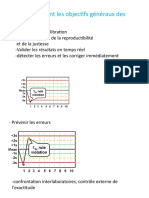
Vous aimerez peut-être aussi
- 1197 V1 I0 b1 EX 026 PRS GUIDE DE METROLODocument87 pages1197 V1 I0 b1 EX 026 PRS GUIDE DE METROLOLiyang GaoPas encore d'évaluation
- Principe D'etalonnageDocument4 pagesPrincipe D'etalonnageOlesea BolfosuPas encore d'évaluation
- Culture D'entreprise Et Performances D'organisationDocument19 pagesCulture D'entreprise Et Performances D'organisationMathieu Koloina91% (11)
- Qualite Des Resultàts D'Un Laboratoire: S.A.G.E.PDocument51 pagesQualite Des Resultàts D'Un Laboratoire: S.A.G.E.Pboualemtitiche1966Pas encore d'évaluation
- Choix Et Validation Methode-2Document31 pagesChoix Et Validation Methode-2Badr BouslamaPas encore d'évaluation
- CXG 054fDocument8 pagesCXG 054fboualemtitiche1966Pas encore d'évaluation
- Analyses de LaboratoireDocument13 pagesAnalyses de LaboratoireAbdellahPas encore d'évaluation
- Sdoc 09 10 SiDocument2 pagesSdoc 09 10 Siallilecheamani0Pas encore d'évaluation
- Chimie Analytique TGS Cours-1Document34 pagesChimie Analytique TGS Cours-1Mirabelle IssaPas encore d'évaluation
- PG Pre PostanalytiqueDocument3 pagesPG Pre PostanalytiqueAdil LagmarPas encore d'évaluation
- 6 Eme Année Erreurs Potentielles Dans Les Études Épidémiologiques PDFDocument35 pages6 Eme Année Erreurs Potentielles Dans Les Études Épidémiologiques PDFMamadou DIENEPas encore d'évaluation
- Physicochimie Des Produits AlimentairesDocument62 pagesPhysicochimie Des Produits AlimentairesMelissa BaloulPas encore d'évaluation
- Cours Chimie Analytique s3Document14 pagesCours Chimie Analytique s3safemind100% (1)
- Cours Physicochimie Des PA Master 2 CQDocument61 pagesCours Physicochimie Des PA Master 2 CQrbhhousnaPas encore d'évaluation
- 9-Dumontet Doc FDocument16 pages9-Dumontet Doc FbbdbdfPas encore d'évaluation
- La Validation de La Méthode AnalytiqueDocument39 pagesLa Validation de La Méthode AnalytiqueImane Ht100% (1)
- Lecture Critique Des Essais Cliniques Pour La Pratique MédicaleDocument70 pagesLecture Critique Des Essais Cliniques Pour La Pratique MédicaleMichel CucheratPas encore d'évaluation
- Aliapur - Prelevement Et Echantillonnage Des GranulatsDocument12 pagesAliapur - Prelevement Et Echantillonnage Des Granulatswouaw95220Pas encore d'évaluation
- Fraudes 1 PDFDocument18 pagesFraudes 1 PDFCherchali KhalidaPas encore d'évaluation
- Poster Analyse SensorielleDocument1 pagePoster Analyse Sensoriellenaomiesolefack03Pas encore d'évaluation
- 94 Justesse Fidélité PDFDocument66 pages94 Justesse Fidélité PDFAhmed HamadaPas encore d'évaluation
- Devoir Maison MetlegDocument7 pagesDevoir Maison MetlegFeriel InesPas encore d'évaluation
- DR12INC Guide IncertutudeDocument13 pagesDR12INC Guide IncertutudeAMINE OUTEZDOUTPas encore d'évaluation
- Chapitre3validationDocument5 pagesChapitre3validationguesmi manoubiyaPas encore d'évaluation
- Cours Chimiométrie N°3-Converti-1Document8 pagesCours Chimiométrie N°3-Converti-1Rachid SlimPas encore d'évaluation
- Inbound5985577376818810962 PDFDocument34 pagesInbound5985577376818810962 PDFarfaouihekmaPas encore d'évaluation
- Elment-D Preuvenull StudentDocument5 pagesElment-D Preuvenull StudentamazedPas encore d'évaluation
- AP 1S Mesures Incertitudes DILUTIONDocument6 pagesAP 1S Mesures Incertitudes DILUTIONBRAHIM BOUKALMOUNEPas encore d'évaluation
- Incertitudes Experimentales Bally BerroirDocument25 pagesIncertitudes Experimentales Bally BerroirSandraPas encore d'évaluation
