Vous aimerez peut-être aussi
- Von Roll Inova Four GrilleDocument6 pagesVon Roll Inova Four GrilleJamalChakibPas encore d'évaluation
- Les Techniques Électrophorétiques (Protéines Et ADN)Document11 pagesLes Techniques Électrophorétiques (Protéines Et ADN)Ayoub LakhdariPas encore d'évaluation
- Thérapie Par Cellules Souches: Réparer les cellules endommagées pour traiter ou prévenir une maladieD'EverandThérapie Par Cellules Souches: Réparer les cellules endommagées pour traiter ou prévenir une maladiePas encore d'évaluation
- Conductive Polymer: L'industrie médicale est révolutionnée pour l'ingénierie tissulaire et les biocapteurs, pour restaurer des organes entiers ou diagnostiquer des maladies infectieusesD'EverandConductive Polymer: L'industrie médicale est révolutionnée pour l'ingénierie tissulaire et les biocapteurs, pour restaurer des organes entiers ou diagnostiquer des maladies infectieusesPas encore d'évaluation
- Le clônage: Formation O.G.M / Les avantages du clônage / les inconvénients du clônage / Conclusion sur l'importance du clonage / Made by Oussama.Q / De la part d'Oussama.Q / اعداد أسامة قرباش / الاستنساخDocument21 pagesLe clônage: Formation O.G.M / Les avantages du clônage / les inconvénients du clônage / Conclusion sur l'importance du clonage / Made by Oussama.Q / De la part d'Oussama.Q / اعداد أسامة قرباش / الاستنساخOUSSAMA100% (2)
- SérologieDocument18 pagesSérologieazizaPas encore d'évaluation
- Toxicologie Du Cuivre FINALDocument24 pagesToxicologie Du Cuivre FINALYoucef100% (1)
- Élevage: Les Grands Articles d'UniversalisD'EverandÉlevage: Les Grands Articles d'UniversalisPas encore d'évaluation
- Détecteurs de particules: Les Grands Articles d'UniversalisD'EverandDétecteurs de particules: Les Grands Articles d'UniversalisPas encore d'évaluation
- Déserts: Les Grands Articles d'UniversalisD'EverandDéserts: Les Grands Articles d'UniversalisPas encore d'évaluation
- Docteur Jekyll et Mister Hyde de Robert Louis Stevenson (Fiche de lecture): Résumé complet et analyse détaillée de l'oeuvreD'EverandDocteur Jekyll et Mister Hyde de Robert Louis Stevenson (Fiche de lecture): Résumé complet et analyse détaillée de l'oeuvrePas encore d'évaluation
- Article Fourrotatif BouhafsDocument8 pagesArticle Fourrotatif BouhafselamaPas encore d'évaluation
- Métal Amorphe: Le verre métallique mince du futur ressemble à du papier d'aluminium, mais essayez de le déchirer, ou voyez si vous pouvez le couper, de toute votre puissance, pas de chanceD'EverandMétal Amorphe: Le verre métallique mince du futur ressemble à du papier d'aluminium, mais essayez de le déchirer, ou voyez si vous pouvez le couper, de toute votre puissance, pas de chancePas encore d'évaluation
- MicroscopieDocument4 pagesMicroscopielamlam622Pas encore d'évaluation
- Les InterféronsDocument6 pagesLes InterféronsMACON824Pas encore d'évaluation
- L'Iliade d'Homère: Les Fiches de lecture d'UniversalisD'EverandL'Iliade d'Homère: Les Fiches de lecture d'UniversalisPas encore d'évaluation
- Étoiles: Les Grands Articles d'UniversalisD'EverandÉtoiles: Les Grands Articles d'UniversalisPas encore d'évaluation
- Page de Garde PDFDocument2 pagesPage de Garde PDFkolechi dzPas encore d'évaluation
