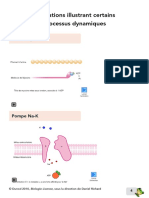
Vous aimerez peut-être aussi
- Corrigé DS RS 2017 - 2018Document5 pagesCorrigé DS RS 2017 - 2018ibrahim100% (1)
- 7 Géométrie Algébrique Une Introduction Daniel PerrinDocument317 pages7 Géométrie Algébrique Une Introduction Daniel PerrinibrahimPas encore d'évaluation
- Module 3 La Mise en Oeuvre La Résine Epoxy Clé en MainDocument19 pagesModule 3 La Mise en Oeuvre La Résine Epoxy Clé en Maintommy100% (1)
- American Gods - Neil GaimanDocument254 pagesAmerican Gods - Neil GaimanmrabdoPas encore d'évaluation
- Valorisation Du Patrimoine IntellectuelDocument6 pagesValorisation Du Patrimoine IntellectuelLONG DominiquePas encore d'évaluation
- BaniDocument11 pagesBaniMar Yam SarhanePas encore d'évaluation
- La Veille TechnologiqueDocument24 pagesLa Veille TechnologiqueOumaima Akz0% (1)
- Inpi PDFDocument27 pagesInpi PDFsarraPas encore d'évaluation
- Stratégie Breese MassonDocument12 pagesStratégie Breese MassonLouis BrowniePas encore d'évaluation
- Inventer Le Futur FinalDocument46 pagesInventer Le Futur Finalanass anasPas encore d'évaluation
- Academy dl170 Module 8 152043 FRDocument29 pagesAcademy dl170 Module 8 152043 FRDieu-donné KOLANIPas encore d'évaluation
- Guide Brevet FRDocument30 pagesGuide Brevet FRGerard TsimbopPas encore d'évaluation
- La Propriété Intellectuelle Et La Valo SensibilisationDocument44 pagesLa Propriété Intellectuelle Et La Valo SensibilisationKa Hina100% (1)
- Brevet Objet de Licencing VFDocument36 pagesBrevet Objet de Licencing VFmedactPas encore d'évaluation
- Les Inconvenients D Un Depot de Brevet PDocument15 pagesLes Inconvenients D Un Depot de Brevet PVALEAPas encore d'évaluation
- Dos06 ProfDocument10 pagesDos06 ProfFrancis TrouvainPas encore d'évaluation
- Droits de Propriété Intellectuelle Et Innovation Ouverte: Les Apports de Henry Chesbrough Cécile Ayerbe Et Valérie ChanalDocument7 pagesDroits de Propriété Intellectuelle Et Innovation Ouverte: Les Apports de Henry Chesbrough Cécile Ayerbe Et Valérie ChanalSarah BPas encore d'évaluation
- IP MasterClass - La Place Des Protections Intellectuelles Dans LDocument12 pagesIP MasterClass - La Place Des Protections Intellectuelles Dans LOlga ZatéPas encore d'évaluation
- Mémo Élève Fiche 10 - 019Document1 pageMémo Élève Fiche 10 - 019Edy MalouPas encore d'évaluation
- اليقضة التكنولوجيةDocument15 pagesاليقضة التكنولوجيةserponPas encore d'évaluation
- Cour de Droits de Propriete IndustrielleDocument10 pagesCour de Droits de Propriete IndustrielleMountaga BALDEPas encore d'évaluation
- Mooc PDFDocument7 pagesMooc PDFAkram LyakobyPas encore d'évaluation
- Méthodologie STAR - Créativité & InnovationDocument10 pagesMéthodologie STAR - Créativité & Innovationhafsaouiwafa390Pas encore d'évaluation
- La Stratégie de Propriété IntellectuelleDocument7 pagesLa Stratégie de Propriété IntellectuelleCharlotte EbangaPas encore d'évaluation
- Marché Des BrevetsDocument258 pagesMarché Des BrevetsVolantianaPas encore d'évaluation
- Va - Ahmed - Ibrahim - El-Demery Noha 16032011Document244 pagesVa - Ahmed - Ibrahim - El-Demery Noha 16032011Zoica NicolaPas encore d'évaluation
- Le Role Des FMN Dans Le CIDocument8 pagesLe Role Des FMN Dans Le CIomar bouifdenPas encore d'évaluation
- Les Brevets Dans La Législation Nationale Et Internationale - Docx CoursDocument6 pagesLes Brevets Dans La Législation Nationale Et Internationale - Docx CoursssiirriinneebenrhayemPas encore d'évaluation
- كتاب الاقمشة الذكيةDocument52 pagesكتاب الاقمشة الذكيةنصر من الله و فتح قريبPas encore d'évaluation
- Chap1 - Module Introduction Propriété Intellectuelle - UnlockedDocument19 pagesChap1 - Module Introduction Propriété Intellectuelle - UnlockedAhlemPas encore d'évaluation
- Principes de L'innovationDocument13 pagesPrincipes de L'innovationImad El Alami100% (1)
