Vous aimerez peut-être aussi
- TD Econométrie Gestion - 2019-2020Document14 pagesTD Econométrie Gestion - 2019-2020elom ben FOLLYPas encore d'évaluation
- Cours Réactions Précipitation Et Complexation-L1SVTE 2020-2021Document27 pagesCours Réactions Précipitation Et Complexation-L1SVTE 2020-2021Haroun moussa HarounPas encore d'évaluation
- ES Maths - CNED - Sequence-05 - ES Maths CNED Sequence 3 (Sur 10) Lois Numeriques, Lois de BernoulliDocument26 pagesES Maths - CNED - Sequence-05 - ES Maths CNED Sequence 3 (Sur 10) Lois Numeriques, Lois de BernoullitoobaziPas encore d'évaluation
- MAchines AsynchroneDocument51 pagesMAchines AsynchroneMoussa SEYEPas encore d'évaluation
- ExerciceDocument24 pagesExerciceAbdellatif Elloumi100% (1)
- Chapitre 1 Généralités.Document27 pagesChapitre 1 Généralités.ETUSUP100% (1)
- Dynamique Des Sol 2Document71 pagesDynamique Des Sol 2SamehAnibi100% (1)
- Missael Devoir Econo Va QDocument38 pagesMissael Devoir Econo Va Qseptimus.pierrePas encore d'évaluation
- DEconova 6559Document21 pagesDEconova 6559septimus.pierrePas encore d'évaluation
- FaraM.J. Noel Devoir D - Econometrie Des Variables QualitativesDocument26 pagesFaraM.J. Noel Devoir D - Econometrie Des Variables Qualitativesseptimus.pierrePas encore d'évaluation
- PREMIERE PARTIE Eco VaqDocument8 pagesPREMIERE PARTIE Eco Vaqseptimus.pierrePas encore d'évaluation
- S6 B Td2 Eco Ges 19 20Document4 pagesS6 B Td2 Eco Ges 19 20Soufiane Faiz100% (1)
- Devoir1 - Econometrie Des Variables Qualitatifs - Nathalie F. THEODORE (Enregistré Automatiquement)Document36 pagesDevoir1 - Econometrie Des Variables Qualitatifs - Nathalie F. THEODORE (Enregistré Automatiquement)septimus.pierrePas encore d'évaluation
- Devoir 1Document21 pagesDevoir 1septimus.pierrePas encore d'évaluation
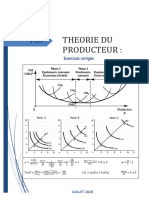
- Theorie Du Producteur ExercicesDocument26 pagesTheorie Du Producteur ExercicesIdelphonse SALIOUPas encore d'évaluation
- STATISTIQUES - PR IDRISSI KAITOUNIDocument63 pagesSTATISTIQUES - PR IDRISSI KAITOUNIrajid oumaimaPas encore d'évaluation
- TD Econométrie 1 Régression Linéaire MultipleDocument2 pagesTD Econométrie 1 Régression Linéaire Multiplemessaoudi makramPas encore d'évaluation
- L2 Maths Fi Cours 23 24 Module 3 Interets Composes 10pDocument10 pagesL2 Maths Fi Cours 23 24 Module 3 Interets Composes 10pmounialeanePas encore d'évaluation
- Economie - Exercices Chap1Document7 pagesEconomie - Exercices Chap1franck nzauPas encore d'évaluation
- Métodos NuméricosDocument21 pagesMétodos NuméricosVALENTINA MARULANDA GÓMEZPas encore d'évaluation
- Cours de Math CompletDocument23 pagesCours de Math CompletSimo LmfaddelPas encore d'évaluation
- 4eme seq class TDDocument2 pages4eme seq class TDMorel SimoPas encore d'évaluation
- CC1 2021-2022Document7 pagesCC1 2021-2022sll34000Pas encore d'évaluation
- Travaux ÉconometrieDocument5 pagesTravaux ÉconometriebabasPas encore d'évaluation
- Corrigé Examen BlancDocument4 pagesCorrigé Examen BlancDeniz AsliPas encore d'évaluation
- Test-Pré-requis - 42epromotion-Corrigé Test CptaDocument16 pagesTest-Pré-requis - 42epromotion-Corrigé Test CptaDaniel Ekoume8Pas encore d'évaluation
- s1 - Calcul - Tdexcorr - Doc - Rev 2019Document39 pagess1 - Calcul - Tdexcorr - Doc - Rev 2019api-203629011Pas encore d'évaluation