- La Structure BacterienneDocument12 pagesLa Structure Bacteriennebio20Pas encore d'évaluation
- GRATADOUR Michel - Application de La Suralimentation Aux Moteurs PDFDocument22 pagesGRATADOUR Michel - Application de La Suralimentation Aux Moteurs PDFYodaScribdPas encore d'évaluation
- Dzexams 5ap Francais t1 20200 873726Document1 pageDzexams 5ap Francais t1 20200 873726ecole mirabellePas encore d'évaluation
- Fascicule BVI SVT1 2019Document38 pagesFascicule BVI SVT1 2019Lotfi MabroukPas encore d'évaluation
- La Science au présent 2018: Une année d'actualité scientifique et techniqueD'EverandLa Science au présent 2018: Une année d'actualité scientifique et techniquePas encore d'évaluation
- Le Diamètre Des Grilles Est de 3 MMDocument7 pagesLe Diamètre Des Grilles Est de 3 MMOuissem Belkhous100% (1)
- Fiche Ssolaire Thermodynamique IntegraleDocument8 pagesFiche Ssolaire Thermodynamique IntegraleAbdesslam GuennouniPas encore d'évaluation
- Agent InfectieuxDocument4 pagesAgent InfectieuxalmnaouarPas encore d'évaluation
- Circuit ImpriméDocument28 pagesCircuit ImpriméTurbo DieselPas encore d'évaluation
- L'histoire D'un Crime LeDocument105 pagesL'histoire D'un Crime LeErica SagayapPas encore d'évaluation
- Ambiance Physique (Ambiance Thermique)Document13 pagesAmbiance Physique (Ambiance Thermique)Jonathan KacouPas encore d'évaluation
- Sujet TheseDocument9 pagesSujet TheseSamira ElAllaouiPas encore d'évaluation
- Ponction Lombaire - Examen Du Liquide Céphalo-Rachidien (LCR), Interprétation Des Résultats PDFDocument5 pagesPonction Lombaire - Examen Du Liquide Céphalo-Rachidien (LCR), Interprétation Des Résultats PDFJeff StinvilPas encore d'évaluation
- Onduleur5 PDFDocument44 pagesOnduleur5 PDFSamir Fassi FassiPas encore d'évaluation
- Manueldeprelevement PDFDocument82 pagesManueldeprelevement PDFYASMEROPas encore d'évaluation
- Cours Transfert de ChaleurDocument32 pagesCours Transfert de Chaleurslipknotmido1Pas encore d'évaluation
- Les Batteries Au PlombDocument4 pagesLes Batteries Au PlombImed SeghierPas encore d'évaluation
- A Voir Cellules PhotovoltaiqueDocument174 pagesA Voir Cellules PhotovoltaiqueSaadi DibounePas encore d'évaluation
- TP Nø1 - Initiation Au Laboratoire Avec PDocument6 pagesTP Nø1 - Initiation Au Laboratoire Avec PBenglia AbderrezzakPas encore d'évaluation
- Maladies A PrionsDocument17 pagesMaladies A PrionsNTAKIRUTIMANA EZECHIELPas encore d'évaluation
- Charles Darwin et l’évolution des espèces - Des origines au post-darwinismeD'EverandCharles Darwin et l’évolution des espèces - Des origines au post-darwinismePas encore d'évaluation
- BACTERIOLOGYMED2Document167 pagesBACTERIOLOGYMED2Yo YaPas encore d'évaluation
- Champ Magnétique Créé Par Des Courants PermanentsDocument32 pagesChamp Magnétique Créé Par Des Courants PermanentsHania O. AlmdPas encore d'évaluation
- MycologieDocument84 pagesMycologieIsmail Ouskar100% (1)
- Cours Systèmes Solaires - Version 9Document145 pagesCours Systèmes Solaires - Version 9kouias hamza100% (1)
- Microscopie: Les Grands Articles d'UniversalisD'EverandMicroscopie: Les Grands Articles d'UniversalisPas encore d'évaluation
