Vous aimerez peut-être aussi
- Solution Manual For Security in Computing 5th by PfleegerDocument24 pagesSolution Manual For Security in Computing 5th by Pfleegermichellelewismqdacbxijt100% (43)
- Presentation Muda DEF09Document26 pagesPresentation Muda DEF09Salma Benouaali100% (1)
- Les Enjeux de La Communication FinancièreDocument6 pagesLes Enjeux de La Communication FinancièreTIZAOUIPas encore d'évaluation
- 1 - Qu'Est Ce Que La Résolution de ProblèmesDocument44 pages1 - Qu'Est Ce Que La Résolution de ProblèmesAmine SebbaniPas encore d'évaluation
- Chap 3 Simulation Des Systèmes de ProductionDocument22 pagesChap 3 Simulation Des Systèmes de ProductionSami SellamiPas encore d'évaluation
- 7 AmdecDocument20 pages7 AmdecAmina BoujeglatPas encore d'évaluation
- Six SigmaDocument17 pagesSix SigmaBenYamOuN IsMaIlPas encore d'évaluation
- Algorithme de Colonie de Fourmis 2 FSTF PDFDocument40 pagesAlgorithme de Colonie de Fourmis 2 FSTF PDFHoussine GuePas encore d'évaluation
- AMDECDocument20 pagesAMDECGhita TitaPas encore d'évaluation
- QualitéDocument31 pagesQualitéchboukiPas encore d'évaluation
- Kaizen Version FinalDocument35 pagesKaizen Version Finalali boko100% (1)
- B.1 Méthodes Et Techniques:: - A. Première PartieDocument29 pagesB.1 Méthodes Et Techniques:: - A. Première Partieiraoui jamal (Ebay)Pas encore d'évaluation
- Ingénieur en Sûreté de Fonctionnement: AtoutsDocument1 pageIngénieur en Sûreté de Fonctionnement: AtoutsKARIM EL QARAOUIPas encore d'évaluation
- TPLM S11Document13 pagesTPLM S11Chakib BenmhamedPas encore d'évaluation
- Amdec SiteDocument27 pagesAmdec SiteYoussef ChakliPas encore d'évaluation
- 52démarche Coq-Côut D'obtention de La QualitéDocument1 page52démarche Coq-Côut D'obtention de La QualitéMed. ELMPas encore d'évaluation
- Guide Amdec Trs Intressant 160211075316 PDFDocument27 pagesGuide Amdec Trs Intressant 160211075316 PDFHantanirina Miarintsoa ANDRIANARIJAONAPas encore d'évaluation
- Recrutement Et Selection Des Ressources Humaines 3Document1 pageRecrutement Et Selection Des Ressources Humaines 3kihimiPas encore d'évaluation
- Méthode AMDECDocument44 pagesMéthode AMDECstagfire17Pas encore d'évaluation
- AMDECDocument100 pagesAMDECHoussam OurchidPas encore d'évaluation
- Formation D'auditeurs InterneDocument67 pagesFormation D'auditeurs InterneAlamdouni Almoussi MouradPas encore d'évaluation
- Cours Master AMDEC V EtudiantsDocument102 pagesCours Master AMDEC V EtudiantsYou Nes Medjdoub100% (1)
- IC Annual Manager Evaluation Template 17094 - FRDocument12 pagesIC Annual Manager Evaluation Template 17094 - FRKéassa Rodolphe OULAIPas encore d'évaluation
- Presentation AmdecDocument39 pagesPresentation AmdecChikhaouiPas encore d'évaluation
- P3FR Analyse Des Couts Et Prise de DecisionsDocument4 pagesP3FR Analyse Des Couts Et Prise de DecisionsYoussefPas encore d'évaluation
- Poster SurveillanceDocument1 pagePoster SurveillanceSindri PareinPas encore d'évaluation
- Etape de l'AMDECDocument9 pagesEtape de l'AMDECPrincia BitoriPas encore d'évaluation
- IC Annual Manager Evaluation Template 17094 - FRDocument12 pagesIC Annual Manager Evaluation Template 17094 - FRservicerhdevpacPas encore d'évaluation
- FICHE - Initiez Vous Au Machine LearningDocument1 pageFICHE - Initiez Vous Au Machine LearningAlexandro cocouviPas encore d'évaluation
- Ch6 - Méthode de Diagnostic ADEPA-CETIMDocument6 pagesCh6 - Méthode de Diagnostic ADEPA-CETIMyoussef machkourPas encore d'évaluation
- 1 Algo Evo Chapitre 4 Algorithmes Évolutionnaires Multi-ObjectifsDocument81 pages1 Algo Evo Chapitre 4 Algorithmes Évolutionnaires Multi-ObjectifsseifPas encore d'évaluation
- Rapport AMDECDocument22 pagesRapport AMDECAhmedPas encore d'évaluation
