Vous aimerez peut-être aussi
- Statistique Chapitre II L1S1Document18 pagesStatistique Chapitre II L1S1koitamama26Pas encore d'évaluation
- Chapitre 2 Partie 1Document8 pagesChapitre 2 Partie 1Brahim MellPas encore d'évaluation
- L'Anova, L'ancova Et Le Modele Lineaire General 080820Document17 pagesL'Anova, L'ancova Et Le Modele Lineaire General 080820Emmanuel DemosthenePas encore d'évaluation
- Math AlgelbreDocument107 pagesMath Algelbremuzingajeannette888Pas encore d'évaluation
- Chapitre 3 Econométrie IDocument16 pagesChapitre 3 Econométrie Iall yPas encore d'évaluation
- Cours Complet Statistique-1Document8 pagesCours Complet Statistique-1Ayoub Bjb100% (1)
- TD: Série N°1: Exercice 1Document1 pageTD: Série N°1: Exercice 1Yahya EllPas encore d'évaluation
- Auto - RésuméDocument4 pagesAuto - RésuméRiham abPas encore d'évaluation
- Matrice PDFDocument10 pagesMatrice PDFAziz-nadalGaddourPas encore d'évaluation
- Fiche 13 CGDocument4 pagesFiche 13 CGAbdellah AzzouzPas encore d'évaluation
- Chapitre 2 - Modèles À Effets IndividuelsDocument41 pagesChapitre 2 - Modèles À Effets Individuelskoffi FayossehPas encore d'évaluation
- Mathématiques 2: 4 Heures Calculatrice AutoriséeDocument4 pagesMathématiques 2: 4 Heures Calculatrice AutoriséeAlexandre LamPas encore d'évaluation
- ME Série N°1Document1 pageME Série N°1Othmane ChPas encore d'évaluation
- Cours de Macrodynamique-Chap4-L3-SECO3-PE-FSEGA,UnivDla-Dec2023Document7 pagesCours de Macrodynamique-Chap4-L3-SECO3-PE-FSEGA,UnivDla-Dec2023freddy coolbyPas encore d'évaluation
- 6 - Cours Statistique - 4 SC 2018Document6 pages6 - Cours Statistique - 4 SC 2018alexgeorge1122Pas encore d'évaluation
- Statistique 2024 L1 S1 El Ment N 1 EDocument63 pagesStatistique 2024 L1 S1 El Ment N 1 Enathanirintsoa09Pas encore d'évaluation
- Centrale Supelec PC 2014 Maths 1 EpreuveDocument3 pagesCentrale Supelec PC 2014 Maths 1 EpreuveOussama SouissiPas encore d'évaluation
- Série N°1 Avec SolutionDocument8 pagesSérie N°1 Avec SolutionTCHONAYE MOLI DJIBRINEPas encore d'évaluation
- CoursDocument2 pagesCoursNicolas AktromPas encore d'évaluation
- Solutions Des Exercices Chapitre EstimationsDocument18 pagesSolutions Des Exercices Chapitre EstimationsSimo MnhPas encore d'évaluation
- Cours2 - Partie 2-Rappels Sur Les Statistiques Bi-VariéeDocument31 pagesCours2 - Partie 2-Rappels Sur Les Statistiques Bi-Variéeabdelalim gacemPas encore d'évaluation
- Resume3-Stats 1 Var-2Document4 pagesResume3-Stats 1 Var-2Zineb BeggarPas encore d'évaluation
- MatricesDocument29 pagesMatricesCherkaoui YassinePas encore d'évaluation
- Outils D Aide A La DecisonDocument5 pagesOutils D Aide A La Decisonhamza benPas encore d'évaluation
- Livre New TC LETTREDocument16 pagesLivre New TC LETTRELahcenLahcenPas encore d'évaluation
- Pr. ELHAMMA Cours - 3 - Regression - MultiplesDocument19 pagesPr. ELHAMMA Cours - 3 - Regression - Multiplesayoub ayoubPas encore d'évaluation
- Guide D'utilisation de Stata - Chapitre 3: July 2017Document17 pagesGuide D'utilisation de Stata - Chapitre 3: July 2017Franck Armand Makay RobalaPas encore d'évaluation
- Elastique Corrigé PoutreDocument9 pagesElastique Corrigé PoutreguessousPas encore d'évaluation
- TD2 L1-MPI CHP Pot Cdteurs 2019-20 CorrectionDocument11 pagesTD2 L1-MPI CHP Pot Cdteurs 2019-20 CorrectionIbrahima SkPas encore d'évaluation
- Statistique-Non Paramétrique-et-Robustesse-Série Exercices N°2Document11 pagesStatistique-Non Paramétrique-et-Robustesse-Série Exercices N°2karlaugustt1230% (2)
