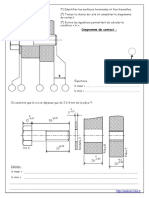
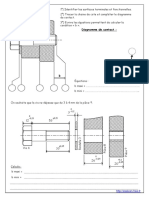
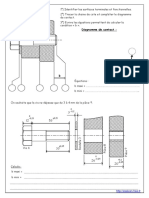
Vous aimerez peut-être aussi
- Midi Plein Introduction A La Pensee Maconnique PDF PreviewDocument38 pagesMidi Plein Introduction A La Pensee Maconnique PDF PreviewMompoint HenockPas encore d'évaluation
- TD1 Econométrie Corr-3Document7 pagesTD1 Econométrie Corr-3MedxBusrru100% (3)
- Tele 7 Jeux - Octobre 2018 PDFDocument100 pagesTele 7 Jeux - Octobre 2018 PDFfanny de los angeles martinez caleroPas encore d'évaluation
- BTS 2023 Mathématiques Groupe B1Document6 pagesBTS 2023 Mathématiques Groupe B1LETUDIANTPas encore d'évaluation
- Serie Exercices Cotation Fonctionnelle PDFDocument7 pagesSerie Exercices Cotation Fonctionnelle PDFMohamed Naciri80% (20)
- ApicultureDocument50 pagesApicultureassonwa thierryPas encore d'évaluation
- Boite de Vitesses Robotisee Sensodrive de c3Document5 pagesBoite de Vitesses Robotisee Sensodrive de c3aymendabPas encore d'évaluation
- Eurocode 2Document5 pagesEurocode 2Sylvain AbissiPas encore d'évaluation
- Chap1 TorseursDocument38 pagesChap1 TorseursChafik Abid100% (1)
- Guide GESIP 2008 01 EDD - Rev 2019 - Version Du 19 Juillet 2019 BSERRDocument118 pagesGuide GESIP 2008 01 EDD - Rev 2019 - Version Du 19 Juillet 2019 BSERRKais Messaoudi100% (1)
- Construire Un Projet de Recherche en Sciences Humaines Et Sociales - Une Procédure de Mise en Lien (Grinschpoun, Marie-France (Grinschpoun Etc.) (Z-Library)Document60 pagesConstruire Un Projet de Recherche en Sciences Humaines Et Sociales - Une Procédure de Mise en Lien (Grinschpoun, Marie-France (Grinschpoun Etc.) (Z-Library)Dieudonné Faraja Chris MkangyaPas encore d'évaluation
- Notice de Montage Et de Réglage ATV 3 SHDocument34 pagesNotice de Montage Et de Réglage ATV 3 SHAlexandre ThorelPas encore d'évaluation
- Géostat Exercices+CorrigéDocument9 pagesGéostat Exercices+CorrigéHocine90% (10)
- Analyse ABCDocument6 pagesAnalyse ABCJean-Michel Zaragoza100% (1)
- Corrigé Exam Jan Econometrie 2020Document6 pagesCorrigé Exam Jan Econometrie 2020Cyrine Krid100% (1)
- Plan Marketing StratégiqueDocument276 pagesPlan Marketing StratégiqueR100% (1)
- Chap02 - Modèle Géométrique Direct PDFDocument19 pagesChap02 - Modèle Géométrique Direct PDFBadr Kaakoua100% (2)
- Cours EN310 Communication Numérique AvancéeDocument141 pagesCours EN310 Communication Numérique AvancéeAbdallah Toolmaker100% (3)
- Serie Exercices Cotation Fonctionnelle UnlockedDocument7 pagesSerie Exercices Cotation Fonctionnelle UnlockedKarim MellahPas encore d'évaluation
- Mini Projet m2 Hu (Assainissementii) 2021Document5 pagesMini Projet m2 Hu (Assainissementii) 2021Amel HydPas encore d'évaluation
- Compte Rendu Final Hassen1 SommaireDocument19 pagesCompte Rendu Final Hassen1 SommaireAdel ZitouniPas encore d'évaluation
- correctionTD2 Commande Des Robots ISSATDocument2 pagescorrectionTD2 Commande Des Robots ISSATmed chemkhiPas encore d'évaluation
- Anciens CP2Document88 pagesAnciens CP2chaymaa MRHARPas encore d'évaluation
- CDC ExercicesDocument7 pagesCDC ExercicesRamdane BoulahiaPas encore d'évaluation
- CDC Exercices PDFDocument7 pagesCDC Exercices PDFMohamedBejjaPas encore d'évaluation
- Chapitre 2 Statistiques Et ProbabilitésDocument14 pagesChapitre 2 Statistiques Et Probabilitésdhia trabelsiPas encore d'évaluation
- DS Salc2019Document3 pagesDS Salc2019Abir HammamiPas encore d'évaluation
