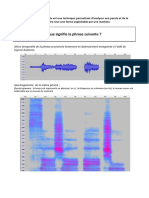
Vous aimerez peut-être aussi
- Etude Faisabilite Electricite - B513vaultDocument19 pagesEtude Faisabilite Electricite - B513vaultSandrine MOGOULA KOBEPas encore d'évaluation
- Théorie et conception des filtres analogiques, 2e édition: Avec MatlabD'EverandThéorie et conception des filtres analogiques, 2e édition: Avec MatlabPas encore d'évaluation
- Them 12Document4 pagesThem 12Hamza Jafa0% (1)
- RFC Bep Electronique PDFDocument55 pagesRFC Bep Electronique PDFOuattara EdmondPas encore d'évaluation
- ARTICLE BAMOUNI DéfinitifDocument10 pagesARTICLE BAMOUNI DéfinitifSADIA Martin ArmandPas encore d'évaluation
- Synthese Vocale DarijaDocument74 pagesSynthese Vocale DarijatarekPas encore d'évaluation
- Guide ElectriciteDocument22 pagesGuide ElectriciteTh moranPas encore d'évaluation
- Sujet AUT104Document3 pagesSujet AUT104Oussama SadkiPas encore d'évaluation
- Cours Traitement Signal P1Document59 pagesCours Traitement Signal P1NourDine Ait ZenguiPas encore d'évaluation
- La Reconnaissance Vocale Dans Son ApplicationDocument14 pagesLa Reconnaissance Vocale Dans Son ApplicationAyoubENSATPas encore d'évaluation
- Analyse Fonctionnelle Cours 3 Entreprise IndustrielleDocument3 pagesAnalyse Fonctionnelle Cours 3 Entreprise Industriellemustapha kayaPas encore d'évaluation
- CND CapteursDocument32 pagesCND CapteursKenesei GyörgyPas encore d'évaluation
- Ute - C15712-1 (2010) PDFDocument55 pagesUte - C15712-1 (2010) PDFWa FaPas encore d'évaluation
- CEM - INSA ToulouseDocument44 pagesCEM - INSA Toulouseessaitest68Pas encore d'évaluation
- Les Réseaux Locaux Industriels R.L.IDocument30 pagesLes Réseaux Locaux Industriels R.L.IFakhreddine OkailPas encore d'évaluation
- How To Read PIDDocument5 pagesHow To Read PIDfloredaPas encore d'évaluation
- Cours D'antennes Et HyperfréquencesDocument73 pagesCours D'antennes Et Hyperfréquencesvianney ITANGISHAKAPas encore d'évaluation
- Classeur Complet v27 PaysageDocument661 pagesClasseur Complet v27 PaysagejeanlucPas encore d'évaluation
- Projet Détaillée D'éclairageDocument13 pagesProjet Détaillée D'éclairageAmina GhardallouPas encore d'évaluation
- Documentation M4TDocument5 pagesDocumentation M4TSonychrist ElliotPas encore d'évaluation
- CONSIGNATIONDocument17 pagesCONSIGNATIONyde100% (1)
- Bâtiments Intelligents Et Efficacité Énergétique Plates-Formes Technologiques Et Programmes de Recherches & Développement Du CEADocument24 pagesBâtiments Intelligents Et Efficacité Énergétique Plates-Formes Technologiques Et Programmes de Recherches & Développement Du CEABenjamin Vivien KetohouPas encore d'évaluation
- Cours Sureté de FonctionnementDocument8 pagesCours Sureté de FonctionnementkbenjikaPas encore d'évaluation
- Courn3disjoncteuretf PDFDocument4 pagesCourn3disjoncteuretf PDFMohamed BenrahalPas encore d'évaluation
- Indice de Service TGBTDocument51 pagesIndice de Service TGBTIndy091Pas encore d'évaluation
- Guide Technique Parafoudres ZD234e 05 PDFDocument75 pagesGuide Technique Parafoudres ZD234e 05 PDFMohamed Sba100% (1)
- Chapitre 01Document21 pagesChapitre 01abdouPas encore d'évaluation
- Dimensionnement Basse TensionDocument77 pagesDimensionnement Basse TensionBlancouillePas encore d'évaluation
- Chap 5 Eclairage PublicDocument32 pagesChap 5 Eclairage PublicMohamed Ange NAPOPas encore d'évaluation
