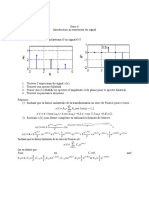
Vous aimerez peut-être aussi
- Exercice D'application AutomatiqueDocument7 pagesExercice D'application AutomatiqueSissy carburePas encore d'évaluation
- TP N°3: Oscillations D'un Systeme Couple A Deux Degres de LiberteDocument8 pagesTP N°3: Oscillations D'un Systeme Couple A Deux Degres de LiberteAzOu DzPas encore d'évaluation
- I - Rappels Sur Les Equations Différentielles OrdinairesDocument5 pagesI - Rappels Sur Les Equations Différentielles OrdinairesLyes YoucefPas encore d'évaluation
- td6 Mat 3136Document6 pagestd6 Mat 3136Arnauld LefortPas encore d'évaluation
- 11 PDFDocument2 pages11 PDFBrsioft BloggerPas encore d'évaluation
- Corrigé Du Bac Blanc MathDocument17 pagesCorrigé Du Bac Blanc MathMehdi AgPas encore d'évaluation
- Polymaths2a 060109 Chap3Document30 pagesPolymaths2a 060109 Chap3IsmaëlPas encore d'évaluation
- Correction Série de Révision Exercice 1 Et 2Document4 pagesCorrection Série de Révision Exercice 1 Et 2Wael MaatougPas encore d'évaluation
- TD1 Math4 2020Document4 pagesTD1 Math4 2020bmessaad1970Pas encore d'évaluation
- Cor ST1 Janvier 2014 PDFDocument4 pagesCor ST1 Janvier 2014 PDFtsimania degolPas encore d'évaluation
- TD6 CorrigeDocument16 pagesTD6 CorrigeRomaissa LoulhaciPas encore d'évaluation
- Equations Différentielles Linéaires - Systèmes Différentiels Linéaire D - Ordre 1Document3 pagesEquations Différentielles Linéaires - Systèmes Différentiels Linéaire D - Ordre 1Hamza PrintoOsPas encore d'évaluation
- 5f564404669d4ISE - Maths 2020 CorrigesDocument22 pages5f564404669d4ISE - Maths 2020 CorrigesTinePas encore d'évaluation
- Fiche de TD Ger 3 Fasa 2022-2023Document3 pagesFiche de TD Ger 3 Fasa 2022-2023Duchel Amayana ayangmaPas encore d'évaluation
- MA261 Cours4 ColDocument18 pagesMA261 Cours4 ColMeriem saidiPas encore d'évaluation
- 2 TransmittancesDocument26 pages2 TransmittancesRuphin KabaselePas encore d'évaluation
- PolyTD EDP PDFDocument30 pagesPolyTD EDP PDFFatima EzzahraPas encore d'évaluation
- Mart Cor ch8Document5 pagesMart Cor ch8kainaPas encore d'évaluation
- Oraux 2016 Solutions SiteDocument109 pagesOraux 2016 Solutions SiteProcopiusPas encore d'évaluation
- Corrigé Révision MISDocument2 pagesCorrigé Révision MISAbd Errezak ChahoubPas encore d'évaluation
- Corrige-Iford Voie A 2019 Maths PDFDocument6 pagesCorrige-Iford Voie A 2019 Maths PDFChancelin KeukouaPas encore d'évaluation
- Cour4 ENSEMDocument7 pagesCour4 ENSEMKhadija BousbaiatPas encore d'évaluation
- Bac C Corrige Mathémathiques 2016Document8 pagesBac C Corrige Mathémathiques 2016JUNIOR KIANGPas encore d'évaluation
- Travaux Dirigés Part IIDocument6 pagesTravaux Dirigés Part IISissy carbure100% (1)
- Sujet Corrige EF FVC 17-18Document4 pagesSujet Corrige EF FVC 17-18Ima NePas encore d'évaluation
- Un Corrigé Exam 19-20Document4 pagesUn Corrigé Exam 19-20saidbanachPas encore d'évaluation
- TD P 11 20 - CorrDocument4 pagesTD P 11 20 - Corrhometv.lg.smart2023Pas encore d'évaluation
- TD3 Edp IDocument1 pageTD3 Edp IAissatou BaPas encore d'évaluation
- Corrige PSDocument3 pagesCorrige PSTakidine AhandourPas encore d'évaluation
- S2 - Chapitre 1 - Section 1Document37 pagesS2 - Chapitre 1 - Section 1leilarabhi16Pas encore d'évaluation