- Exam 2013 FlattenDocument15 pagesExam 2013 FlattenFranck BitaPas encore d'évaluation
- Serie 2 Geometrie Des Sections ConvertiDocument1 pageSerie 2 Geometrie Des Sections Convertifz bfsPas encore d'évaluation
- TP1 RosalieBerthelot IngaBasanzeDocument13 pagesTP1 RosalieBerthelot IngaBasanzeRosalie BerthelotPas encore d'évaluation
- TP6 - VariogrammeVarianceBlocDocument9 pagesTP6 - VariogrammeVarianceBlocarachidPas encore d'évaluation
- Correction EMD Systems Meca Arti Robotique 2021 BOUTAANIDocument4 pagesCorrection EMD Systems Meca Arti Robotique 2021 BOUTAANIDodine AzePas encore d'évaluation
- Serie 3Document1 pageSerie 3e-k.boudjlidaPas encore d'évaluation
- PARTIEIIDocument38 pagesPARTIEIIKodjo Gabin DEGUENONPas encore d'évaluation
- ssp240 f2Document40 pagesssp240 f2arococoPas encore d'évaluation
- Série 4 Statistique DescriptiveDocument3 pagesSérie 4 Statistique DescriptiveFatimaezahra KoudiaPas encore d'évaluation
- Exercices Sur Les VariogrammesDocument6 pagesExercices Sur Les VariogrammesPascal Robine-sonPas encore d'évaluation
- Parties 03 Et 04Document7 pagesParties 03 Et 04Mehdi JANNATPas encore d'évaluation
- DS Hydraulique 2023Document2 pagesDS Hydraulique 2023montaserjawadiPas encore d'évaluation
- TD1 A.d-Mea 2022-23Document4 pagesTD1 A.d-Mea 2022-23dihiwe3391Pas encore d'évaluation
- Chapitre IIDocument20 pagesChapitre IIYann ElhamPas encore d'évaluation
- Baud Tirpart PRESSIO2005Document13 pagesBaud Tirpart PRESSIO2005MatdzPas encore d'évaluation
- ACP2Document8 pagesACP2marwaPas encore d'évaluation
- HA0808 Corrige PDFDocument4 pagesHA0808 Corrige PDFAbd El Alim DahmaniPas encore d'évaluation
- Hvac IiiDocument10 pagesHvac IiiMichaël Paradjian100% (1)
- Systeme Bielle Manivelle PDFDocument2 pagesSysteme Bielle Manivelle PDFdidoPas encore d'évaluation
- TSGMI-M12-16-S-pareto EX 01-02 - 085319Document4 pagesTSGMI-M12-16-S-pareto EX 01-02 - 085319WalidPas encore d'évaluation
- Examen - MAS94 - 2021Document2 pagesExamen - MAS94 - 2021Abd el moumen HemiciPas encore d'évaluation
- 25 - Isp5-Pp-167-174-Baud - 377 (Essai Pressiometrique)Document8 pages25 - Isp5-Pp-167-174-Baud - 377 (Essai Pressiometrique)BENARAB Fayçal100% (1)
- Rige 01 emDocument9 pagesRige 01 emEL MOUNTASAR BILLAH SOLTANEPas encore d'évaluation
- Tp4 Cours 1 Traore Kalifa-1Document20 pagesTp4 Cours 1 Traore Kalifa-1senateur kalifPas encore d'évaluation
- Agriwork Europa D Tabella Di Semina PDFDocument10 pagesAgriwork Europa D Tabella Di Semina PDFPaval PetrutPas encore d'évaluation
- 3 - Cours Bisostat - M1 - ENSAF - Chapitre 3Document120 pages3 - Cours Bisostat - M1 - ENSAF - Chapitre 3Gervais MbahoukaPas encore d'évaluation
- Sujet 7Document5 pagesSujet 7badr hadriPas encore d'évaluation
- TD Traitement Du SignalDocument3 pagesTD Traitement Du SignalBenabdi YousraPas encore d'évaluation
- TP - Matlab - 02 (3) Adel YousfiDocument14 pagesTP - Matlab - 02 (3) Adel YousfiadelPas encore d'évaluation
- Pertes de Charge Hydraulique-CosticDocument6 pagesPertes de Charge Hydraulique-CosticcheefengerPas encore d'évaluation
- Exercices Stat - Fazouane 2017-2019Document6 pagesExercices Stat - Fazouane 2017-2019taoufiq ELHAJBI100% (1)
- Série 3Document3 pagesSérie 3Sidi DahPas encore d'évaluation
- Longrines L1: L1-1 Section 20x30: A-A B-BDocument3 pagesLongrines L1: L1-1 Section 20x30: A-A B-BJutole MoukokoPas encore d'évaluation
- Exam Robotique AITLAHCENDocument5 pagesExam Robotique AITLAHCENCaptain Teddy BearPas encore d'évaluation