- Cours MMC1Document9 pagesCours MMC1Saiid RiadhPas encore d'évaluation
- Sujet de Préparation Aux Concours 1ers1n°1Document3 pagesSujet de Préparation Aux Concours 1ers1n°1laminesidy2007Pas encore d'évaluation
- Formulaire MEF MATDocument15 pagesFormulaire MEF MATAbdelaziz KraaPas encore d'évaluation
- Examen Sem1 Norm L1MPI 2019-2020Document5 pagesExamen Sem1 Norm L1MPI 2019-2020adrame ndiayePas encore d'évaluation
- Introduction Econometrie IIDocument9 pagesIntroduction Econometrie IIClark OberaPas encore d'évaluation
- Deaopkkopcan 9798deaopkkopcan 9798programmation Linéaire 1Document8 pagesDeaopkkopcan 9798deaopkkopcan 9798programmation Linéaire 1Ahmed Tidiane ThiandoumPas encore d'évaluation
- 2 Moyenne, VarianceDocument6 pages2 Moyenne, VariancelvtmathPas encore d'évaluation
- Cours Math - Séries Statistiques Doubles - Bac Sciences (2009-2010) MR Abdelbasset Laataoui PDFDocument10 pagesCours Math - Séries Statistiques Doubles - Bac Sciences (2009-2010) MR Abdelbasset Laataoui PDFamelll84Pas encore d'évaluation
- Cours Sur Les Fonctions Exponentielles TST2SDocument3 pagesCours Sur Les Fonctions Exponentielles TST2SNicolas AktromPas encore d'évaluation
- Chap4 CoursDocument12 pagesChap4 CoursMohamed Akli IDIRPas encore d'évaluation
- Chapitre 1 Etude de La Deformation Du 10-11-2020Document6 pagesChapitre 1 Etude de La Deformation Du 10-11-2020Anwar RekikPas encore d'évaluation
- Contrôle 1Document4 pagesContrôle 1abdelwahabPas encore d'évaluation
- Cours Stat Deux DimensionsDocument13 pagesCours Stat Deux DimensionsroffaaPas encore d'évaluation
- AnavaDocument7 pagesAnavaVaio SonyPas encore d'évaluation
- AMAS Chap4Document64 pagesAMAS Chap4ÏŠłãm Ould ChikhPas encore d'évaluation
- Rappel Sur Les MatricesDocument14 pagesRappel Sur Les MatricesSalim BouaziziPas encore d'évaluation
- Maths CnamDocument68 pagesMaths CnamKonan Donatien AmaniPas encore d'évaluation
- Polycopie Algèbre 2022-2023Document29 pagesPolycopie Algèbre 2022-2023Marouane OuqebliPas encore d'évaluation
- Correction TerminaleComplementaires Statistiques 2021 PDFDocument32 pagesCorrection TerminaleComplementaires Statistiques 2021 PDFبدر الذهابيPas encore d'évaluation
- Examen1 Théorie Du ChampDocument3 pagesExamen1 Théorie Du ChampGACEM KARIMPas encore d'évaluation
- Corrige Serie Correlation Et RegressionDocument10 pagesCorrige Serie Correlation Et RegressionMar Wa100% (1)
- Brochure de TD 2022-23Document19 pagesBrochure de TD 2022-23Ghazi Ben JaballahPas encore d'évaluation
- Cours Statistiques DescriptivesDocument7 pagesCours Statistiques Descriptivestaha elatouiPas encore d'évaluation
- Dérivabilité 2016 2017 (Wissem Fligene)Document6 pagesDérivabilité 2016 2017 (Wissem Fligene)Adam BaccouchePas encore d'évaluation
- Correction TD2Document3 pagesCorrection TD2Amine OuniPas encore d'évaluation
- Correction TD2Document3 pagesCorrection TD2nadinerjaibi15Pas encore d'évaluation
- Cours 1Document5 pagesCours 1FeidangamoPas encore d'évaluation
- TD ReducDocument5 pagesTD ReducqkdjzlzkjaPas encore d'évaluation
- Mathématiques 1: Autour Des Matrices de ToeplitzDocument4 pagesMathématiques 1: Autour Des Matrices de ToeplitzJounid AyoubPas encore d'évaluation
- Équations différentielles: Les Grands Articles d'UniversalisD'EverandÉquations différentielles: Les Grands Articles d'UniversalisPas encore d'évaluation
- Rapport de StageDocument7 pagesRapport de StagebenbadaPas encore d'évaluation
- Memoire ChiakaDocument76 pagesMemoire ChiakaIrie Fabrice ZROPas encore d'évaluation
