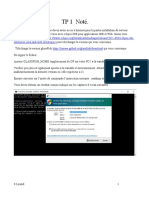
Vous aimerez peut-être aussi
- Biologie Moleculaire: Cours deDocument98 pagesBiologie Moleculaire: Cours deMERYAM CHAWKIPas encore d'évaluation
- Construction-Maison-Ossature-Bois-Pour ÉtudiantsDocument2 pagesConstruction-Maison-Ossature-Bois-Pour ÉtudiantsBENYAHIA NESRINEPas encore d'évaluation
- 14-Généralités Sur Les Antibiotiques Et Principes D'utilisation - PR K.reggABIDocument35 pages14-Généralités Sur Les Antibiotiques Et Principes D'utilisation - PR K.reggABIAlex JuvePas encore d'évaluation
- Nouveau Cours Bioinformatique PDFDocument51 pagesNouveau Cours Bioinformatique PDFKhabtane Abdelhamid100% (2)
- ChapI ENZYMOLOGIE COENZYMES ET VITAMINESDocument49 pagesChapI ENZYMOLOGIE COENZYMES ET VITAMINESbessama84100% (2)
- Bio InformatiqueDocument199 pagesBio Informatiquerobndoh100% (1)
- Culture CellulaireDocument25 pagesCulture CellulaireHadjer AdaidaPas encore d'évaluation
- Generalites BioinformatiqueDocument42 pagesGeneralites BioinformatiqueMariane LinganiPas encore d'évaluation
- Introduction BioinformatiqueDocument37 pagesIntroduction BioinformatiqueMaï SsaPas encore d'évaluation
- Cours1 Bioinformatique 2021Document23 pagesCours1 Bioinformatique 2021linePas encore d'évaluation
- TD Génomique Master UFR Sci Bio DR DagoDocument18 pagesTD Génomique Master UFR Sci Bio DR DagoPrince Otti's Officiel100% (1)
- Cours 1 BioInfoDocument20 pagesCours 1 BioInfoAYATI100% (1)
- TD Génomique Master UFR Sci Bio DR DagoDocument11 pagesTD Génomique Master UFR Sci Bio DR DagoFANKELE ALASSANE KONE100% (1)
- 1 - Introduction À La GénomiqueDocument39 pages1 - Introduction À La GénomiqueSamehPas encore d'évaluation
- 3-Cours-TD Bioinformatique - Etudiants - 05 - 05 - 2022Document79 pages3-Cours-TD Bioinformatique - Etudiants - 05 - 05 - 2022Oumia HarbitPas encore d'évaluation
- Cours 1 BioinformatiqueDocument55 pagesCours 1 BioinformatiqueATTAH Régis Patrick AusséPas encore d'évaluation
- Travaux Pratiques de BioinformatiqueDocument11 pagesTravaux Pratiques de BioinformatiqueSayah Ben DobPas encore d'évaluation
- Cours 4 BioInfoDocument40 pagesCours 4 BioInfoAYATIPas encore d'évaluation
- TP Bioinformatique Mai 2021Document2 pagesTP Bioinformatique Mai 2021abdellah elghebouliPas encore d'évaluation
- TP - 01Document2 pagesTP - 01Slimkhane DzPas encore d'évaluation
- 1 - Introduction À La GénomiqueDocument22 pages1 - Introduction À La Génomiquea.itatahine100% (1)
- Compte Rendu TP BioinformatiqueDocument7 pagesCompte Rendu TP BioinformatiqueAsmaa Aghrou.Pas encore d'évaluation
- Cours1 Introduction A La Bioinfo2021-SV3-SVT34x4Document12 pagesCours1 Introduction A La Bioinfo2021-SV3-SVT34x4Aym NePas encore d'évaluation
- GENOMIQUE - RésuméDocument5 pagesGENOMIQUE - RésuméRafa100% (1)
- Cours Enzyme Complexe Substrat Etat Transition Stereospecificite Catalyse Enseignement Recherche Biochimie Enzymologie Bioinformatique Emmanuel Jaspard Universite Angers BiochimejDocument27 pagesCours Enzyme Complexe Substrat Etat Transition Stereospecificite Catalyse Enseignement Recherche Biochimie Enzymologie Bioinformatique Emmanuel Jaspard Universite Angers BiochimejTCHEMMIK NazihaPas encore d'évaluation