- C1 Activité+Des+StationsDocument6 pagesC1 Activité+Des+StationsamaryllisdelislePas encore d'évaluation
- BouzitetAmeur CFM2009Document7 pagesBouzitetAmeur CFM2009Inass ELHAOUARIPas encore d'évaluation
- Dé Nir L'automatiqueDocument2 pagesDé Nir L'automatiqueNidhal CherratPas encore d'évaluation
- Exercices Variogramme 2e-SerieDocument8 pagesExercices Variogramme 2e-SerieBensalma YanisPas encore d'évaluation
- 1SPE DeriveeDocument2 pages1SPE DeriveeHervé IcardPas encore d'évaluation
- Poly SD13Document62 pagesPoly SD13Raja MokniPas encore d'évaluation
- 2009 09 Polynesie Exo1 Correction Moto 6ptsDocument3 pages2009 09 Polynesie Exo1 Correction Moto 6ptshichammouffakPas encore d'évaluation
- Https:/helios2.Mi - Parisdescartes.fr/ Vperduca/cours/programmation/R2 SDocument25 pagesHttps:/helios2.Mi - Parisdescartes.fr/ Vperduca/cours/programmation/R2 SEsseba MarthePas encore d'évaluation
- TP5 CorrectionDocument15 pagesTP5 CorrectionJustine RousseauxPas encore d'évaluation
- Tableau Des Grandeurs PhysiquesDocument1 pageTableau Des Grandeurs PhysiquesJustine RousseauxPas encore d'évaluation
- AnglaisDocument2 pagesAnglaisJustine RousseauxPas encore d'évaluation
- Synthèse Formation Scientifique 3PcfDocument6 pagesSynthèse Formation Scientifique 3PcfJustine RousseauxPas encore d'évaluation
- 03 Trace Et Normes GeometriquesDocument81 pages03 Trace Et Normes GeometriquesIlhem Arfaoui100% (1)
- TS Cours SuitesDocument10 pagesTS Cours SuitesGerardo GeusaPas encore d'évaluation
- 2-Electrophysiologie CardiaqueDocument8 pages2-Electrophysiologie CardiaqueImene BenzianePas encore d'évaluation
- Astre HowTo Full PDFDocument41 pagesAstre HowTo Full PDFvroussel.cerpicardiePas encore d'évaluation
- TD1 2023Document3 pagesTD1 2023Mouna Lakbakbi100% (1)
- MEC6215 - FRE - 04-02 - Instructions À Propos Des Rapports-1Document16 pagesMEC6215 - FRE - 04-02 - Instructions À Propos Des Rapports-1Exion GroupPas encore d'évaluation
- Guide de Maintenance CourroiesDocument15 pagesGuide de Maintenance CourroiesJamel CharefPas encore d'évaluation
- Sur La Limite D'une Composition de Deux FonctionsDocument2 pagesSur La Limite D'une Composition de Deux FonctionsWarda Jory100% (1)
- 2QA 6 016 05-Huile HydrauliqueDocument5 pages2QA 6 016 05-Huile Hydrauliqueoussama merPas encore d'évaluation
- 2 Chapitre1Document5 pages2 Chapitre1Mouad AliouaPas encore d'évaluation
- Chapitre 7 AOP Cour d'ELADocument13 pagesChapitre 7 AOP Cour d'ELAIkillilou Tabe ZakariPas encore d'évaluation
- Chapitre 3 Terpenes PDFDocument10 pagesChapitre 3 Terpenes PDFmohammed safouPas encore d'évaluation
- Suivi Et ÉvaluationDocument45 pagesSuivi Et ÉvaluationHassène Ben SalahPas encore d'évaluation
- TD 4Document2 pagesTD 4Fatis QueenPas encore d'évaluation
- Ma - Cuisine - 2 - 500 - Recettes - (... ) Escoffier - Auguste - bpt6k1265511c (Glissé (E) S) 3Document10 pagesMa - Cuisine - 2 - 500 - Recettes - (... ) Escoffier - Auguste - bpt6k1265511c (Glissé (E) S) 3lucasPas encore d'évaluation
- Plan D'appro Rev00Document5 pagesPlan D'appro Rev00Marwen MethenniPas encore d'évaluation
- Le Multiplexage Dans Le RTC 1Document6 pagesLe Multiplexage Dans Le RTC 1badreddinePas encore d'évaluation
- Bulletin 021 07Document3 pagesBulletin 021 07Walid NessabPas encore d'évaluation
- Exercice Chapitre 5 Et 6 Enonce Avec Place Pour RepondreDocument17 pagesExercice Chapitre 5 Et 6 Enonce Avec Place Pour RepondreInconnuPas encore d'évaluation