Vous aimerez peut-être aussi
- Hymne de Gloire Du Peuple Bamileke (Ghomala)Document13 pagesHymne de Gloire Du Peuple Bamileke (Ghomala)Rodrigue Tchamna100% (2)
- Dossier de Conception - Part 1Document21 pagesDossier de Conception - Part 1Meryam RoussafiPas encore d'évaluation
- Comment Manager Et Mesurer La Performance Industrielle - Techniques de L'ingénieurDocument3 pagesComment Manager Et Mesurer La Performance Industrielle - Techniques de L'ingénieurPolycop FsjestPas encore d'évaluation
- Livre Blanc DevSecOps EVA GROUP Corrige 2Document20 pagesLivre Blanc DevSecOps EVA GROUP Corrige 2jupiterPas encore d'évaluation
- Siemens Simatic Brochure Panels FRDocument17 pagesSiemens Simatic Brochure Panels FRAym BrPas encore d'évaluation
- Elaboration Et Gestion Du Systeme Documentaire Cours 2016 PDFDocument98 pagesElaboration Et Gestion Du Systeme Documentaire Cours 2016 PDFElysee KrizouaPas encore d'évaluation
- ChapitreN1 TVDocument25 pagesChapitreN1 TVhanin ammaniPas encore d'évaluation
- Rapport PFA Supervision FAN PDFDocument31 pagesRapport PFA Supervision FAN PDFIlyas El100% (4)
- Zabbix - PlanDocument7 pagesZabbix - PlanbojtnPas encore d'évaluation
- ZabbixDocument56 pagesZabbixtambori100% (3)
- Control Et Audit de SIDocument28 pagesControl Et Audit de SILamssarbi100% (1)
- TP 2 ApiDocument15 pagesTP 2 ApiYOUNES KABBAJ100% (1)
- Cours ISO 9001 Version 2015 Partie 1Document45 pagesCours ISO 9001 Version 2015 Partie 1smailPas encore d'évaluation
- Examen Intra - Sujet N°2 TIN8 PROGRAMMATION JAVA II - 2020 - 2021Document4 pagesExamen Intra - Sujet N°2 TIN8 PROGRAMMATION JAVA II - 2020 - 2021Imane RouaichiPas encore d'évaluation
- Livre Blanc Supervision 834663Document8 pagesLivre Blanc Supervision 834663Khalil GhaldanePas encore d'évaluation
- C3 DevOps Automatisation Outils 181022Document203 pagesC3 DevOps Automatisation Outils 181022OussamaPas encore d'évaluation
- Chapitres 3 Les Programmes de MonitoringDocument18 pagesChapitres 3 Les Programmes de MonitoringGedeon EtongPas encore d'évaluation
- Introduction GénéraleDocument6 pagesIntroduction GénéraleNOMEDEMPas encore d'évaluation
- PROJET MTU RAVOSON Alain L3 SR N°2225 - CopieDocument3 pagesPROJET MTU RAVOSON Alain L3 SR N°2225 - CopieKenji NatsuhiPas encore d'évaluation
- 10 Pratiques DevopsDocument28 pages10 Pratiques DevopsAhcene AitiPas encore d'évaluation
- Les 5 Pratiques Fondamentales Des DevOpsDocument30 pagesLes 5 Pratiques Fondamentales Des DevOpsWalid RachediPas encore d'évaluation
- chopinaudRJCIA05 PDFDocument14 pageschopinaudRJCIA05 PDFMarcela DobrePas encore d'évaluation
- Chapitre 1Document6 pagesChapitre 1Aziz ben khalifaPas encore d'évaluation
- Supervision Reseaux 21-22Document201 pagesSupervision Reseaux 21-22ouyahermannPas encore d'évaluation
- Projet Supervision Et Management Sur NagiosDocument17 pagesProjet Supervision Et Management Sur NagiosNjokou StephaniePas encore d'évaluation
- 5 Manières de Mettre en Œuvre Le DevSecOps Grâce À L'automatisationDocument9 pages5 Manières de Mettre en Œuvre Le DevSecOps Grâce À L'automatisationjupiterPas encore d'évaluation
- Cahier - Des - Charges - supervisionIT Guides Comparatifs Pour Grands Themas LMI CIODocument28 pagesCahier - Des - Charges - supervisionIT Guides Comparatifs Pour Grands Themas LMI CIOJOHN LUVUEZOPas encore d'évaluation