- Livre ES TS 2020 PDFDocument8 pagesLivre ES TS 2020 PDFYoussef KhalfaPas encore d'évaluation
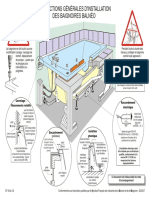
- BalneoDocument2 pagesBalneocloud adsophPas encore d'évaluation
- Infos Complémentaires Balade Et Bonne Mine 2021Document1 pageInfos Complémentaires Balade Et Bonne Mine 2021Christian CouteauPas encore d'évaluation
- Transport Logistique Ministere Des Finances MarocDocument27 pagesTransport Logistique Ministere Des Finances MarocImane BenrahmounePas encore d'évaluation
- Chap5 Complexe en Électricité - 2021-2022Document29 pagesChap5 Complexe en Électricité - 2021-2022Balayira BakaryPas encore d'évaluation
- Table de Contenus EditoDocument5 pagesTable de Contenus EditoDajana KantardžićPas encore d'évaluation
- Inhibiteurs de Pompe À ProtonsDocument1 pageInhibiteurs de Pompe À ProtonsYasmine TarchounPas encore d'évaluation
- SYLLABUS TIME MANAGEMENT Gestion Du Temps Et Des PrioritésDocument2 pagesSYLLABUS TIME MANAGEMENT Gestion Du Temps Et Des PrioritésMamadou GueyePas encore d'évaluation
- Cours Techniques ComDocument81 pagesCours Techniques Comkhalid hammaniPas encore d'évaluation
- Formulaire de Candidature Simplifié INVEST RH - YOUNES BOUAYADDocument2 pagesFormulaire de Candidature Simplifié INVEST RH - YOUNES BOUAYADybouayadPas encore d'évaluation
- RestoDocument2 pagesRestoAbir LatréchePas encore d'évaluation
- Asymétrie D'informationsDocument6 pagesAsymétrie D'informationsDjoufack JanvierPas encore d'évaluation
- Eurochain VL FRDocument8 pagesEurochain VL FRSalaheddine OURPas encore d'évaluation
- 52910Document9 pages52910mostabouPas encore d'évaluation
- Nibridge: Unibridge®: Construire Et ReconstruireDocument2 pagesNibridge: Unibridge®: Construire Et ReconstruireorbediePas encore d'évaluation
- Explication - Louise Labé, Sonnet 8Document2 pagesExplication - Louise Labé, Sonnet 8lyblanc100% (3)
- Ecosystèmes D'affaires & de Connaissances - Une Lecture Suivant Les Analogies Du Jeu de GoDocument94 pagesEcosystèmes D'affaires & de Connaissances - Une Lecture Suivant Les Analogies Du Jeu de GoammoniosPas encore d'évaluation
- Motrec WebManual - E 280B AC - 1131229upDocument61 pagesMotrec WebManual - E 280B AC - 1131229uppedro javier carrera juradoPas encore d'évaluation
- Devoir de Synthèse N°1 2017 2018 (Hidri Lazhar) PDFDocument3 pagesDevoir de Synthèse N°1 2017 2018 (Hidri Lazhar) PDFRabiaa GuesmiPas encore d'évaluation
- 6 7091 E79da38f PDFDocument24 pages6 7091 E79da38f PDFSAEC LIBERTEPas encore d'évaluation
- Balistique - SniperSoricomDocument30 pagesBalistique - SniperSoricomKishore BarreteauPas encore d'évaluation
- Recits D'un Pèlerin RusseDocument160 pagesRecits D'un Pèlerin RusseGuillaume Morgenstern100% (5)
- 01-Principe Des Essais de PuitsDocument13 pages01-Principe Des Essais de Puitsaoua1997100% (1)
- (LA) 2 Racine, Phèdre I3 (Aveu)Document6 pages(LA) 2 Racine, Phèdre I3 (Aveu)koana bshsPas encore d'évaluation
- Acfrogdtvvmhsyokaxk9q9ktmv8ergolx3 8r7mirpt6v0g8ws9791lwm0erykcgoe - Oxnasmm7zamygytzylwahyey2bio4ju6kha9f O-Mtovs31mlbtazlp83rq6izewdexdeitn7oqdxmsdDocument2 pagesAcfrogdtvvmhsyokaxk9q9ktmv8ergolx3 8r7mirpt6v0g8ws9791lwm0erykcgoe - Oxnasmm7zamygytzylwahyey2bio4ju6kha9f O-Mtovs31mlbtazlp83rq6izewdexdeitn7oqdxmsdEL MéhdiPas encore d'évaluation
- RappelHTML WebSémantiqueDocument2 pagesRappelHTML WebSémantiqueNour LetaiefPas encore d'évaluation
- O God Beyond All PraisingDocument3 pagesO God Beyond All Praisingkoyske71% (7)
- TD1 (Resume)Document10 pagesTD1 (Resume)Rayane NouiPas encore d'évaluation