Vous aimerez peut-être aussi
- Classeur Guide at 2PC Biof - Info Génétique S1Document13 pagesClasseur Guide at 2PC Biof - Info Génétique S1micproteoPas encore d'évaluation
- Cour Materiel GenetiqueDocument46 pagesCour Materiel GenetiqueNaoual BenknizaPas encore d'évaluation
- SVT 2nd C - L9 - La Division CellulaireDocument13 pagesSVT 2nd C - L9 - La Division CellulaireTouré Kiyofo HabibPas encore d'évaluation
- Le Cycle Cellulaire Mon Cours PolycopeDocument26 pagesLe Cycle Cellulaire Mon Cours PolycopemohamedPas encore d'évaluation
- Résultat 2Document15 pagesRésultat 2Nour EddinePas encore d'évaluation
- Présentation 1Document10 pagesPrésentation 1Bannour SaraPas encore d'évaluation
- Chap 4Document14 pagesChap 4dk2524044Pas encore d'évaluation
- Notion de L Information Genetique Cours 1 PDFDocument15 pagesNotion de L Information Genetique Cours 1 PDFpdfPas encore d'évaluation
- Cours No 04-Le NoyauDocument15 pagesCours No 04-Le NoyauFeriel Feriel100% (1)
- Chapitre 03 Le Cycle CellulaireDocument10 pagesChapitre 03 Le Cycle CellulaireĐî ŅæPas encore d'évaluation
- Structure Du Noyau. La Division CellulaireDocument6 pagesStructure Du Noyau. La Division CellulaireAziz ChaiebPas encore d'évaluation
- La Division CellulaireDocument30 pagesLa Division Cellulaireselma torresPas encore d'évaluation
- Genetique Fondamentale - Mitose Et Meiose - MoodleDocument12 pagesGenetique Fondamentale - Mitose Et Meiose - MoodleJacob TOGLOPas encore d'évaluation
- Cycle Cellulaire Et Cellule Cancéreuse 2016 PDFDocument4 pagesCycle Cellulaire Et Cellule Cancéreuse 2016 PDFAnonymous wVr908lBcKPas encore d'évaluation
- Les Mitoses Et MéiosesDocument6 pagesLes Mitoses Et MéiosesTiaret TiaretPas encore d'évaluation
- MITOSEDocument6 pagesMITOSELarbi SalihPas encore d'évaluation
- COURS INFORMATION GENETIQUE - SuiteDocument9 pagesCOURS INFORMATION GENETIQUE - SuiteMohamed MoustakimPas encore d'évaluation
- ExtraitspeSVT1ere PDFDocument9 pagesExtraitspeSVT1ere PDFSafa OJEILPas encore d'évaluation
- Chapitre 4 + 5 Cycle Cellulaire Et Noyau InterphasiqueDocument15 pagesChapitre 4 + 5 Cycle Cellulaire Et Noyau InterphasiqueOuissem Belkhous100% (1)
- Les Étapes de La MitoseDocument5 pagesLes Étapes de La MitoseZakaria OuissaPas encore d'évaluation
- Biologie Cellulaire IIIDocument12 pagesBiologie Cellulaire IIIInas HassanatPas encore d'évaluation
- La Notion de L'information Génétique - KezakooDocument24 pagesLa Notion de L'information Génétique - KezakooAymene masbahPas encore d'évaluation
- Inform Génétique Part 1Document95 pagesInform Génétique Part 1Ferssiwi OmarPas encore d'évaluation
- Chap2 - Cours Physiologie Cellulaire Ufr Stapv - Ussein 2Document60 pagesChap2 - Cours Physiologie Cellulaire Ufr Stapv - Ussein 2sowcapo2004Pas encore d'évaluation
- Chapitre 1 EleveDocument4 pagesChapitre 1 EleveMathis LefrancPas encore d'évaluation
- Chapitre 1 EleveDocument4 pagesChapitre 1 EleveMathis LefrancPas encore d'évaluation
- Unité 2 RresDocument11 pagesUnité 2 Rresfdell azerPas encore d'évaluation
- Chapitre Ii Cycles de VieDocument5 pagesChapitre Ii Cycles de Vieevident 2014Pas encore d'évaluation
- 3 - Division CellulaireDocument5 pages3 - Division CellulaireWi SsalPas encore d'évaluation
- SVT Chapitre 1Document4 pagesSVT Chapitre 1scoccimarro.sarahPas encore d'évaluation
- La CelluleDocument52 pagesLa Cellulesimo.elhaouate.1000Pas encore d'évaluation