- Présentationmemoir - GFNDocument24 pagesPrésentationmemoir - GFNGaye Fousseinou NDIAYEPas encore d'évaluation
- CPI L Elaboration D Un Tableau de Bord Pour L Amelioration Continue D Un SIHDocument11 pagesCPI L Elaboration D Un Tableau de Bord Pour L Amelioration Continue D Un SIHGreffina Dahana LouisPas encore d'évaluation
- IntroductionDocument23 pagesIntroductionmohamed sayariPas encore d'évaluation
- Cours de Supervision Et MonitoringDocument16 pagesCours de Supervision Et MonitoringKako NanaPas encore d'évaluation
- Centre D Excellence Laurentide FRDocument8 pagesCentre D Excellence Laurentide FRtrojaniPas encore d'évaluation
- CHAPITRE I1 SupervisionDocument4 pagesCHAPITRE I1 Supervisionkamgabriel920Pas encore d'évaluation
- Solarwinds Product BriefingDocument135 pagesSolarwinds Product BriefingIbrahim BenPas encore d'évaluation
- NAGIOS SuperviseurDocument15 pagesNAGIOS SuperviseurGardedje AlainPas encore d'évaluation
- Chapitre I - DIAGNOSTICDocument6 pagesChapitre I - DIAGNOSTICAssala chellaliPas encore d'évaluation
- Assou Mathias Esgis Iir3 MemoireDocument20 pagesAssou Mathias Esgis Iir3 MemoireAnonymous i3bqG5Pas encore d'évaluation
- Rational Unified Process (RUP)Document13 pagesRational Unified Process (RUP)Maram JemaiPas encore d'évaluation
- Audit Pratique Dans Un Environement VirtuelDocument7 pagesAudit Pratique Dans Un Environement VirtuelMacloutPas encore d'évaluation
- Rapport Groupe4 ReseauDocument23 pagesRapport Groupe4 ReseaulabowaPas encore d'évaluation
- Rapport SupervisionDocument2 pagesRapport SupervisionTahati86Pas encore d'évaluation
- DASA DevOps Fundamentals - Glossary - FrenchDocument20 pagesDASA DevOps Fundamentals - Glossary - FrenchpisofPas encore d'évaluation
- Documentation SMQ Agilium-2Document12 pagesDocumentation SMQ Agilium-2MSELLEKPas encore d'évaluation
- Contrôle de GestionDocument48 pagesContrôle de Gestionadnane boujibarPas encore d'évaluation
- Cours Audit Informatique Module 1Document43 pagesCours Audit Informatique Module 1Christian NgoulouPas encore d'évaluation
- Final Mem OapiDocument163 pagesFinal Mem OapiSonia MbelePas encore d'évaluation
- (PDF) AMDEC - CompressDocument17 pages(PDF) AMDEC - CompressMimouni MohamedPas encore d'évaluation
- SupervisionDocument38 pagesSupervisiontraxirPas encore d'évaluation
- Diagnostic Chap 1Document14 pagesDiagnostic Chap 1i aliliPas encore d'évaluation
- Comment Définir Des Indicateurs Pertinents Pour Mesurer L'efficacité Des Systèmes de Management - QUALIBLOG - Le Blog Du Manager QSEDocument11 pagesComment Définir Des Indicateurs Pertinents Pour Mesurer L'efficacité Des Systèmes de Management - QUALIBLOG - Le Blog Du Manager QSErgePas encore d'évaluation
- Tests End To End 1709031434Document4 pagesTests End To End 1709031434muhamadu.syllaPas encore d'évaluation
- Machine Learning For Computer Security Abeaugnon Pchifflier AnssiDocument16 pagesMachine Learning For Computer Security Abeaugnon Pchifflier AnssiTomPas encore d'évaluation
- Audit INTRODUCTION (Mode de Compatibilité)Document28 pagesAudit INTRODUCTION (Mode de Compatibilité)MőhâmÉèd Mődrîk100% (2)
- Mémoire FFCDocument40 pagesMémoire FFCanassPas encore d'évaluation
- 11 - Ameliorer-La-Productivite-Modele-Devops-DoraDocument9 pages11 - Ameliorer-La-Productivite-Modele-Devops-DoraChristian BibouePas encore d'évaluation
- Methodologie GN-2Document10 pagesMethodologie GN-2younesPas encore d'évaluation