- Série Corrigés Sur Les Couples Continues ÉtudiantsDocument9 pagesSérie Corrigés Sur Les Couples Continues ÉtudiantsDrissi Chihab81% (16)
- SERIE 3 DEFORMaTIONDocument10 pagesSERIE 3 DEFORMaTIONBouchra AskriPas encore d'évaluation
- Mathsl3 Suites Ordre DeuxDocument5 pagesMathsl3 Suites Ordre DeuxYovish NursimoolooPas encore d'évaluation
- Ma201 td01Document4 pagesMa201 td01hich afouPas encore d'évaluation
- 8 Puissances Et Calcul de Primitives Ou D'intégralesDocument7 pages8 Puissances Et Calcul de Primitives Ou D'intégraleslvtmathPas encore d'évaluation
- Couples Et Vecteurs de VAR FiniesDocument11 pagesCouples Et Vecteurs de VAR FiniesDouae OGPas encore d'évaluation
- TP 3 RenduDocument20 pagesTP 3 RenduBARKANPas encore d'évaluation
- Va EPcoDocument5 pagesVa EPcoArthur Franck Patrick BledouPas encore d'évaluation
- Corrigé TD Analyse2 MI Equat Diff 19 20Document15 pagesCorrigé TD Analyse2 MI Equat Diff 19 20Hind ChadliPas encore d'évaluation
- ÉconométrieDocument17 pagesÉconométrieNada BarkalahPas encore d'évaluation
- Eamac Physique IngDocument38 pagesEamac Physique Ingabdoulkarimouedraogo5589Pas encore d'évaluation
- EnoncéDocument14 pagesEnoncéLouis OlivePas encore d'évaluation
- E3A 2023 aPC CorrigeDocument8 pagesE3A 2023 aPC Corrigecacaric982Pas encore d'évaluation
- Correction Examen MMC 2022 Master1Document7 pagesCorrection Examen MMC 2022 Master1Khaled GammoudiPas encore d'évaluation
- Corrigé de La Série 2 MhsDocument9 pagesCorrigé de La Série 2 Mhsmalika elorfPas encore d'évaluation
- TD1Document2 pagesTD1Mohamed AIT KASSIPas encore d'évaluation
- SMII Exos1Document11 pagesSMII Exos1karim belaliaPas encore d'évaluation
- Corrigã© de La Sã©rie 3Document8 pagesCorrigã© de La Sã©rie 3hgmyycrsxkPas encore d'évaluation
- TD No 1 - SAPS - 2022 - STDocument12 pagesTD No 1 - SAPS - 2022 - STOubaida21 SnackPas encore d'évaluation
- Corrige - Serie6 - Dynamique Des Structures 2020 2021Document3 pagesCorrige - Serie6 - Dynamique Des Structures 2020 2021Hamza El khayatPas encore d'évaluation
- td3 Corrige Stochastique DauphineDocument5 pagestd3 Corrige Stochastique DauphinejileneblaPas encore d'évaluation
- TD7 - Traitement de Singal - 2018 - 2019Document9 pagesTD7 - Traitement de Singal - 2018 - 2019nait ahmed hasnaPas encore d'évaluation
- Sol TD4Document11 pagesSol TD4etdalechekhab100% (1)
- MathDocument10 pagesMathsawadogoPas encore d'évaluation
- Examen Final Danalyse 2Document4 pagesExamen Final Danalyse 2badis idiriPas encore d'évaluation
- Corrige ExamMai2014 L3maths SystDiffDocument4 pagesCorrige ExamMai2014 L3maths SystDiffFrankie KowaPas encore d'évaluation
- Exercices An NumDocument10 pagesExercices An Numbennaysanae6Pas encore d'évaluation
- Optidyn UobDocument6 pagesOptidyn Uobstevy darelPas encore d'évaluation
- Équations différentielles: Les Grands Articles d'UniversalisD'EverandÉquations différentielles: Les Grands Articles d'UniversalisPas encore d'évaluation
- Analyse Mathématique pour l'ingénieur: Analyse Mathématique pour l'ingénieur, #2D'EverandAnalyse Mathématique pour l'ingénieur: Analyse Mathématique pour l'ingénieur, #2Pas encore d'évaluation
- Pour MemoireDocument5 pagesPour MemoireatktaouPas encore d'évaluation