- Les Brevets Comme Moyen Daccès À La TECHNOLOGIEDocument12 pagesLes Brevets Comme Moyen Daccès À La TECHNOLOGIEkakirPas encore d'évaluation
- These JolivetDocument579 pagesThese JolivetLamia EddouchPas encore d'évaluation
- Lecon Cejm Cahp 11Document3 pagesLecon Cejm Cahp 11TRONCO ANGELO PIERREPas encore d'évaluation
- Giudici J IsdmDocument13 pagesGiudici J IsdmMezimes ChristianPas encore d'évaluation
- Cours PIDocument20 pagesCours PISami YahiaouiPas encore d'évaluation
- Seance 07 - Le Management de LinnovationDocument3 pagesSeance 07 - Le Management de LinnovationMohamed Amine BouchemamaPas encore d'évaluation
- Economie de L'innovationDocument57 pagesEconomie de L'innovationKarim FarjallahPas encore d'évaluation
- Ingénieur Et Intelligence Économique (Fév 2007)Document12 pagesIngénieur Et Intelligence Économique (Fév 2007)Nizar KoubâaPas encore d'évaluation
- Revisions-spe-SES 1Document10 pagesRevisions-spe-SES 1Ahmadullah TajalliPas encore d'évaluation
- La Veille TechnologiqueDocument14 pagesLa Veille TechnologiqueFahd MejdoubiPas encore d'évaluation
- EHEC Master Séminaire Innovations CommercialesDocument63 pagesEHEC Master Séminaire Innovations CommercialesetdalechekhabPas encore d'évaluation
- Contrats de DistributionDocument19 pagesContrats de DistributionStéphane DA SILVEIRAPas encore d'évaluation
- Cours 4 ELE InnovationDocument19 pagesCours 4 ELE InnovationMohamed MoussaouiPas encore d'évaluation
- Hec de L Innovation Au Marchcours540Document19 pagesHec de L Innovation Au Marchcours540Elmelki AnasPas encore d'évaluation
- Innovation - Collaborative - Et - Innovation - Ouverte-Materiel Pédagogique MRHDocument12 pagesInnovation - Collaborative - Et - Innovation - Ouverte-Materiel Pédagogique MRHmhr.chaimaaPas encore d'évaluation
- Économie de L Innovation. Nicolas Laroche Licence 3 APE Année 2009 - 2010 1Document77 pagesÉconomie de L Innovation. Nicolas Laroche Licence 3 APE Année 2009 - 2010 1Mohamed BachaPas encore d'évaluation
- 4.R - Sum - Diag - Techet - Sys - D - Info - 1 - .Docx Filename - UTF-8''Résumé Diag Techet Sys D InfoDocument7 pages4.R - Sum - Diag - Techet - Sys - D - Info - 1 - .Docx Filename - UTF-8''Résumé Diag Techet Sys D InfoAc Maroua100% (1)
- 1 Definitions Veille 2018Document30 pages1 Definitions Veille 2018houssam Ben yahiaPas encore d'évaluation
- 5 AP Initiation À La Création Et À L'innovation 2023 DRDocument3 pages5 AP Initiation À La Création Et À L'innovation 2023 DRchristophe.didierPas encore d'évaluation
- Économie Environnement InternationalDocument12 pagesÉconomie Environnement InternationalGOMEZPas encore d'évaluation
- Chap II NegociationDocument6 pagesChap II NegociationTANO DELABONDANCEPas encore d'évaluation
- 2010 Le Management Des Ressources TechnologiquesDocument38 pages2010 Le Management Des Ressources TechnologiquesSoumia Lioness Orihimie100% (1)
- Propriété IntellectuelleDocument92 pagesPropriété IntellectuelleMaryame MOUTAOUKILPas encore d'évaluation
- Dissertation Profit Et Innovation 2009-2010Document3 pagesDissertation Profit Et Innovation 2009-2010Mme et Mr LafonPas encore d'évaluation
- Guide La Protection Des Informations Sensibles Des EntreprisesDocument32 pagesGuide La Protection Des Informations Sensibles Des EntreprisesKalianaPas encore d'évaluation
- Cap Digital Annuaire ProjetsDocument207 pagesCap Digital Annuaire ProjetsTarek BouazzaPas encore d'évaluation
- MonirDocument10 pagesMonirFatima ezzahrae BaaddiPas encore d'évaluation
- Propriete IntellectuelleDocument57 pagesPropriete IntellectuelleАли Алжир100% (1)
- Présentation Entrepreneuriat AcadémiqueDocument9 pagesPrésentation Entrepreneuriat Académiqueechrak mejriPas encore d'évaluation
- MKG Entrepreneurial Chapitre 3+ - 1705299627183Document18 pagesMKG Entrepreneurial Chapitre 3+ - 1705299627183Esther MbuyiPas encore d'évaluation