- Elaboration Et Gestion Du Systeme Documentaire Cours 2016 PDFDocument98 pagesElaboration Et Gestion Du Systeme Documentaire Cours 2016 PDFBerdjane nassimaPas encore d'évaluation
- GTAG 2 2e Ed VF 2Document42 pagesGTAG 2 2e Ed VF 2Hamdi OuerfelliPas encore d'évaluation
- BSC Abm AbcDocument31 pagesBSC Abm AbcNajia El YanboiyPas encore d'évaluation
- Revoir Le SMQ en Comité de DirectionDocument3 pagesRevoir Le SMQ en Comité de DirectionrgePas encore d'évaluation
- Super RESEAUDocument2 pagesSuper RESEAUAïcha KomaraPas encore d'évaluation
- Supervision de Bout en BoutDocument2 pagesSupervision de Bout en BoutAmani YAO N'GORANPas encore d'évaluation
- Document PDFDocument11 pagesDocument PDFAmine KaroufPas encore d'évaluation
- Projet Gestion CabinetDocument3 pagesProjet Gestion Cabinetinfo bougarninePas encore d'évaluation
- WWW Lucidchart Com Pages FR Bete A CornesDocument8 pagesWWW Lucidchart Com Pages FR Bete A CornesBouillaPas encore d'évaluation
- Sequence DemarrageDocument14 pagesSequence DemarrageZikas Winners100% (1)
- HP500Document4 pagesHP500Ali BoudjeradaPas encore d'évaluation
- RapportDeStageEsprit TechnicienDocument29 pagesRapportDeStageEsprit TechnicienTayeb AhmedPas encore d'évaluation
- Chap2 Service WebDocument20 pagesChap2 Service WebMerry MPas encore d'évaluation
- Devoir de Contrôle N°3 (Pratique) - Informatique - Bac Lettres (2007-2008)Document2 pagesDevoir de Contrôle N°3 (Pratique) - Informatique - Bac Lettres (2007-2008)Hammadi TunisiePas encore d'évaluation
- JEE7 4 Traitnavigation PDFDocument35 pagesJEE7 4 Traitnavigation PDFYassine NajmiPas encore d'évaluation
- Google Forms A QuoiDocument6 pagesGoogle Forms A QuoiXavier FéardPas encore d'évaluation
- Chap3 ExercicesDocument3 pagesChap3 Exerciceschangi100% (1)
- Tutorial Radio Turnigy 9xDocument8 pagesTutorial Radio Turnigy 9xyeeepaPas encore d'évaluation
- Module de Systemes DistribuesDocument50 pagesModule de Systemes Distribuesيوسف مرزوقPas encore d'évaluation
- TD 2 Uml 2020 PDFDocument1 pageTD 2 Uml 2020 PDFmariem amorPas encore d'évaluation
- EULADocument5 pagesEULAcostingyPas encore d'évaluation
- Correction tp2 PHPDocument7 pagesCorrection tp2 PHPImane OuPas encore d'évaluation
- FraudeDocument5 pagesFraudeapi-636275608Pas encore d'évaluation
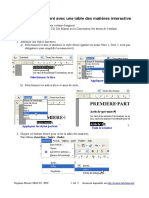
- Creer Table Des MatieresDocument3 pagesCreer Table Des MatieresSamsung SamsungPas encore d'évaluation
- S2 - Evaluation Pratique N°1Document1 pageS2 - Evaluation Pratique N°1Oumaima KasdiPas encore d'évaluation
- Cours MicroservicesDocument18 pagesCours MicroservicesBochra ArfaouiPas encore d'évaluation
- Projet-Tutoré-1 - CopieDocument7 pagesProjet-Tutoré-1 - CopieMed Hacen MoustaphaPas encore d'évaluation
- CV Khalled FullStackDocument2 pagesCV Khalled FullStackkhalled meneoualiPas encore d'évaluation
- A 2 Bcef 525 B 390 DD 68 DF 7Document23 pagesA 2 Bcef 525 B 390 DD 68 DF 7api-722622622Pas encore d'évaluation
- TP4 - BD - Oracle ExpressDocument2 pagesTP4 - BD - Oracle ExpressImane LamdainePas encore d'évaluation
- Fiche Caneco Solar 042011 - FRBDocument2 pagesFiche Caneco Solar 042011 - FRBLino YETONGNONPas encore d'évaluation
- Cours BD Relationnelle CH1Document13 pagesCours BD Relationnelle CH1Meriem BenftimaPas encore d'évaluation
- Projet SESDocument4 pagesProjet SESHello Word :-)Pas encore d'évaluation