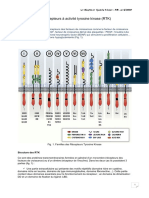
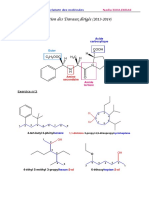
Vous aimerez peut-être aussi
- Biochimie PDFDocument132 pagesBiochimie PDFAmanda Laleye58% (19)
- Liste Des Produits PharmaceutiquesDocument78 pagesListe Des Produits Pharmaceutiqueshakimehakime100% (1)
- Appretement Et Presentation de L'agDocument41 pagesAppretement Et Presentation de L'agAnonymous FGGLsjzWi100% (2)
- Filiere Viande RougeDocument1 pageFiliere Viande RougeIlyasse Ait HaddouPas encore d'évaluation
- Chapitre I Généralités Sur Le Lait en Cours de FinalisationDocument15 pagesChapitre I Généralités Sur Le Lait en Cours de FinalisationAicha's PenPas encore d'évaluation
- Biostatistiques. SakraniDocument77 pagesBiostatistiques. Sakraniamina aminaPas encore d'évaluation
- Dynamique Du Systeme AlimentaireDocument9 pagesDynamique Du Systeme AlimentaireCristina EniPas encore d'évaluation
- Les Biotechnologies RougesDocument6 pagesLes Biotechnologies RougesYohann LecroartPas encore d'évaluation
- L'allergieDocument11 pagesL'allergieAbbassiPas encore d'évaluation
- 01b-La Normalisation en AlgérieDocument15 pages01b-La Normalisation en AlgérieLydia HAMCHAOUIPas encore d'évaluation
- These217 19Document194 pagesThese217 19GlâdyâŤór GírLPas encore d'évaluation
- Abattoire Oujda PDFDocument21 pagesAbattoire Oujda PDFSimo CharafPas encore d'évaluation
- Récepteur de La Superfamille TNF AlphaDocument28 pagesRécepteur de La Superfamille TNF AlphaFatima ZahraPas encore d'évaluation
- AN-t046Document9 pagesAN-t046oussama22Pas encore d'évaluation
- Universite Mohammed V - Rabat Faculte de Medecine Et de PharmacieDocument187 pagesUniversite Mohammed V - Rabat Faculte de Medecine Et de PharmacieDelondon AlasckoPas encore d'évaluation
- Chapitre 4. BiocapteursDocument13 pagesChapitre 4. BiocapteursFatimazahra ElmPas encore d'évaluation
- ISO22KDocument44 pagesISO22KAbderrazzak ElazriPas encore d'évaluation
- TP PhysiooDocument40 pagesTP Physiookenny100% (1)
- Support Du Cours Microbiologie de L'environnementDocument23 pagesSupport Du Cours Microbiologie de L'environnementGhanou NeddjarPas encore d'évaluation
- Les Normes de Qualité Au Maroc Et Dans Le MondeDocument2 pagesLes Normes de Qualité Au Maroc Et Dans Le MondeAnass BounajraPas encore d'évaluation
- Étude de La Phytochimie Et Activités Biologique...Document100 pagesÉtude de La Phytochimie Et Activités Biologique...Polo CXPas encore d'évaluation
- Autorisation FRADocument6 pagesAutorisation FRANadia GoudaPas encore d'évaluation
- Avis de Concours OnssaDocument20 pagesAvis de Concours OnssaSoufiane NaniPas encore d'évaluation
- Sémio Med - Sémiologie EndocrinienneDocument3 pagesSémio Med - Sémiologie EndocrinienneRamzi Ch100% (1)
- Les Endotoxines 1-1Document16 pagesLes Endotoxines 1-1Mo À l'EuropePas encore d'évaluation
- Cours de Biochimie MétaboliqueDocument108 pagesCours de Biochimie MétaboliqueMBAÏADOUM NGARGUINAM Rodrigue100% (1)
- Waaub Diapo 2Document120 pagesWaaub Diapo 2Ilham TimadjerPas encore d'évaluation
- Récepteurs À Activité Tyrosine Kinase DefDocument12 pagesRécepteurs À Activité Tyrosine Kinase DefFatima ZahraPas encore d'évaluation
- SalmonellaDocument47 pagesSalmonellaTarik DamirPas encore d'évaluation
- Presentation SQ ONISPADocument20 pagesPresentation SQ ONISPAqualite consultingPas encore d'évaluation
- Candida Et Candidoses ResuméDocument4 pagesCandida Et Candidoses Resumékaka lotyPas encore d'évaluation