- 7 AmdecDocument21 pages7 Amdecasmaa el akliPas encore d'évaluation
- Outils MéthodologiquesDocument34 pagesOutils Méthodologiquesamani bouslimiPas encore d'évaluation
- Lean Réengineering Delayeringbenchmarking ISETDocument24 pagesLean Réengineering Delayeringbenchmarking ISETMouna BedhiafPas encore d'évaluation
- VF - Guide FR CA - Gestion Des Risques 2023Document25 pagesVF - Guide FR CA - Gestion Des Risques 2023adamdcbPas encore d'évaluation
- Titre IciDocument15 pagesTitre Icitaguefranck223Pas encore d'évaluation
- Lean ManagementDocument26 pagesLean Managementimen ben talebPas encore d'évaluation
- Presentation Muda DEF09Document26 pagesPresentation Muda DEF09MILOWSKIPas encore d'évaluation
- ATL15Document2 pagesATL15Rabah AmidiPas encore d'évaluation
- MémoireDocument11 pagesMémoireAbir BaghdadliPas encore d'évaluation
- Méthodes D'analyse de La SDFDocument32 pagesMéthodes D'analyse de La SDFBOUDOUNIT YounesPas encore d'évaluation
- Présentation 4Document14 pagesPrésentation 4Ahmed EnnakiliPas encore d'évaluation
- Chapitre7 Intelligence ArtificielleDocument29 pagesChapitre7 Intelligence ArtificiellevenanceharoldPas encore d'évaluation
- Tutoriel Adaboost Haar LBP Face DetectionDocument27 pagesTutoriel Adaboost Haar LBP Face Detectiondahman160% (1)
- AMDECDocument20 pagesAMDECElnBEKKARYPas encore d'évaluation
- 2 - RCPS Etapes 1,2 Et 3Document49 pages2 - RCPS Etapes 1,2 Et 3Amine SebbaniPas encore d'évaluation
- Amdec 1638287290Document4 pagesAmdec 1638287290Wafa SaidaniPas encore d'évaluation
- ACF SchemasDocument4 pagesACF SchemasKamalPas encore d'évaluation
- Mag Sges Kerroucha IkramDocument127 pagesMag Sges Kerroucha IkramKahina AlouanePas encore d'évaluation
- TPM Mastere 2020 Partie 2 Strategie Et Methodologie. Les Huit Piliers de La TPM EtudiantsDocument97 pagesTPM Mastere 2020 Partie 2 Strategie Et Methodologie. Les Huit Piliers de La TPM EtudiantsLAMYAPas encore d'évaluation
- PFE - Final 1212Document40 pagesPFE - Final 1212Lihidheb FirasPas encore d'évaluation
- Cours 6 ADDDocument20 pagesCours 6 ADDMouâd El-koubbiPas encore d'évaluation
- CO 003 Présentation Collection LeanDocument97 pagesCO 003 Présentation Collection LeanSalma100% (1)
- Cours MSP JrifiDocument83 pagesCours MSP JrifiFatimazahra ElmPas encore d'évaluation
- Gestion Des NonconformitésDocument24 pagesGestion Des NonconformitésDaruine Jophrey NtariPas encore d'évaluation
- CH02-Analyse Des Modes de Défaillance, de Leurs Effets, de Leur Criticité - AMDECDocument30 pagesCH02-Analyse Des Modes de Défaillance, de Leurs Effets, de Leur Criticité - AMDECBouchoucha jameleddinePas encore d'évaluation
- AMDEC SimpifDocument13 pagesAMDEC SimpifKhaled KalaiPas encore d'évaluation
- Couts de Non-Qualite Et Couts Caches PDFDocument21 pagesCouts de Non-Qualite Et Couts Caches PDFFrancklin BaguiPas encore d'évaluation
- Détection des piétons: S'il vous plaît, suggérez un sous-titre pour un livre intitulé « Détection des piétons » dans le domaine de la « Vision par ordinateur ». Le sous-titre suggéré ne doit pas contenir de ':'.D'EverandDétection des piétons: S'il vous plaît, suggérez un sous-titre pour un livre intitulé « Détection des piétons » dans le domaine de la « Vision par ordinateur ». Le sous-titre suggéré ne doit pas contenir de ':'.Pas encore d'évaluation
- Apprentissage SuperviséDocument61 pagesApprentissage SuperviséequipeprotobilePas encore d'évaluation
- Introduction Apprentissage AutomatiqueDocument115 pagesIntroduction Apprentissage AutomatiqueequipeprotobilePas encore d'évaluation
- Apprentissage Non Supervisé 1Document129 pagesApprentissage Non Supervisé 1equipeprotobilePas encore d'évaluation