- La Division Cellulaire Mitose Et Méiose: Institut National de Formation Paramédicale BatnaDocument11 pagesLa Division Cellulaire Mitose Et Méiose: Institut National de Formation Paramédicale BatnaDelenda ChamchoumaPas encore d'évaluation
- Les Divisions Cellulaires - SVT 1èreDocument4 pagesLes Divisions Cellulaires - SVT 1èreSong GabiPas encore d'évaluation
- Notion de Linfo Géné Et Sonex SHDocument14 pagesNotion de Linfo Géné Et Sonex SHhajar hajoraPas encore d'évaluation
- CytogénétiqueDocument33 pagesCytogénétiqueFaiza HPas encore d'évaluation
- Cours de Biologie Générale Chapitres 3 À 5 Pour 2022Document93 pagesCours de Biologie Générale Chapitres 3 À 5 Pour 2022jeffkakwanda10Pas encore d'évaluation
- Cours 3 Le Cycle Cellulaire PDFDocument17 pagesCours 3 Le Cycle Cellulaire PDFmalak kerakbiPas encore d'évaluation
- Section 3Document19 pagesSection 3soumia benyahiaPas encore d'évaluation
- La Division Celllulaire Des EucaryotesDocument8 pagesLa Division Celllulaire Des EucaryoteselassadPas encore d'évaluation
- La Nature de L'information GenetiqueDocument6 pagesLa Nature de L'information Genetiqueyassirfaddali2008Pas encore d'évaluation
- Le Cycle CellulaireDocument16 pagesLe Cycle CellulaireyoussefPas encore d'évaluation
- Chapitre II - Le Cycle CellulaireDocument6 pagesChapitre II - Le Cycle CellulaireMouna DocPas encore d'évaluation
- La MitoseDocument4 pagesLa MitoseFDGPas encore d'évaluation
- BDR - FICHE - Cours 1 Mitose Et MéioseDocument15 pagesBDR - FICHE - Cours 1 Mitose Et Méiosesurgeon forgeronPas encore d'évaluation
- Cycle CellulaireDocument37 pagesCycle CellulairegigiPas encore d'évaluation
- Al7sn12tepa0111 Sequence 03Document46 pagesAl7sn12tepa0111 Sequence 03ogmios_940% (1)
- CytogénétiqueDocument17 pagesCytogénétiqueSabrina BehlouliPas encore d'évaluation
- Cours Etudiants V2 2016Document44 pagesCours Etudiants V2 2016Zaidou RoambaPas encore d'évaluation
- MITOSE MEIOSE InfoDocument7 pagesMITOSE MEIOSE InfoAHMED DiopPas encore d'évaluation
- TD N1 Le Cycle CellulaireDocument6 pagesTD N1 Le Cycle Cellulairemaysoun100% (1)
- La MitoseDocument3 pagesLa MitoseVictorin FANDREBOPas encore d'évaluation
- Activité Le Cycle CellulaireDocument3 pagesActivité Le Cycle CellulaireYassine RiahiPas encore d'évaluation
- 02 - Gamétogenèse GDocument50 pages02 - Gamétogenèse GIslęm OuaribPas encore d'évaluation
- FICHE 1 Cycle CellulaireDocument6 pagesFICHE 1 Cycle CellulaireAnissa BoumaaroufPas encore d'évaluation
- MitoseDocument10 pagesMitoseOumarou KontaPas encore d'évaluation
- Cours IV Réplication d'ADN Et Cycle Cellulaire 221115 202921Document6 pagesCours IV Réplication d'ADN Et Cycle Cellulaire 221115 202921Nouha HadjPas encore d'évaluation
- Cours TD. Les Chromosomes Et Les Divisions CellulairesDocument7 pagesCours TD. Les Chromosomes Et Les Divisions CellulairesMbaye DiakhoumpaPas encore d'évaluation
- 1 - Bases Physiques de L'héréditéDocument6 pages1 - Bases Physiques de L'héréditémariahaddad442Pas encore d'évaluation
- IGDocument37 pagesIGalbanna mourakouchiPas encore d'évaluation
- Membranes cellulaires: Les Grands Articles d'UniversalisD'EverandMembranes cellulaires: Les Grands Articles d'UniversalisPas encore d'évaluation
- 1BACL - S1 - v2Document31 pages1BACL - S1 - v2Hamza AmjahdiPas encore d'évaluation
- Exercices BiomètrieDocument6 pagesExercices BiomètrieHamza AmjahdiPas encore d'évaluation
- La Planche 1Document2 pagesLa Planche 1Hamza AmjahdiPas encore d'évaluation