- 11-Dumontet Incertitude MesureDocument10 pages11-Dumontet Incertitude MesureHassan HoudoudPas encore d'évaluation
- Eléments de Chimie Analytique 1 - IntroductionDocument60 pagesEléments de Chimie Analytique 1 - IntroductionYoussra CherratiPas encore d'évaluation
- IMEKO-TC10-2020-044 - 6 FRDocument13 pagesIMEKO-TC10-2020-044 - 6 FRboualemtitiche1966Pas encore d'évaluation
- 117 Mayor Valid-1Document18 pages117 Mayor Valid-1pamy26250Pas encore d'évaluation
- 8 B Content Qualqc FRDocument9 pages8 B Content Qualqc FRFATMA YOUCEFIPas encore d'évaluation
- 328 FDocument18 pages328 FCarlos Gene QuirozPas encore d'évaluation
- 5 Contrôle Du Processus - Gestion de L'échantillon. 14Document36 pages5 Contrôle Du Processus - Gestion de L'échantillon. 14Loyane LoïcPas encore d'évaluation
- 6-Annexe BDDocument24 pages6-Annexe BDSarra BenamorPas encore d'évaluation
- Assurance Qualité Dans Un Laboratoire de Biochimie - 104212Document26 pagesAssurance Qualité Dans Un Laboratoire de Biochimie - 104212Hætįčë MkhPas encore d'évaluation
- Résumé Partie 5Document4 pagesRésumé Partie 5charlyroy228Pas encore d'évaluation
- Formation Estimation Et Calcul Des Incertitudes de MesureDocument97 pagesFormation Estimation Et Calcul Des Incertitudes de MesureNOUR DAGHESNIPas encore d'évaluation
- Interpretation Desc Groupes Sanguins ABO Et Ses DifficultésDocument12 pagesInterpretation Desc Groupes Sanguins ABO Et Ses DifficultésAMJADPas encore d'évaluation
- Chimie V Pour L4 Biologiste-3Document45 pagesChimie V Pour L4 Biologiste-3Jacques KabambaPas encore d'évaluation
- Chapitre 3Document10 pagesChapitre 3Anonymous X4KQQi100% (1)
- 10 - Contôle de Qualité de Mesure CVP NNNDocument30 pages10 - Contôle de Qualité de Mesure CVP NNNAmadou DraboPas encore d'évaluation
- ChapitreDocument16 pagesChapitrehaniazer11Pas encore d'évaluation
- Dénombrement Des Salmonelles: Méthode Par Tubes MultiplesDocument19 pagesDénombrement Des Salmonelles: Méthode Par Tubes MultiplesKenz L'AïdPas encore d'évaluation
- Chimie Ana Envirnmt 4Document38 pagesChimie Ana Envirnmt 4Maxøn ChöcølatPas encore d'évaluation
- Controle de QualiteDocument53 pagesControle de QualiteAnonymous l2jAoHj8RPas encore d'évaluation
- Controles de QualiteDocument53 pagesControles de QualiteAnonymous Bw72Fv9ih100% (2)
- 7255 7255 PsDocument28 pages7255 7255 PsChouaibi FathiaPas encore d'évaluation
- Tpe Gestion PBDocument8 pagesTpe Gestion PBSamedi ParfaitPas encore d'évaluation
- 01-Biochimie Clinique 1 Biochimie2Document37 pages01-Biochimie Clinique 1 Biochimie2salahhe97nedromaPas encore d'évaluation
- LHB 1987031Document10 pagesLHB 1987031khadijasaadlah74Pas encore d'évaluation
- Chap II Caractéristiques Dun Instrument de Mesure - 1Document11 pagesChap II Caractéristiques Dun Instrument de Mesure - 1Mariama DOUCOUREPas encore d'évaluation
- TDPsDocument7 pagesTDPsBRAHIMPas encore d'évaluation
- Techniques EchantillonnageDocument26 pagesTechniques EchantillonnageDjamel AnteurPas encore d'évaluation
- Catalogue EchantillonnageDocument3 pagesCatalogue EchantillonnageAyisse AnlianePas encore d'évaluation
- Les erreurs fréquentes en Mathématiques du cycle secondaire: Enquête statistique - TOME IID'EverandLes erreurs fréquentes en Mathématiques du cycle secondaire: Enquête statistique - TOME IIPas encore d'évaluation