- Partie 1 - Biologie MoleculaireDocument48 pagesPartie 1 - Biologie MoleculaireZineb ZinebPas encore d'évaluation
- Empreinte Dnase Gene RaporterDocument27 pagesEmpreinte Dnase Gene RaporterMaï Ssa100% (1)
- Olymerase Hain Eaction Ou PCR Reaction en Chaine de La PolymeraseDocument34 pagesOlymerase Hain Eaction Ou PCR Reaction en Chaine de La PolymeraseMohamed ECHAMAIPas encore d'évaluation
- TBMCDocument19 pagesTBMCLalisa ManobanPas encore d'évaluation
- Cours Alignement BlastDocument48 pagesCours Alignement BlastlinePas encore d'évaluation
- Cours 5 Clonage Et Vecteurs de ClonageDocument37 pagesCours 5 Clonage Et Vecteurs de ClonageOwassiPas encore d'évaluation
- Cours BM Master Les Techniques1Document29 pagesCours BM Master Les Techniques1Zineb IfriPas encore d'évaluation
- BIOINFORMATIQUE Cours4 BlastDocument31 pagesBIOINFORMATIQUE Cours4 BlastSlimkhane DzPas encore d'évaluation
- TP Les Bases de Données Biologiques M1 Microbiologie AppliquéeDocument2 pagesTP Les Bases de Données Biologiques M1 Microbiologie AppliquéeMohamed Salik100% (2)
- PCRDocument14 pagesPCRopenlabunistraPas encore d'évaluation
- TP 2 (Introduction À La Bioinformatique) (B)Document2 pagesTP 2 (Introduction À La Bioinformatique) (B)Hasna BikiPas encore d'évaluation
- TD Biologie Moléculaire BPR 2021Document21 pagesTD Biologie Moléculaire BPR 2021rafaramalala1307Pas encore d'évaluation
- Bio-Informatique MoléculaireDocument327 pagesBio-Informatique MoléculaireMohamed MSAADIPas encore d'évaluation
- TD.02. BiomolDocument35 pagesTD.02. BiomolChawki Mokadem100% (1)
- Génétique Microbienne PDFDocument65 pagesGénétique Microbienne PDFAnonymous MKSfyYyODPPas encore d'évaluation
- Exercice S 2016Document17 pagesExercice S 2016Aboubakar LawanePas encore d'évaluation
- Chapitre II La Réplication de LADNDocument37 pagesChapitre II La Réplication de LADNfekhar adlenPas encore d'évaluation
- Reponses Aux Exercices Genie GenetiqueDocument3 pagesReponses Aux Exercices Genie GenetiqueangelesPas encore d'évaluation
- Cours BIOINFO 2019 KARUDocument140 pagesCours BIOINFO 2019 KARUZakariya nadirPas encore d'évaluation
- 03 - Génétique BactérienneDocument60 pages03 - Génétique Bactériennebouchakour meryemPas encore d'évaluation
- Diapos Ed9 ProteomiqueDocument55 pagesDiapos Ed9 ProteomiqueEmna El Hammi100% (1)
- TD1+Solution Génie GénétiqueDocument5 pagesTD1+Solution Génie Génétiqueمحمد الأمين ولد عالي ابليلPas encore d'évaluation
- Cours 2-Alignement de Sequence 2019Document19 pagesCours 2-Alignement de Sequence 2019Katia MerahPas encore d'évaluation
- La PCR PDFDocument27 pagesLa PCR PDFfaroukPas encore d'évaluation
- Enzyme Utilisee en Biologie MoleculaireDocument28 pagesEnzyme Utilisee en Biologie Moleculairerahamamaiga808Pas encore d'évaluation
- Les Techniques D'extraction d'ADNDocument11 pagesLes Techniques D'extraction d'ADNjoel fleuristalPas encore d'évaluation
- Cours Bases de Donnes 04 Bio InfoDocument58 pagesCours Bases de Donnes 04 Bio InfoImene SemmarPas encore d'évaluation
- La RT PCRDocument12 pagesLa RT PCRMbacké0% (1)
- Cours 4 Génie GénétiqueDocument26 pagesCours 4 Génie GénétiqueAy IşığıPas encore d'évaluation