- These El Mrabet Methode Analyse Residus PesticidesDocument295 pagesThese El Mrabet Methode Analyse Residus Pesticidesnadpharm13100% (1)
- Fluide Magnétorhéologique: Le costume d'Iron Man est une œuvre de science-fiction, et il semble être un exploit d'ingénierie futuriste qui n'est pas encore possible aujourd'hui. Ou est-ce?D'EverandFluide Magnétorhéologique: Le costume d'Iron Man est une œuvre de science-fiction, et il semble être un exploit d'ingénierie futuriste qui n'est pas encore possible aujourd'hui. Ou est-ce?Pas encore d'évaluation
- Lévitation Magnétique: La physique complète du train le plus rapide jamais construitD'EverandLévitation Magnétique: La physique complète du train le plus rapide jamais construitPas encore d'évaluation
- Structure Multifonctionnelle: Les futurs systèmes de l'armée de l'air seront intégrés dans des cellules matérielles multifonctionnelles avec capteur intégré et composants de réseauD'EverandStructure Multifonctionnelle: Les futurs systèmes de l'armée de l'air seront intégrés dans des cellules matérielles multifonctionnelles avec capteur intégré et composants de réseauPas encore d'évaluation
- Polymorphisme en biologie: Les Grands Articles d'UniversalisD'EverandPolymorphisme en biologie: Les Grands Articles d'UniversalisPas encore d'évaluation
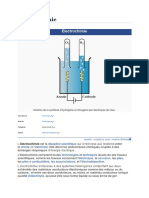
- ÉlectrochimieDocument6 pagesÉlectrochimieAmenPas encore d'évaluation
- Psim OnduleurDocument149 pagesPsim OnduleurHuong Thao Le LuongPas encore d'évaluation
- Genoun, Narimane PDFDocument55 pagesGenoun, Narimane PDFsouhilaPas encore d'évaluation
- Fermions: Les Grands Articles d'UniversalisD'EverandFermions: Les Grands Articles d'UniversalisPas encore d'évaluation
- Cours Mecanique Quantique S6 Cha 1 Partie 2 2020-21Document10 pagesCours Mecanique Quantique S6 Cha 1 Partie 2 2020-21Akabli YounesPas encore d'évaluation
- Nanomatériaux: Les nanoparticules seront capables de tuer des cellules cancéreuses individuelles, laissant les saines seulesD'EverandNanomatériaux: Les nanoparticules seront capables de tuer des cellules cancéreuses individuelles, laissant les saines seulesPas encore d'évaluation
- TP SVMDocument7 pagesTP SVMmarwaPas encore d'évaluation
- TP2 - BDA-StructPh-DD-convertiDocument7 pagesTP2 - BDA-StructPh-DD-convertimarwaPas encore d'évaluation
- Compte Rendu Tp1Document16 pagesCompte Rendu Tp1marwaPas encore d'évaluation
- Compte Rendu OracleDocument8 pagesCompte Rendu OraclemarwaPas encore d'évaluation
- InternetDesObjets 3Document22 pagesInternetDesObjets 3marwaPas encore d'évaluation
- InternetDesObjets 2Document26 pagesInternetDesObjets 2marwaPas encore d'évaluation
- InternetDesObjets 1Document17 pagesInternetDesObjets 1marwa100% (1)
- tp2 Listeadaptateurs 160826103108Document12 pagestp2 Listeadaptateurs 160826103108marwaPas encore d'évaluation
- tp2 Listeadaptateurs 160826103108Document12 pagestp2 Listeadaptateurs 160826103108marwaPas encore d'évaluation
- Statistique DescriptiveDocument23 pagesStatistique DescriptivelatinovalentPas encore d'évaluation
- ExtraitDocument9 pagesExtraithessasPas encore d'évaluation
- IR IR) (IR IR:: X, y Z X, yDocument8 pagesIR IR) (IR IR:: X, y Z X, yMimi MariemPas encore d'évaluation