- S P Essonne Nov2018Document7 pagesS P Essonne Nov2018atktaouPas encore d'évaluation
- Guide Indemnites Deplacement PDFDocument21 pagesGuide Indemnites Deplacement PDFmounjimPas encore d'évaluation
- NV Resumé atDocument37 pagesNV Resumé atatktaouPas encore d'évaluation
- Rapport Rating Des Entities PubliquesDocument11 pagesRapport Rating Des Entities PubliquesatktaouPas encore d'évaluation
- 162480KHK Eval PDFDocument39 pages162480KHK Eval PDFskandaranPas encore d'évaluation
- Abdelaziz ERCHIDIDocument73 pagesAbdelaziz ERCHIDIatktaouPas encore d'évaluation
- Emp AlgerieDocument20 pagesEmp AlgerieatktaouPas encore d'évaluation
- Probabilités Et Analyse Des Données StatistiquesDocument631 pagesProbabilités Et Analyse Des Données StatistiquesPatman MutomboPas encore d'évaluation
- Université de Franche Comté (U. F. C) : Marchés Boursiers Émergents Et Problèmatique de L'EfficienceDocument394 pagesUniversité de Franche Comté (U. F. C) : Marchés Boursiers Émergents Et Problèmatique de L'EfficienceatktaouPas encore d'évaluation
- Chaabi Bank Guide Tarifaire Produits Et Services 0123Document15 pagesChaabi Bank Guide Tarifaire Produits Et Services 0123atktaouPas encore d'évaluation
- Revue KhazinaDocument48 pagesRevue KhazinasaudiPas encore d'évaluation
- Contenu Informatif Des États Financiers AnnuelsDocument21 pagesContenu Informatif Des États Financiers AnnuelsatktaouPas encore d'évaluation
- 5056 13687 1 SMDocument12 pages5056 13687 1 SMyoussefriifiPas encore d'évaluation
- 2384 7899 1 SMDocument7 pages2384 7899 1 SMatktaouPas encore d'évaluation
- Le DH Marocain Distorsion de Change Devaluation EtDocument13 pagesLe DH Marocain Distorsion de Change Devaluation Etmohamed bekkalPas encore d'évaluation
- 2011 HeuristiquedereprsentativitDocument27 pages2011 HeuristiquedereprsentativitatktaouPas encore d'évaluation
- Rindu1 151 0019Document5 pagesRindu1 151 0019atktaouPas encore d'évaluation
- Chapitre 5Document22 pagesChapitre 5AyoubPas encore d'évaluation
- SSRN Id2173365Document13 pagesSSRN Id2173365atktaouPas encore d'évaluation
- 1 PBDocument38 pages1 PBModeste DarjPas encore d'évaluation
- 002590584Document15 pages002590584atktaouPas encore d'évaluation
- 5051 13677 1 SMDocument12 pages5051 13677 1 SMyoussefriifiPas encore d'évaluation
- Impact de La Multibancarite Sur Le Financement Des Pme LocalesDocument14 pagesImpact de La Multibancarite Sur Le Financement Des Pme LocalesHamza ChPas encore d'évaluation
- Fiscalite Delentreprise FdresDocument6 pagesFiscalite Delentreprise FdresatktaouPas encore d'évaluation
- 1 PBDocument30 pages1 PBatktaouPas encore d'évaluation
- Adoukonou OlivierDocument213 pagesAdoukonou OlivieratktaouPas encore d'évaluation
- Bakerm Mendel, Wurgler Behavioral Signaling 0001 FRDocument78 pagesBakerm Mendel, Wurgler Behavioral Signaling 0001 FRatktaouPas encore d'évaluation
- Syber RG Snhar Znevarf QH Znebp Ovbqvirefvgr Ovbybtvr Rpbybtvr OvbtrbtencuvrDocument1 pageSyber RG Snhar Znevarf QH Znebp Ovbqvirefvgr Ovbybtvr Rpbybtvr OvbtrbtencuvratktaouPas encore d'évaluation
- ApplicationsDocument15 pagesApplicationseya larbiPas encore d'évaluation
- Le Gradient D'une Fonction ScalaireDocument3 pagesLe Gradient D'une Fonction ScalaireSami NasryPas encore d'évaluation