- EN1 SemiconducteursDocument45 pagesEN1 SemiconducteursAdel Termeche100% (1)
- Exam CemDocument24 pagesExam CemchemaliPas encore d'évaluation
- AutomatismeDocument9 pagesAutomatismeTiendrebeogo MohamadiPas encore d'évaluation
- Qualimetrie Des Réseaux ÉlectriquesDocument206 pagesQualimetrie Des Réseaux ÉlectriquesNawelPas encore d'évaluation
- TS Reconnaissance VocaleDocument7 pagesTS Reconnaissance VocaleLOULOUPas encore d'évaluation
- Fiche Technique GoullotteDocument20 pagesFiche Technique GoullotteRochdi Bouzaien100% (1)
- Oujda Qui M'habiteDocument188 pagesOujda Qui M'habiteKhalid KachaniPas encore d'évaluation
- Instruments de Mesures PDFDocument9 pagesInstruments de Mesures PDFDjilani Salmi TitoPas encore d'évaluation
- Cours Thème 2 Etude Du Projet D'éclairage Public 2023Document41 pagesCours Thème 2 Etude Du Projet D'éclairage Public 2023bryancaillot57Pas encore d'évaluation
- Cours Projet Prof-Gestion DekkicheDocument38 pagesCours Projet Prof-Gestion DekkicheAdel Amiri100% (1)
- Systemes Echantillonnés D'ordre 2Document2 pagesSystemes Echantillonnés D'ordre 2khayyamPas encore d'évaluation
- Soutenance Rapport HT 60kV NAHIDI HassanDocument43 pagesSoutenance Rapport HT 60kV NAHIDI HassanNahidiPas encore d'évaluation
- Installation, Vérification Et Maintenance AKO Tracage Électrique PDFDocument16 pagesInstallation, Vérification Et Maintenance AKO Tracage Électrique PDFdilo001Pas encore d'évaluation
- Ch2 - Lois de Snell-Descartes 07Document25 pagesCh2 - Lois de Snell-Descartes 07Hicham OutaharPas encore d'évaluation
- Installations Électriques Declairage IVDocument12 pagesInstallations Électriques Declairage IVredwanPas encore d'évaluation
- Formation Chauvin Arnoux Sur La Sécurité Electrique V3Document51 pagesFormation Chauvin Arnoux Sur La Sécurité Electrique V3Faiez GhrabPas encore d'évaluation
- tp1 Multimetres Mesures de Resistances 24 11 20181Document7 pagestp1 Multimetres Mesures de Resistances 24 11 20181Rou MeissaPas encore d'évaluation
- TP2 PDFDocument10 pagesTP2 PDFMarwa Ben ArabPas encore d'évaluation
- PyloneDocument29 pagesPyloneNidhal BousrihPas encore d'évaluation
- 000-Cours Electronique 1°A ENSMR 2019-2020Document120 pages000-Cours Electronique 1°A ENSMR 2019-2020Med Amin KhalilPas encore d'évaluation
- RAPPORT DE STAGE SEEG - Revu 19-09-23 (Final 1)Document52 pagesRAPPORT DE STAGE SEEG - Revu 19-09-23 (Final 1)Hans ENGONGAPas encore d'évaluation
- 03CE - Prises de CourantDocument7 pages03CE - Prises de CourantSou TibonPas encore d'évaluation
- Mise A La TerreDocument1 pageMise A La TerreGarba MaizoumbouPas encore d'évaluation
- Scheneider PDFDocument395 pagesScheneider PDFbillPas encore d'évaluation
- Automatismes III 2021Document82 pagesAutomatismes III 2021Hajar OumnasPas encore d'évaluation
- Large BandeDocument19 pagesLarge BandeArmando Benjamin NZO AYANGPas encore d'évaluation
- Projet C-Mixtes M2 2023Document1 pageProjet C-Mixtes M2 2023Alassane Sow100% (1)
- SimulinkDocument28 pagesSimulinkMohamed Ferhane100% (1)
- Simulation des vibrations mécaniques, 2e édition: par Matlab, Simulink et AnsysD'EverandSimulation des vibrations mécaniques, 2e édition: par Matlab, Simulink et AnsysPas encore d'évaluation
- Le Big Bang: Une Théorie Basée sur une Physique Invalide et des Mathématiques Erronées.D'EverandLe Big Bang: Une Théorie Basée sur une Physique Invalide et des Mathématiques Erronées.Pas encore d'évaluation