- VIM - Vocabulaire International de MétrologieDocument10 pagesVIM - Vocabulaire International de MétrologieAhmed anis GasmiPas encore d'évaluation
- Serie 1 ProbaDocument2 pagesSerie 1 ProbaJasser ChtourouPas encore d'évaluation
- Tests D'hypothèses ParamétriquesDocument16 pagesTests D'hypothèses ParamétriquesSouheil BéjiPas encore d'évaluation
- 7 Loi Normale Et Théorème Central LimiteDocument35 pages7 Loi Normale Et Théorème Central LimiteLAPPPas encore d'évaluation
- Cours D'Echantillonnage Et Estimations Chapitre: La Détirmination de La Taille de L'échantillonDocument17 pagesCours D'Echantillonnage Et Estimations Chapitre: La Détirmination de La Taille de L'échantillonlagrange27 lagrange100% (1)
- 08 Ctrle 21 04 2022Document2 pages08 Ctrle 21 04 2022Kevin SAWADOGOPas encore d'évaluation
- Polycopié de Probabilités Cours Et Exercices CorrigésDocument103 pagesPolycopié de Probabilités Cours Et Exercices CorrigésAbdou AbdouPas encore d'évaluation
- Enpc Stat CoursDocument274 pagesEnpc Stat CoursJustin TalbotPas encore d'évaluation
- 1-Chap1 Intro+ Statistique Descriptive Variable Quali Et Quanti DiscretDocument53 pages1-Chap1 Intro+ Statistique Descriptive Variable Quali Et Quanti DiscretSouha Ben YoussefPas encore d'évaluation
- MAT1243 - Cours3a - Probabilité Conditionnelle Et Loi de BayesDocument33 pagesMAT1243 - Cours3a - Probabilité Conditionnelle Et Loi de BayesHalim Boutayeb100% (1)
- td3 Ue1 Ecue2 l2 Fip2 1920 Variables Aleatoires VétudiantDocument2 pagestd3 Ue1 Ecue2 l2 Fip2 1920 Variables Aleatoires VétudiantABRAHAM NENEPas encore d'évaluation
- CH1 2 3 A19Document35 pagesCH1 2 3 A19paypayPas encore d'évaluation
- Chapter 2 Proba VADDocument98 pagesChapter 2 Proba VADKhadija Es-sousyPas encore d'évaluation
- Exercices de Statistique PDFDocument4 pagesExercices de Statistique PDFlucie biholongPas encore d'évaluation
- Fascicule Exercices GesEnt 22-23Document79 pagesFascicule Exercices GesEnt 22-23Lieve EmielPas encore d'évaluation
- Proba1 1Document3 pagesProba1 1Yassine RiahiPas encore d'évaluation
- ProbaDocument40 pagesProbaAristide N 'zi NiamienPas encore d'évaluation
- Succession D'épreuves Indépendantes, Lois de Bernoulli Et Binomiale Résumé Et Révision - Mathématiques SchoolMouvDocument4 pagesSuccession D'épreuves Indépendantes, Lois de Bernoulli Et Binomiale Résumé Et Révision - Mathématiques SchoolMouvleglaude57Pas encore d'évaluation
- Variables Aleatoires DiscretesDocument16 pagesVariables Aleatoires DiscretesABDESSADEQ EL MAKKIOUIPas encore d'évaluation
- TD 3Document5 pagesTD 3Camran BktPas encore d'évaluation
- Chapitre 4Document18 pagesChapitre 4mariem mariemPas encore d'évaluation
- Test Stat RDocument54 pagesTest Stat RYAMEOGOPas encore d'évaluation
- Biostatistique Volume01Document12 pagesBiostatistique Volume01djaouad bourouaisPas encore d'évaluation
- Chapitre 2Document48 pagesChapitre 2Harold CarterPas encore d'évaluation
- ST 2 AvarDocument154 pagesST 2 AvarEmmanuel DemosthenePas encore d'évaluation
- Lecon2 - Estimation StatistiqueDocument22 pagesLecon2 - Estimation StatistiqueMamadou TouréPas encore d'évaluation
- ECONOMETRIE SujetDocument4 pagesECONOMETRIE Sujetمدرسة ضياء للرياضياتPas encore d'évaluation