- La Publicité Et La Signalisation Des Droits de Propriété Intellectuelle: Un Encadrement À ParfaireDocument42 pagesLa Publicité Et La Signalisation Des Droits de Propriété Intellectuelle: Un Encadrement À ParfaireulrichPas encore d'évaluation
- Fiches Apprentissage Assembleur CORTEX M4Document6 pagesFiches Apprentissage Assembleur CORTEX M4ibrahimPas encore d'évaluation
- TD TCP R&SDocument3 pagesTD TCP R&SibrahimPas encore d'évaluation
- Chapitre 3version FinaleDocument22 pagesChapitre 3version FinaleibrahimPas encore d'évaluation
- TD3 Reseaux RoutageDocument2 pagesTD3 Reseaux RoutageibrahimPas encore d'évaluation
- td1 2019Document2 pagestd1 2019ibrahim100% (1)
- Elements de Correction td2Document2 pagesElements de Correction td2ibrahimPas encore d'évaluation
- Correction de L'examen 2017-2018Document5 pagesCorrection de L'examen 2017-2018ibrahimPas encore d'évaluation
- Acte I 4Document2 pagesActe I 4ibrahimPas encore d'évaluation
- Atelier1 PowerQueryDocument2 pagesAtelier1 PowerQuerylouay bencheikhPas encore d'évaluation
- Generateur High Tech Mig Mag Digiwave III Saf-Fro FRDocument16 pagesGenerateur High Tech Mig Mag Digiwave III Saf-Fro FROmar MaalejPas encore d'évaluation
- SAAD 2019 ArchivageDocument224 pagesSAAD 2019 ArchivageCarlos Redondo BenitezPas encore d'évaluation
- Droit Des Affaires 2019 - 2020Document104 pagesDroit Des Affaires 2019 - 2020YassminaPas encore d'évaluation
- Série TD 5 Phys2 2019 2020+corrigéDocument5 pagesSérie TD 5 Phys2 2019 2020+corrigéamiranomi5Pas encore d'évaluation
- 1715944Document1 page1715944ADRIANNE BETTAPas encore d'évaluation
- Formula D PDFDocument16 pagesFormula D PDFNour-Eddine BenkerroumPas encore d'évaluation
- Pyramide MaslowDocument3 pagesPyramide Maslowvibus2014Pas encore d'évaluation
- Format Label 113Document5 pagesFormat Label 113Marlisa IchaPas encore d'évaluation
- 27 Eme - Tob - 02-10-2021Document2 pages27 Eme - Tob - 02-10-2021Joyce DouanlaPas encore d'évaluation
- Pinpankôd Désigne Celle Des Jeunes Garçons Et Filles Dont L'âge VarieDocument20 pagesPinpankôd Désigne Celle Des Jeunes Garçons Et Filles Dont L'âge VarieNajimou Alade TidjaniPas encore d'évaluation
- Brevet Sur Le Front Populaire Avec CorrectionDocument2 pagesBrevet Sur Le Front Populaire Avec Correctiondouzi nourPas encore d'évaluation
- 1710 PDF Du 30Document26 pages1710 PDF Du 30PDF JournalPas encore d'évaluation
- Flyer Passerelle VF (18752)Document2 pagesFlyer Passerelle VF (18752)grosjeanblandinePas encore d'évaluation
- Compl Biologie Etudiant S-1Document43 pagesCompl Biologie Etudiant S-1aloys NdziePas encore d'évaluation
- Manuel MilitaireDocument204 pagesManuel MilitaireFRED100% (1)
- Construire en TerreDocument274 pagesConstruire en Terreridha1964100% (4)
- PHARMACO Respi. Médicaments de La TouxDocument40 pagesPHARMACO Respi. Médicaments de La TouxyvesPas encore d'évaluation
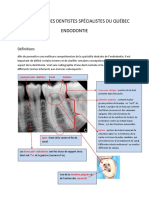
- Endo Revision PDFDocument13 pagesEndo Revision PDFMedecine Dentaire100% (2)
- ExamSys1 LMD 2010 2011 EpreuveCorDocument2 pagesExamSys1 LMD 2010 2011 EpreuveCorSira NdiayePas encore d'évaluation
- Histoire Et Géographie Sacrées Dans Le CoranDocument37 pagesHistoire Et Géographie Sacrées Dans Le CoranCatharsis HaddoukPas encore d'évaluation
- Ligne Directrice 2021 - DyslipidémieDocument1 pageLigne Directrice 2021 - Dyslipidémiesara harvey vachonPas encore d'évaluation
- Moez El Kouni: ExperienceDocument1 pageMoez El Kouni: ExperienceMoezPas encore d'évaluation
- Bourdieu Emprise JournalismeDocument4 pagesBourdieu Emprise JournalismebobyPas encore d'évaluation
- FoQual Rapport Incidents FRDocument40 pagesFoQual Rapport Incidents FRMarco SanPas encore d'évaluation
- A3 2 PDFDocument34 pagesA3 2 PDFLéopold SENEPas encore d'évaluation
- Babas Savarins-1Document1 pageBabas Savarins-1Benjamin GevoldePas encore d'évaluation
- Algorithmes de Traitement Suggeres HTADocument3 pagesAlgorithmes de Traitement Suggeres HTAZiedBenSassiPas encore d'évaluation