- Expériences et observations sur l'électricité faites à Philadelphie en AmériqueD'EverandExpériences et observations sur l'électricité faites à Philadelphie en AmériquePas encore d'évaluation
- tp4 Fraisage Avec Plateau DiviseurDocument6 pagestp4 Fraisage Avec Plateau Diviseurۥٰ ۥٰ ۥٰ ۥٰPas encore d'évaluation
- Approche TelecomDocument27 pagesApproche Telecomboulon1000Pas encore d'évaluation
- II. FONCTIONS D-WPS OfficeDocument2 pagesII. FONCTIONS D-WPS OfficeCharles Deprince AmoakonPas encore d'évaluation
- Acoustique Generale Pour L IngenieurDocument3 pagesAcoustique Generale Pour L Ingenieurnour1960Pas encore d'évaluation
- Le Probeme de Voyageur de Commerce Et La Coloration Des Sommets D'un GrapheDocument9 pagesLe Probeme de Voyageur de Commerce Et La Coloration Des Sommets D'un GrapheSamah Sam BouimaPas encore d'évaluation
- Exercices8 CorrigeDocument10 pagesExercices8 CorrigeAbdel DaaPas encore d'évaluation
- Climalit Plus Plt4sDocument1 pageClimalit Plus Plt4sPojo ForminiPas encore d'évaluation
- Gurdjieff Parle À Ses Élèves: 1917-1931 / G. I. Gurdjieff: Source Gallica - BNF.FR / Bibliothèque Nationale de FranceDocument388 pagesGurdjieff Parle À Ses Élèves: 1917-1931 / G. I. Gurdjieff: Source Gallica - BNF.FR / Bibliothèque Nationale de Francebertrand sotyPas encore d'évaluation
- Prospectus Produit Vitocell 9443587-13 FR 10-2016Document36 pagesProspectus Produit Vitocell 9443587-13 FR 10-2016MHIOUEL AnassPas encore d'évaluation
- Cours Maths Henri IVDocument75 pagesCours Maths Henri IVbouzannealexiaPas encore d'évaluation
- Cor SMP PDFDocument6 pagesCor SMP PDFataePas encore d'évaluation
- ANALYhskdjDocument8 pagesANALYhskdjpandorecedric0Pas encore d'évaluation
- Fonctions de Base D'un Départ MoteurDocument35 pagesFonctions de Base D'un Départ MoteurVerruumm Amine100% (1)
- Dalle en Béton Armé LCPCDocument83 pagesDalle en Béton Armé LCPCtotololomomo100% (1)
- Manuel Mach3frDocument67 pagesManuel Mach3frsailor21316Pas encore d'évaluation
- Mesure de La ViscositeDocument18 pagesMesure de La ViscositeSamira Mimount100% (1)
- MP Cours DYN APPDocument7 pagesMP Cours DYN APPDouas MohamedPas encore d'évaluation
- TP2 - Convection Naturelle PDFDocument51 pagesTP2 - Convection Naturelle PDFihaPas encore d'évaluation
- Tpn° 03Document6 pagesTpn° 03Amira Sai100% (1)
- Sn032a FR Eu 1 PDFDocument8 pagesSn032a FR Eu 1 PDFChamseddine MerdasPas encore d'évaluation
- Resume Cours Theorie Projet S2Document139 pagesResume Cours Theorie Projet S2Noureddine Zemmouri85% (13)
- Projet - Génie ParasismiqueDocument4 pagesProjet - Génie ParasismiqueOumayma RkiouakPas encore d'évaluation
- TD P4-5 Et 6 1ère S 12 - 13 AclimDocument4 pagesTD P4-5 Et 6 1ère S 12 - 13 Aclimawacisko734Pas encore d'évaluation
- Compo Achille PS 2020 - 2021TRIM LYMGODocument4 pagesCompo Achille PS 2020 - 2021TRIM LYMGOBariche Bondo molokiPas encore d'évaluation
- Thermocouple Table Type-JDocument3 pagesThermocouple Table Type-JAmir FauziPas encore d'évaluation
- Mef m1 STR Part - 2Document36 pagesMef m1 STR Part - 2rimah benredouanePas encore d'évaluation
- Les Phénomènes D'instabilité ÉlastiqueDocument41 pagesLes Phénomènes D'instabilité ÉlastiqueAhmed HadachPas encore d'évaluation
- Filière: PSI: Présidence Du Concours National Commun 2023Document1 pageFilière: PSI: Présidence Du Concours National Commun 2023Ouchrih OussamaPas encore d'évaluation