- TP4 Microbiologie Générale-Identification Par Caractérisation BiochimiqueDocument11 pagesTP4 Microbiologie Générale-Identification Par Caractérisation Biochimiquesonia HALAOULIPas encore d'évaluation
- 2020-L1SV-Fascicule-Bio MolDocument8 pages2020-L1SV-Fascicule-Bio Molkirito 83Pas encore d'évaluation
- La R Plication de l'ADNDocument17 pagesLa R Plication de l'ADNjonas100% (1)
- 2 Canevas Licence - Biotechnologie MicrobienneDocument83 pages2 Canevas Licence - Biotechnologie MicrobienneHiba BourkabPas encore d'évaluation
- Cultures Et Croissances MicrobiennesDocument26 pagesCultures Et Croissances Microbiennesbouchakour meryemPas encore d'évaluation
- Ecologie MicrobienneDocument25 pagesEcologie MicrobiennesamPas encore d'évaluation
- Les Portails Expasy Et NCBI ?Document21 pagesLes Portails Expasy Et NCBI ?Anis Abd Raouf BouzidPas encore d'évaluation
- MaindocumentDocument14 pagesMaindocumentBENYAHIA NESRINEPas encore d'évaluation
- A-Analyse Geometrique de La PieceDocument8 pagesA-Analyse Geometrique de La PieceBENYAHIA NESRINEPas encore d'évaluation
- Analyse Syntaxique AscendanteDocument1 pageAnalyse Syntaxique AscendanteBENYAHIA NESRINEPas encore d'évaluation
- Main DocumentaikDocument39 pagesMain DocumentaikBENYAHIA NESRINEPas encore d'évaluation
- DescriptionD Taill eDuCas SupprimerContactDocument1 pageDescriptionD Taill eDuCas SupprimerContactBENYAHIA NESRINEPas encore d'évaluation
- Chapitre 1 Introduction Sur Les Systèmes Distribués (Slides)Document57 pagesChapitre 1 Introduction Sur Les Systèmes Distribués (Slides)BENYAHIA NESRINEPas encore d'évaluation
- DescriptionD - Taill - eDuCas - Modifier ContactDocument1 pageDescriptionD - Taill - eDuCas - Modifier ContactBENYAHIA NESRINEPas encore d'évaluation
- Sujet 2 LicenceDocument2 pagesSujet 2 LicenceBENYAHIA NESRINEPas encore d'évaluation
- Partie 5 Slide Livre Réseaux InformatiquesDocument26 pagesPartie 5 Slide Livre Réseaux InformatiquesBENYAHIA NESRINEPas encore d'évaluation
- DescriptionD - Taill - eDuCas - Sup ContactDocument1 pageDescriptionD - Taill - eDuCas - Sup ContactBENYAHIA NESRINEPas encore d'évaluation
- Cours Extensif IntobjTDocument79 pagesCours Extensif IntobjTBENYAHIA NESRINEPas encore d'évaluation
- TP Microbiologie de Lenvironnement Zerroug ADocument6 pagesTP Microbiologie de Lenvironnement Zerroug Aibtissem ibtissemPas encore d'évaluation
- TP 2 ExtensifDocument9 pagesTP 2 ExtensifBENYAHIA NESRINEPas encore d'évaluation
- Economie NumiriqueDocument2 pagesEconomie NumiriqueBENYAHIA NESRINEPas encore d'évaluation
- Présentation 1Document10 pagesPrésentation 1BENYAHIA NESRINEPas encore d'évaluation
- Sécurité Dans Les TransportsDocument158 pagesSécurité Dans Les TransportsBENYAHIA NESRINEPas encore d'évaluation
- TP 1 ExtensifDocument16 pagesTP 1 ExtensifBENYAHIA NESRINEPas encore d'évaluation
- Partie 1Document55 pagesPartie 1BENYAHIA NESRINEPas encore d'évaluation
- Transport InternationalDocument36 pagesTransport InternationalBENYAHIA NESRINEPas encore d'évaluation
- Maintenabilité Des Systèmes de Transport V3Document82 pagesMaintenabilité Des Systèmes de Transport V3BENYAHIA NESRINEPas encore d'évaluation
