas encore d'évaluation
- Diderot Chardin Et La Matiere SensibleDocument18 pagesDiderot Chardin Et La Matiere SensibleJose MuñozPas encore d'évaluation
- Les DoriphoriesDocument15 pagesLes DoriphoriesZaordoz Zed100% (1)
- Rapport de PfeDocument122 pagesRapport de PfeFiras Chaabene100% (3)
- Hydraulique Generale 107-139Document33 pagesHydraulique Generale 107-139Soufiane OuassouPas encore d'évaluation
- TD 1 & 2 (Ex & Sol)Document32 pagesTD 1 & 2 (Ex & Sol)SLïmàñ ŢaziaPas encore d'évaluation