- Les Lipides Version FinalenomarksDocument4 pagesLes Lipides Version Finalenomarksapi-243718294100% (1)
- Cours Génie Industriel AlimentaireDocument91 pagesCours Génie Industriel AlimentaireElbahi DjaalabPas encore d'évaluation
- Codex Alimentaire 2 PDFDocument203 pagesCodex Alimentaire 2 PDFAsma TransformationPas encore d'évaluation
- Le Cours de BiostatistiquesDocument16 pagesLe Cours de BiostatistiquesCHAIMAE AFIFPas encore d'évaluation
- Mémoire Mehdi11Document60 pagesMémoire Mehdi11ikramPas encore d'évaluation
- Classification EntrepriseDocument12 pagesClassification EntrepriseKodak drakePas encore d'évaluation
- Les Boissons Light': Conservation Et Effet Sur L'équilibre Du DiabèteDocument108 pagesLes Boissons Light': Conservation Et Effet Sur L'équilibre Du DiabètePatrick ConradPas encore d'évaluation
- Une Politique Écologique Ambitieuse de Lutte Contre Le Plastique. La Logique Environnementale Et Sociale Du Recours Aux Consignes Pour RéemploiDocument12 pagesUne Politique Écologique Ambitieuse de Lutte Contre Le Plastique. La Logique Environnementale Et Sociale Du Recours Aux Consignes Pour RéemploiFondationEcoloPas encore d'évaluation
- Bioch1an16-Enzymologie GhoualiDocument67 pagesBioch1an16-Enzymologie Ghoualiahlemm100% (1)
- Biostatistique. Université Frères Mentouri Constantine 3.3. Mr. LATELI Ahcene. L 2.Sc - BiologiquesDocument15 pagesBiostatistique. Université Frères Mentouri Constantine 3.3. Mr. LATELI Ahcene. L 2.Sc - BiologiquesdidinePas encore d'évaluation
- Procédure StérilisationDocument7 pagesProcédure StérilisationMarchePas encore d'évaluation
- Partie Ii Biotechnologie Microbienne Chap ADocument6 pagesPartie Ii Biotechnologie Microbienne Chap AAmira AmouraPas encore d'évaluation
- Evaluation Des Bonnes Pratiques D'hygiène Au Sein D'une Cuisine Centrale D'un Hôpital À Fès - Soukaina OUKADDOUDocument44 pagesEvaluation Des Bonnes Pratiques D'hygiène Au Sein D'une Cuisine Centrale D'un Hôpital À Fès - Soukaina OUKADDOUKawtar erramiPas encore d'évaluation
- Contribution Au Maintien de La Certification ISO 22 000 - 2018 - Djiby THIAMDocument72 pagesContribution Au Maintien de La Certification ISO 22 000 - 2018 - Djiby THIAMYounas AbaliPas encore d'évaluation
- Labarere Jose p01 PDFDocument77 pagesLabarere Jose p01 PDFhubik38Pas encore d'évaluation
- Chapitre 1 Généralités Sur Les Risquesalimentaires PDFDocument6 pagesChapitre 1 Généralités Sur Les Risquesalimentaires PDFAsma MenaiPas encore d'évaluation
- Fruits Et LegumesDocument7 pagesFruits Et Legumesdidi100% (1)
- Contribution À La Valorasation Des Déchets en Algérie-Ilovepdf-CompressedDocument54 pagesContribution À La Valorasation Des Déchets en Algérie-Ilovepdf-Compressedsection automatePas encore d'évaluation
- Industries Agro-AlimentairesDocument733 pagesIndustries Agro-AlimentairesAzzoug BilalPas encore d'évaluation
- 1-Anti-Inflammatoires Stéroïdiens - AIS.2020Document80 pages1-Anti-Inflammatoires Stéroïdiens - AIS.2020khouloud gazzehPas encore d'évaluation
- Méthode D'étude de La CelluleDocument33 pagesMéthode D'étude de La CelluleliliPas encore d'évaluation
- Space: Go Green Community Presentation TemplateDocument13 pagesSpace: Go Green Community Presentation TemplateKhawlaPas encore d'évaluation
- Cours Khelfaoui Recherche Documentaire Et Conception de M閙oireDocument23 pagesCours Khelfaoui Recherche Documentaire Et Conception de M閙oiresosso poissonPas encore d'évaluation