- Appliquer le modèle de Rasch: Défis et pistes de solutionD'EverandAppliquer le modèle de Rasch: Défis et pistes de solutionPas encore d'évaluation
- L' ETALONNAGE ET LA DECISION PSYCHOMETRIQUE, 2E EDITION: Exemples et tablesD'EverandL' ETALONNAGE ET LA DECISION PSYCHOMETRIQUE, 2E EDITION: Exemples et tablesPas encore d'évaluation
- Ergonomie Et Conditions de TravailDocument1 pageErgonomie Et Conditions de TravailZAKARI YAOUPas encore d'évaluation
- A Review of Cassava in Africawith Country Case Studies On Nigeria, Ghana, The United Republic of Tanzania, Uganda and BeninDocument13 pagesA Review of Cassava in Africawith Country Case Studies On Nigeria, Ghana, The United Republic of Tanzania, Uganda and BeninZAKARI YAOUPas encore d'évaluation
- Plan de Travail: CamerounDocument18 pagesPlan de Travail: CamerounZAKARI YAOUPas encore d'évaluation
- Djinodji ReoungalDocument357 pagesDjinodji ReoungalZAKARI YAOUPas encore d'évaluation
- 22-Baccouche Karaa BenyedderDocument26 pages22-Baccouche Karaa BenyedderZAKARI YAOUPas encore d'évaluation
- Business Plan PDFDocument8 pagesBusiness Plan PDFFerdinand HOUNYEMEPas encore d'évaluation
- 1 PBDocument12 pages1 PBKRAIMI NADIAPas encore d'évaluation
- PILOPROS 2018 Conf S2Document89 pagesPILOPROS 2018 Conf S2ZAKARI YAOUPas encore d'évaluation
- Extrait 42427210 PDFDocument127 pagesExtrait 42427210 PDFZAKARI YAOUPas encore d'évaluation
- Wcms 381203Document15 pagesWcms 381203ZAKARI YAOUPas encore d'évaluation
- BS en 9100 2018 Quality ManagementDocument62 pagesBS en 9100 2018 Quality ManagementZAKARI YAOUPas encore d'évaluation
- PDFDocument142 pagesPDFZAKARI YAOUPas encore d'évaluation
- Definitions Clés Culture Et DéveloppementDocument46 pagesDefinitions Clés Culture Et DéveloppementZAKARI YAOUPas encore d'évaluation
- CP Sous Traitance 2014 Contrat Complet Du BTP - 2014 02 19 - 16 55 4 - 278Document9 pagesCP Sous Traitance 2014 Contrat Complet Du BTP - 2014 02 19 - 16 55 4 - 278ZAKARI YAOUPas encore d'évaluation
- G5471-93004 - R00 - MiniHub - Safety - P - FRDocument52 pagesG5471-93004 - R00 - MiniHub - Safety - P - FRZAKARI YAOUPas encore d'évaluation
- UEMOA-Methodologie D'établissement Budget de Production CD11 - Lomé - r16Document36 pagesUEMOA-Methodologie D'établissement Budget de Production CD11 - Lomé - r16ZAKARI YAOUPas encore d'évaluation
- Wcms 756175Document96 pagesWcms 756175ZAKARI YAOUPas encore d'évaluation
- FR 7890B InstallationDocument86 pagesFR 7890B InstallationZAKARI YAOUPas encore d'évaluation
- Determination Frequence Controle Entreprise AlimentaireDocument11 pagesDetermination Frequence Controle Entreprise AlimentaireZAKARI YAOUPas encore d'évaluation
- Cahier Des Charge D Accreditation Organismes D Evaluation de La ConformiteDocument7 pagesCahier Des Charge D Accreditation Organismes D Evaluation de La ConformiteZAKARI YAOUPas encore d'évaluation
- Systeme Ouest Africain D 'Accreditation (Soac) : C01.02-Règlement D'accréditation - Octobre 19 Page 1 Sur 21Document21 pagesSysteme Ouest Africain D 'Accreditation (Soac) : C01.02-Règlement D'accréditation - Octobre 19 Page 1 Sur 21ZAKARI YAOUPas encore d'évaluation
- Wcms 768055Document93 pagesWcms 768055ZAKARI YAOUPas encore d'évaluation
- G2170-93022 EbookDocument166 pagesG2170-93022 EbookZAKARI YAOUPas encore d'évaluation
- CXG 003fDocument13 pagesCXG 003fZAKARI YAOUPas encore d'évaluation
- CXG 003fDocument13 pagesCXG 003fZAKARI YAOUPas encore d'évaluation