- Synthèse D'un Régulateur PID Analogique Pour Le Fonctionnement Optimal D'un Système PVDocument9 pagesSynthèse D'un Régulateur PID Analogique Pour Le Fonctionnement Optimal D'un Système PVZakaria MaazazPas encore d'évaluation
- Chapitre IIDocument9 pagesChapitre IIBøü KïPas encore d'évaluation
- Td1 Micro LaqribDocument5 pagesTd1 Micro LaqribReda LyoussfiPas encore d'évaluation
- TIGps CHAP1 MATHS-APP PCGDocument4 pagesTIGps CHAP1 MATHS-APP PCGKEUTCHAPas encore d'évaluation
- Corrigé TD 2Document20 pagesCorrigé TD 2Mohamed BoujnahPas encore d'évaluation
- Econométrie M1 - PolycompletDocument298 pagesEconométrie M1 - PolycompletJosé Ahanda Nguini100% (1)
- MathématiquesII - S2 - Livre (Mode de Compatibilité)Document101 pagesMathématiquesII - S2 - Livre (Mode de Compatibilité)Hamza SakhiPas encore d'évaluation
- Examen SC GMI 15 16Document3 pagesExamen SC GMI 15 16ayoub eljadidPas encore d'évaluation
- Exosuppsem 3Document6 pagesExosuppsem 3Christ TshitandaPas encore d'évaluation
- Baccalaureat Blanc General 2019 T.S.Eco Révisions N°1Document12 pagesBaccalaureat Blanc General 2019 T.S.Eco Révisions N°1dramanek0912100% (1)
- Projet Éolien 2007 (2022)Document12 pagesProjet Éolien 2007 (2022)MAGNANGOUPas encore d'évaluation
- Controle RO2015Document2 pagesControle RO2015Nourah AbPas encore d'évaluation
- Cours Maths Appl. TLE ACADocument25 pagesCours Maths Appl. TLE ACAMouzapPas encore d'évaluation
- DEVOIR (AKOUEHOU, BONOU Habib, DANSOU Giovanni, ZINSOU Karl)Document14 pagesDEVOIR (AKOUEHOU, BONOU Habib, DANSOU Giovanni, ZINSOU Karl)dfe100% (1)
- TD Stat DescDocument2 pagesTD Stat Desculrichtheyi1Pas encore d'évaluation
- TD2-1Document6 pagesTD2-1saze31201Pas encore d'évaluation
- Regréssion Simples Ex CorrDocument10 pagesRegréssion Simples Ex CorrDalida DlizaPas encore d'évaluation
- Econométrie Avancée Des Modèles LinéairesDocument4 pagesEconométrie Avancée Des Modèles Linéairesrey.payne12Pas encore d'évaluation
- Final Tp1 MatlabDocument23 pagesFinal Tp1 MatlabSAN RAKSAPas encore d'évaluation
- MicroeconomieDocument9 pagesMicroeconomieYassine El MansouriPas encore d'évaluation
- Bourse CasaDocument2 pagesBourse CasaMounir HarsiPas encore d'évaluation
- Corrigé SP Mai 2023 Macro LE1Document7 pagesCorrigé SP Mai 2023 Macro LE1chahedboukhatem0Pas encore d'évaluation
- YyyyhDocument4 pagesYyyyhMoussa Al HassanPas encore d'évaluation
- 1011 CC1 CoDocument5 pages1011 CC1 CopreaubertcPas encore d'évaluation
- TD AFP - CopieDocument13 pagesTD AFP - CopieEliada OlapadePas encore d'évaluation
- TP AutomatiqueDocument15 pagesTP Automatiqueloubna lamrabetPas encore d'évaluation
- S1Td2 MEA 17 18Document2 pagesS1Td2 MEA 17 18El-amarty AbdelaliPas encore d'évaluation
- MA41DV0322 Devoir4Document5 pagesMA41DV0322 Devoir4noellamendy32Pas encore d'évaluation
- CC 2009Document4 pagesCC 2009TITAITOQQPas encore d'évaluation
- CORRIGE TD 3 Marché Et Prix 2022-2023Document4 pagesCORRIGE TD 3 Marché Et Prix 2022-2023jacquesPas encore d'évaluation
- Fonction de Consommation Keynesienne - LireDocument4 pagesFonction de Consommation Keynesienne - LireYsf0% (1)
- Wa0004Document4 pagesWa0004Bartout YassinePas encore d'évaluation
- TD Econometrie 1Document4 pagesTD Econometrie 1Thắng HoàngPas encore d'évaluation
- TD1 2 3Document4 pagesTD1 2 3survixlebeauPas encore d'évaluation
- Variable Statistique DiscrèteDocument10 pagesVariable Statistique DiscrèteRanda BaylassanePas encore d'évaluation