- Planning Formation WillyDocument2 pagesPlanning Formation WillyequipeprotobilePas encore d'évaluation
- Cours - 02 - Prinicipes Et Concepts GénérauxDocument10 pagesCours - 02 - Prinicipes Et Concepts GénérauxcharefeddinetorkiPas encore d'évaluation
- Rapport D'intervention IndustrieDocument2 pagesRapport D'intervention IndustrieAdama SawadogoPas encore d'évaluation
- Iscae IfDocument71 pagesIscae IffbentaharPas encore d'évaluation
- Cours Complet Analyse FinancièreDocument153 pagesCours Complet Analyse FinancièreMOPas encore d'évaluation
- Vocabulaire Kabyle de L'ostéologie Et de L'orthopédieDocument330 pagesVocabulaire Kabyle de L'ostéologie Et de L'orthopédieamazighisant100% (5)
- 24ème Dimanche Année CDocument2 pages24ème Dimanche Année CPatrick LessiPas encore d'évaluation
- TD Tns-SticDocument3 pagesTD Tns-Sticqzsv7wpnnwPas encore d'évaluation
- Guide GLPI-FusionInventory - NagiosDocument12 pagesGuide GLPI-FusionInventory - NagiosAITALI MohamedPas encore d'évaluation
- FondProf Presentation TechniqueDocument21 pagesFondProf Presentation TechniqueMarc Landry FokwaPas encore d'évaluation
- HD9 E5-6x6-F PDFDocument4 pagesHD9 E5-6x6-F PDFJawad EnnasihiPas encore d'évaluation
- Liste Des Cartes Évolution CélesteDocument1 pageListe Des Cartes Évolution CélesteMohammed ChihazPas encore d'évaluation
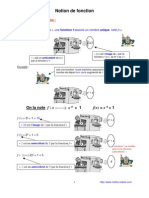
- Notion de Fonction (3ème)Document3 pagesNotion de Fonction (3ème)MATHS - VIDEOSPas encore d'évaluation
- Cours Mecanique Tekwin2Document321 pagesCours Mecanique Tekwin2Khaled Belhouchet100% (1)
- Exploration Biologique Du FoieDocument9 pagesExploration Biologique Du FoieYounes Hadj CharefPas encore d'évaluation
- Chapitre 2 - Evolutions Économiques Et Sociales Dans Les Pays Occidentaux D'une Guerre À L'autreDocument24 pagesChapitre 2 - Evolutions Économiques Et Sociales Dans Les Pays Occidentaux D'une Guerre À L'autreNazwa NubowoPas encore d'évaluation
- Contrôles Particulaires Et Microbiologiques de L'air Et Contrôles Microbiologiques Des Surfaces Dans Les Établissements de Santé.Document12 pagesContrôles Particulaires Et Microbiologiques de L'air Et Contrôles Microbiologiques Des Surfaces Dans Les Établissements de Santé.amiraPas encore d'évaluation
- Resume Du TPDocument9 pagesResume Du TPMOUGANGPas encore d'évaluation
- La Place de La RSE Dans L Approche RelatDocument728 pagesLa Place de La RSE Dans L Approche RelattrabelsiPas encore d'évaluation
- Bulletin Dessai Gaine Streamline Plus 1.05l HDocument3 pagesBulletin Dessai Gaine Streamline Plus 1.05l Hhoda miliouPas encore d'évaluation
- Chapitre 434Document18 pagesChapitre 434dieudonnepooda71Pas encore d'évaluation
- Thèse: Philosophiæ Doctor (Ph. D.)Document188 pagesThèse: Philosophiæ Doctor (Ph. D.)Oussama ChahirPas encore d'évaluation
- Te25 Installation Reparation de Commande Electronique Des MoteursDocument129 pagesTe25 Installation Reparation de Commande Electronique Des MoteursAymen ChaairaPas encore d'évaluation
- VARIATEUR - DE - VITESSE - Doc ProfDocument3 pagesVARIATEUR - DE - VITESSE - Doc Profsaid100% (2)
- 10-DS Chaîne de MontageDocument3 pages10-DS Chaîne de MontagesaulnierPas encore d'évaluation
- Cours Site - Diversite Et Stabilite Genetique Des Individus PDFDocument5 pagesCours Site - Diversite Et Stabilite Genetique Des Individus PDFsambaPas encore d'évaluation
- TP #1 CristallographieDocument14 pagesTP #1 CristallographieMohamed CHIBANPas encore d'évaluation
- PMMP Formulaire D Inscription Des Entreprises 2017Document2 pagesPMMP Formulaire D Inscription Des Entreprises 2017Aalaeddine Afifi100% (2)
- IntroductionDocument12 pagesIntroductionrabeh khenPas encore d'évaluation