- LeadershipDocument5 pagesLeadershipjackPas encore d'évaluation
- Labarere Jose p02Document26 pagesLabarere Jose p02youness.khalfaouiPas encore d'évaluation
- G1-Aliments Riches en GlucidesDocument25 pagesG1-Aliments Riches en GlucidesRachid DjigaPas encore d'évaluation
- Chapitre Fermentations Industrielles PDFDocument17 pagesChapitre Fermentations Industrielles PDFАпцгдк Ьфш БгднчллPas encore d'évaluation
- Biotechnologie Et Molecules DinteretsDocument31 pagesBiotechnologie Et Molecules DinteretsAmal BouDechichaPas encore d'évaluation
- Directives pour l'élaboration d'une stratégie nationale pour les ressources phytogénétiques pour l'alimentation et l'agricultureD'EverandDirectives pour l'élaboration d'une stratégie nationale pour les ressources phytogénétiques pour l'alimentation et l'agriculturePas encore d'évaluation
- TableDocument6 pagesTabletomPas encore d'évaluation
- TD Génie GénétiqueDocument4 pagesTD Génie GénétiqueMeryem ELkhalloufy100% (1)
- TS Fiche Révision Génétique Et ÉvolutionDocument5 pagesTS Fiche Révision Génétique Et ÉvolutionCarole Chamoun EbPas encore d'évaluation
- Rush 00Document12 pagesRush 00kettuflyPas encore d'évaluation
- Etude de La Répartition Des Séquences AluDocument21 pagesEtude de La Répartition Des Séquences AluVonHammerPas encore d'évaluation
- Les PlasmidesDocument7 pagesLes PlasmidesDjerboua Taoufik100% (1)
- La Levure BiologiqueDocument5 pagesLa Levure BiologiquePawan CoomarPas encore d'évaluation
- Bioremédiation PDFDocument31 pagesBioremédiation PDFmekaekPas encore d'évaluation
- 2006CLF21636 PDFDocument318 pages2006CLF21636 PDFRoxana AtomeiPas encore d'évaluation
- N6431972 PDF 1 - 1DM PDFDocument244 pagesN6431972 PDF 1 - 1DM PDFanon_736742916Pas encore d'évaluation
- Valorisation Des DattesDocument171 pagesValorisation Des DattesجعدبندرهمPas encore d'évaluation
- TS SVT Oblig Fiche Vocabulaire Partie 2Document4 pagesTS SVT Oblig Fiche Vocabulaire Partie 2tnerolf35Pas encore d'évaluation
- Cours 4 Génie GénétiqueDocument26 pagesCours 4 Génie GénétiqueAy IşığıPas encore d'évaluation
- Cours Transcription S5Document46 pagesCours Transcription S5ونزار عبد القادرPas encore d'évaluation
- Ch1.1 La Mitose Cours PolyDocument2 pagesCh1.1 La Mitose Cours PolydadaPas encore d'évaluation
- Série N°3Document3 pagesSérie N°3lmd2009Pas encore d'évaluation
- Procaryotes Et EucaryotesDocument30 pagesProcaryotes Et EucaryotesHamza SerPas encore d'évaluation
- Nom Anm OtcDocument122 pagesNom Anm OtcCristina RusnacPas encore d'évaluation
- Rdii 31182Document2 pagesRdii 31182Mohammed TourarPas encore d'évaluation
- Rouaissi Hajlaoui Mic. Hyg. Alim.08Document7 pagesRouaissi Hajlaoui Mic. Hyg. Alim.08hindPas encore d'évaluation
- Chapitre II Etude de La Structure Des BactériesDocument10 pagesChapitre II Etude de La Structure Des BactériesAnthony MaryPas encore d'évaluation
- Cours1 IntroductionDocument7 pagesCours1 IntroductionNibelMiaPas encore d'évaluation
- TD Nomenclature Corrige 6Document2 pagesTD Nomenclature Corrige 6Aaouine AbderrazzakPas encore d'évaluation
- ReplicDocument12 pagesReplicKhalil BilalPas encore d'évaluation
- SVTDocument6 pagesSVTHala AbdeldayemPas encore d'évaluation
- TD2 Genetique 2007Document5 pagesTD2 Genetique 2007Cia Mato75% (4)
- Chapitre 2 La RéplicationDocument18 pagesChapitre 2 La RéplicationHamza Ali100% (1)