- Examen Economie Des Affaires Juin 2018 CorrigéDocument4 pagesExamen Economie Des Affaires Juin 2018 CorrigéSami JaballahPas encore d'évaluation
- Plan Fitt ApproviDocument1 pagePlan Fitt Approviseptimus.pierrePas encore d'évaluation
- De La Crise FinancièreDocument5 pagesDe La Crise Financièreseptimus.pierrePas encore d'évaluation
- CO - 12022023 - RTS - Chien Et Carnaval - CorrigeDocument1 pageCO - 12022023 - RTS - Chien Et Carnaval - Corrigeseptimus.pierrePas encore d'évaluation
- Chap 001 DocDocument20 pagesChap 001 Docseptimus.pierrePas encore d'évaluation
- Chap1 EchantillonDocument13 pagesChap1 Echantillonabdelali elamartyPas encore d'évaluation
- Econometrie Va Qualitative DevoirDocument23 pagesEconometrie Va Qualitative Devoirseptimus.pierrePas encore d'évaluation
- Exo 1Document2 pagesExo 1septimus.pierrePas encore d'évaluation
- Associations de Generateurs TD CompletDocument6 pagesAssociations de Generateurs TD CompletAhmed AbatourabPas encore d'évaluation
- 61 C 46 Cccba 3 A 0028992297Document5 pages61 C 46 Cccba 3 A 0028992297Karim Melliti0% (2)
- LE CAFE - Torrefaction - TransportDocument1 pageLE CAFE - Torrefaction - TransportGedion DouaPas encore d'évaluation
- Chap 2 AlcènesDocument43 pagesChap 2 AlcènesWahab Houbad100% (1)
- AérogelDocument5 pagesAérogelchristophePas encore d'évaluation
- ChocsDocument2 pagesChocspitib88468Pas encore d'évaluation
- PolyDocument85 pagesPolyEmma DjomoPas encore d'évaluation
- FGD 212 S v1.03 EN FR ES (US)Document2 pagesFGD 212 S v1.03 EN FR ES (US)AndresZotticoPas encore d'évaluation
- Traiter: Logiques SequentiellesDocument4 pagesTraiter: Logiques SequentiellesBlaise EdimoPas encore d'évaluation
- Série D'exercices: Dipôles Passifs - 2nd S - SunudaaraDocument2 pagesSérie D'exercices: Dipôles Passifs - 2nd S - SunudaarafodekambalouPas encore d'évaluation
- Cours 2 - Action MecaniqueDocument3 pagesCours 2 - Action MecaniqueLindaPas encore d'évaluation
- Usinage LaserDocument2 pagesUsinage Lasersalah eddine bekhelifaPas encore d'évaluation
- ranaivosonTiavinaF ESPA MAST 21Document255 pagesranaivosonTiavinaF ESPA MAST 21DJARRA TIEMOKOPas encore d'évaluation
- Atelier 2 DSL-Xtext PR EntitéDocument5 pagesAtelier 2 DSL-Xtext PR EntitéES ChaymaaPas encore d'évaluation
- Sujet de Révision N°1 PDFDocument4 pagesSujet de Révision N°1 PDFjhygjhgjh KaelPas encore d'évaluation
- Pfe TunisDocument50 pagesPfe Tuniszineb aterta100% (1)
- Devoir 2 1°s 2013 2014Document1 pageDevoir 2 1°s 2013 2014Maria AlielhadjiabdouPas encore d'évaluation
- Le ThyristorDocument24 pagesLe Thyristorhissein ousmanPas encore d'évaluation
- JustBIM Fiche ProduitDocument2 pagesJustBIM Fiche ProduitStéphane LOTZPas encore d'évaluation
- Plan F12Document20 pagesPlan F12Stephane DuhotPas encore d'évaluation
- Regulation de La Temperature D'Une Serre Horticole: Par Logique FloueDocument51 pagesRegulation de La Temperature D'Une Serre Horticole: Par Logique FloueFatima EzzahraPas encore d'évaluation
- 2 4lesgammespentatoniquesDocument3 pages2 4lesgammespentatoniquesTarek Tarekus0% (1)
- Essai MdsDocument4 pagesEssai MdsHi BaPas encore d'évaluation
- Construction Métallique - 3 PDFDocument24 pagesConstruction Métallique - 3 PDFBadr ChattahyPas encore d'évaluation
- TD 05 ConvectionDocument2 pagesTD 05 ConvectionWail Dridi100% (3)
- Bfem 2009Document1 pageBfem 2009Diabel DiopPas encore d'évaluation