- CXG 054fDocument8 pagesCXG 054fZAKARI YAOUPas encore d'évaluation
- Code D'usage Sur La Gestion Des Allergènes AlimentairesDocument23 pagesCode D'usage Sur La Gestion Des Allergènes AlimentairesAyoub OUBAHAPas encore d'évaluation
- CXG 092fDocument8 pagesCXG 092fZAKARI YAOUPas encore d'évaluation
- TP Conduction CompletDocument10 pagesTP Conduction Complethamza layachi75% (4)
- NF EN 1431 (Mai 2009)Document19 pagesNF EN 1431 (Mai 2009)Fatima BouhajaPas encore d'évaluation
- Api RestDocument8 pagesApi RestfogoPas encore d'évaluation
- TF06 P09 MedianDocument4 pagesTF06 P09 MedianAyt Moha BrahimPas encore d'évaluation
- Maths X PSI 1998 (Enoncé)Document7 pagesMaths X PSI 1998 (Enoncé)LM --Pas encore d'évaluation
- Cahier de Charge Du ProjetDocument4 pagesCahier de Charge Du ProjetMehdi KhaledPas encore d'évaluation
- Chapitre 1 - Eléments de Physique NucléaireDocument69 pagesChapitre 1 - Eléments de Physique NucléaireMohamed El Hadi Redjaimia100% (1)
- Rapport Optimisation Sur MatlabDocument13 pagesRapport Optimisation Sur MatlabLino YETONGNONPas encore d'évaluation
- Sujet Bac 2023 Guinee Niger MathsDocument5 pagesSujet Bac 2023 Guinee Niger Mathsmr.4chiffrePas encore d'évaluation
- Poly JavaDocument176 pagesPoly JavaLeonzoConstantiniPas encore d'évaluation
- Ajust ExpoDocument4 pagesAjust ExpoMme_Sos100% (1)
- UE Cybersécurité-Initiation Metasploit v0.3Document17 pagesUE Cybersécurité-Initiation Metasploit v0.3didierPas encore d'évaluation
- Incendie: I-Prévention Et ProtectionDocument4 pagesIncendie: I-Prévention Et Protectionraid bazizPas encore d'évaluation
- DJE4394Document119 pagesDJE4394danPas encore d'évaluation
- 04 JSFT-echangeur-2012 GRESPI Fohanno PDFDocument21 pages04 JSFT-echangeur-2012 GRESPI Fohanno PDFzermiPas encore d'évaluation
- GPM Tle C 3e Edition.Document258 pagesGPM Tle C 3e Edition.Pierrot Jules AMOUSSOU100% (2)
- FeuilletageDocument25 pagesFeuilletageLē JøkērPas encore d'évaluation
- PdM3 Guide Corrige Vrac Repros C4Document2 pagesPdM3 Guide Corrige Vrac Repros C4Eva BteichPas encore d'évaluation
- Mémoire de Master-YF-Post Soutenance-20200610Document70 pagesMémoire de Master-YF-Post Soutenance-20200610Yacinthe FAYE100% (1)
- ChapitreDocument8 pagesChapitreAchour IfrekPas encore d'évaluation
- Geometrie Pour Dao2 PDFDocument161 pagesGeometrie Pour Dao2 PDFlekouf43100% (1)
- W - 250 - 275 - 325 - 350 - 400 - 1 K..p..Document28 pagesW - 250 - 275 - 325 - 350 - 400 - 1 K..p..joviadoPas encore d'évaluation
- Examen de Fin de Formation 2008 Tsri Pratique Variante 9Document5 pagesExamen de Fin de Formation 2008 Tsri Pratique Variante 9FatimaLEPas encore d'évaluation
- Corrige TD 8 1920 2Document5 pagesCorrige TD 8 1920 2friends diaryPas encore d'évaluation
- Cours Lignes de Transmission Séance Adaptation D'impédance 2011 2012Document8 pagesCours Lignes de Transmission Séance Adaptation D'impédance 2011 2012benlamlihPas encore d'évaluation
- Howto L3 IntervlanroutingDocument7 pagesHowto L3 IntervlanroutingWilford ToussaintPas encore d'évaluation
- Transferts en PoreuxDocument644 pagesTransferts en PoreuxYacine KaPas encore d'évaluation
- TD6 PhysiqueDocument4 pagesTD6 PhysiqueEric DeumoPas encore d'évaluation
- Algèbre 1 V. Def 2017-2018Document141 pagesAlgèbre 1 V. Def 2017-2018Alexis Rosuel100% (1)
- Année Prépa Electricité, Deuxième PartieDocument221 pagesAnnée Prépa Electricité, Deuxième PartieAbdelkader Faklani DouPas encore d'évaluation