- Examen National SVT Sciences Maths A 2019 Rattrapage SujetDocument6 pagesExamen National SVT Sciences Maths A 2019 Rattrapage SujetŤăhã ÊìîPas encore d'évaluation
- Dpt06 Lazaret DP Evolution HommeDocument41 pagesDpt06 Lazaret DP Evolution HommeVasile Cotiuga100% (1)
- Meose Et MitoseDocument9 pagesMeose Et Mitoseone asslanPas encore d'évaluation
- Corrige Devoir 5 28Document4 pagesCorrige Devoir 5 28niyomo7937Pas encore d'évaluation
- TD Adressage L1SV 2021Document5 pagesTD Adressage L1SV 2021kirito 83Pas encore d'évaluation
- Theme 3 Chapitre 1 Evaluation 1a CorrectionDocument1 pageTheme 3 Chapitre 1 Evaluation 1a Correctionflorie.achatPas encore d'évaluation
- Tp1 Ba GametogeneseDocument15 pagesTp1 Ba GametogeneseNadine AbidPas encore d'évaluation
- UAA 8 - chp2 - Prolongements - Mendel - 2020 - Partie2Document8 pagesUAA 8 - chp2 - Prolongements - Mendel - 2020 - Partie2céline prielsPas encore d'évaluation
- Algo GenetiqueDocument72 pagesAlgo GenetiqueNOUHAYLA MAJDOUBI100% (1)
- Quiz Génétique PDFDocument6 pagesQuiz Génétique PDFArno sawaPas encore d'évaluation
- Classification Bactérienne N-MidounDocument32 pagesClassification Bactérienne N-MidounBibi Daniels100% (1)
- Épigénétique Et Memoire CellulaireDocument10 pagesÉpigénétique Et Memoire CellulaireAndreea SchiauPas encore d'évaluation
- ChondriomeDocument25 pagesChondriomeYlinka SamiraPas encore d'évaluation
- COURS 6 MutationsDocument89 pagesCOURS 6 MutationsHikari KazuePas encore d'évaluation
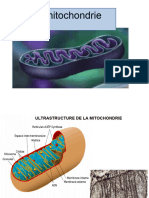
- Cyto1an Mitochondrie2022aouatiDocument12 pagesCyto1an Mitochondrie2022aouatiAy ManPas encore d'évaluation
- Base de ComparaisonDocument2 pagesBase de Comparaisonarij alouiPas encore d'évaluation
- Test 1 - 1BAC 2023-2024Document4 pagesTest 1 - 1BAC 2023-2024noureddinemsylyaPas encore d'évaluation
- Emb Protozoaires PDFDocument10 pagesEmb Protozoaires PDFRacem Boudghene stambouliPas encore d'évaluation
- N.des - Plantes 1Document101 pagesN.des - Plantes 1han1954abPas encore d'évaluation
- Exercice Mini 2 Acquisition de Protéines Antigel Chez Les TéléostéensvfDocument2 pagesExercice Mini 2 Acquisition de Protéines Antigel Chez Les TéléostéensvfMolka MiladiPas encore d'évaluation
- Lois Statistiaues 2Document23 pagesLois Statistiaues 2Arm FullPas encore d'évaluation
- MutagenèseDocument5 pagesMutagenèsevague2000Pas encore d'évaluation
- Stock LesPdf Examens BAC Comores Corr 2014 Comores Corr D Science (SVT) Bac 2014Document2 pagesStock LesPdf Examens BAC Comores Corr 2014 Comores Corr D Science (SVT) Bac 2014AhmedPas encore d'évaluation
- Programme SFMPP 2023 13.09Document20 pagesProgramme SFMPP 2023 13.09martin.dubuc-extPas encore d'évaluation
- Réquisitoire Contre Les OGM ECRITDocument2 pagesRéquisitoire Contre Les OGM ECRITvvvPas encore d'évaluation
- 3810-Texte de L'article-29189-1-10-20200622 PDFDocument9 pages3810-Texte de L'article-29189-1-10-20200622 PDFDoumbia souleymanePas encore d'évaluation
- PosterDocument5 pagesPosterBrahim OuarhlentPas encore d'évaluation
- Tabet Ricardos 2013 Ed414Document251 pagesTabet Ricardos 2013 Ed414Maaz NasimPas encore d'évaluation
- 08 Cours Exo Niveau 1erecDocument30 pages08 Cours Exo Niveau 1erecAlpha madiou BahPas encore d'évaluation
- Chapitre 3 - GermDocument44 pagesChapitre 3 - GermMINDANOU SHEIKH ALIOU DJAGNEPas encore d'évaluation
- Le Principe de Lucifer Tome 2Document125 pagesLe Principe de Lucifer Tome 2fabrePas encore d'évaluation