- Applications Affines - 2 - TranslationDocument2 pagesApplications Affines - 2 - TranslationAyouba Ag OumarPas encore d'évaluation
- Exercice N° 1 (Droite D'euler) 8 PointsDocument3 pagesExercice N° 1 (Droite D'euler) 8 Pointsayoub ayoubbPas encore d'évaluation
- Chap 04 - Ex 4A - Placer Un Point Donné Par Une Égalité de Vecteurs - CORRIGEDocument2 pagesChap 04 - Ex 4A - Placer Un Point Donné Par Une Égalité de Vecteurs - CORRIGESamuel KouassiPas encore d'évaluation
- 06 DiscretisationDocument17 pages06 Discretisationxavier nkungwaPas encore d'évaluation
- PolynômesDocument4 pagesPolynômesMaïlys PichelinPas encore d'évaluation
- Comparaison Fonctions SuitesDocument3 pagesComparaison Fonctions SuitesDoshey AllouPas encore d'évaluation
- Inégalités: Inégalités Bien Plus Que Des Égalités, Et On Pourrait Le Résumer en Ces Jean DieudonnéDocument21 pagesInégalités: Inégalités Bien Plus Que Des Égalités, Et On Pourrait Le Résumer en Ces Jean DieudonnéMarc TentiPas encore d'évaluation
- Cours - Ensembles Finis Et Denombrement 34Document6 pagesCours - Ensembles Finis Et Denombrement 34SCRIBD CONTACTPas encore d'évaluation
- Fasicule 1S2Document41 pagesFasicule 1S2Yaya TouréPas encore d'évaluation
- 02 Symboles Somme ProduitDocument9 pages02 Symboles Somme ProduitbadrePas encore d'évaluation
- Ser 04Document1 pageSer 04micheldelabourePas encore d'évaluation
- 2020 - Analyse CPI1 Chapitre4Document10 pages2020 - Analyse CPI1 Chapitre4boucharebPas encore d'évaluation
- TD Cocyclicite-Isometrie TS1 LLG 2022-2023Document6 pagesTD Cocyclicite-Isometrie TS1 LLG 2022-2023kathyPas encore d'évaluation
- Normal 2023 CORRDocument10 pagesNormal 2023 CORRMoulham KhalidPas encore d'évaluation
- Cours Math Chapitre 15 Géométrie Analytique MR Hamada)Document12 pagesCours Math Chapitre 15 Géométrie Analytique MR Hamada)AmmarPas encore d'évaluation
- Cours 5 Fonction PrimitivesDocument2 pagesCours 5 Fonction Primitiveszineddine100% (1)
- SeriesFourier PDFDocument58 pagesSeriesFourier PDFDJIL BENPas encore d'évaluation
- Exercices, Mines Ponts - Oral PDFDocument88 pagesExercices, Mines Ponts - Oral PDFMahmoudSfarHanchaPas encore d'évaluation
- Bac SM Maths 2007Document3 pagesBac SM Maths 2007donaldcow04Pas encore d'évaluation
- Algèbre MP2 PDFDocument3 pagesAlgèbre MP2 PDFamaniPas encore d'évaluation
- Bacc Math A 1999-2014 PDFDocument32 pagesBacc Math A 1999-2014 PDFradina100% (2)
- Programme Maths ECS 1ere AnneeDocument29 pagesProgramme Maths ECS 1ere Anneesarasakani05Pas encore d'évaluation
- Hoss 555Document13 pagesHoss 555Houssem LakhouaPas encore d'évaluation
- Les Fractions Fractions Et Droites GradueesDocument30 pagesLes Fractions Fractions Et Droites GradueesalainestorPas encore d'évaluation
- CC Analyse 1 (20-21)Document1 pageCC Analyse 1 (20-21)oli verPas encore d'évaluation
- EQUA Système D'équationDocument2 pagesEQUA Système D'équationRazarasoa ManahiranaPas encore d'évaluation
- Chapitre 18: Espaces Vectiels.: Cours Du 03/02/2022Document70 pagesChapitre 18: Espaces Vectiels.: Cours Du 03/02/2022Fatna ELKHAYDERPas encore d'évaluation
- Série N3 MEF ENER2 Octobre 2022Document4 pagesSérie N3 MEF ENER2 Octobre 2022Saif ElgharselleouiPas encore d'évaluation