- Cours Parasitologie L3 PPTX (Partie 01) 25 05 2021Document24 pagesCours Parasitologie L3 PPTX (Partie 01) 25 05 2021BENYAHIA NESRINEPas encore d'évaluation
- TP 1Document1 pageTP 1BENYAHIA NESRINEPas encore d'évaluation
- Partie 2Document35 pagesPartie 2BENYAHIA NESRINEPas encore d'évaluation
- TD 01 EnzymologieDocument2 pagesTD 01 EnzymologieBENYAHIA NESRINEPas encore d'évaluation
- Cours Parasitologie L3 PPTX (Partie 02) 25 05 2021Document13 pagesCours Parasitologie L3 PPTX (Partie 02) 25 05 2021BENYAHIA NESRINEPas encore d'évaluation
- Cours Parasitologie L3 PPTX (Partie 03) 12 06 2021Document16 pagesCours Parasitologie L3 PPTX (Partie 03) 12 06 2021BENYAHIA NESRINEPas encore d'évaluation
- Chapitre 01Document7 pagesChapitre 01BENYAHIA NESRINEPas encore d'évaluation
- TP 1Document2 pagesTP 1BENYAHIA NESRINEPas encore d'évaluation
- C5 - Physiologie de La Coagulation FDocument15 pagesC5 - Physiologie de La Coagulation FAziza AskriPas encore d'évaluation
- 13 QCM Bacteriologie GeneralDocument14 pages13 QCM Bacteriologie Generalimad dahmaniPas encore d'évaluation
- Grappin Germination 8dec10Document67 pagesGrappin Germination 8dec10Emira MK100% (1)
- Lipoproteines & Plaque D'atheromeDocument15 pagesLipoproteines & Plaque D'atheromescaren efonaPas encore d'évaluation
- 1 GlycolyseDocument47 pages1 GlycolyseHanane HananePas encore d'évaluation
- Diabètes MODY: Il Faut y Penser: Maturity Onset Diabetes of The Young: Just Think About ItDocument6 pagesDiabètes MODY: Il Faut y Penser: Maturity Onset Diabetes of The Young: Just Think About ItBest ManPas encore d'évaluation
- Le Séquencage DADN 1Document4 pagesLe Séquencage DADN 1Kada BouameurPas encore d'évaluation
- BiochimieDocument42 pagesBiochimieAchwak Belfadel100% (1)
- Régulation Des EnzymesDocument25 pagesRégulation Des EnzymesAnfel AbdPas encore d'évaluation
- Cellule Bacterienne Chap II 2 PartieDocument26 pagesCellule Bacterienne Chap II 2 Partieهشام شريفيPas encore d'évaluation
- 1 - Introduction À L'étude de La GénétiqueDocument5 pages1 - Introduction À L'étude de La GénétiqueKaty BarnesPas encore d'évaluation
- These Evaluation-Des-Proprietes-Catalytiques-Des-Complexes-De-CuivreDocument52 pagesThese Evaluation-Des-Proprietes-Catalytiques-Des-Complexes-De-CuivreWail MadridPas encore d'évaluation
- Corrige Bac D SVT 2023Document3 pagesCorrige Bac D SVT 2023oilibenfahadPas encore d'évaluation
- Résistances Bactériennes AntiobioDocument15 pagesRésistances Bactériennes AntiobioImane RahPas encore d'évaluation
- Chapitre I Organisation Générale Des CellulesDocument9 pagesChapitre I Organisation Générale Des CellulesAnthony Mary75% (4)
- Genie GenetiqueDocument107 pagesGenie GenetiqueYousfi Koussaila80% (10)
- Cours 07 Bio InfoDocument39 pagesCours 07 Bio InfoImene SemmarPas encore d'évaluation
- Défense Et Immunité - DjangoDocument86 pagesDéfense Et Immunité - DjangoTiboPas encore d'évaluation
- KEBTANE MohamedDocument3 pagesKEBTANE MohamedLaboratoire ElmoustakbelPas encore d'évaluation
- 6 - Phase Intestinale Et ColiqueDocument12 pages6 - Phase Intestinale Et ColiqueIslam MoussaouiPas encore d'évaluation
- 5 - IgsDocument26 pages5 - IgsMohamed DaifPas encore d'évaluation
- Bacc Blanc SVT TC-TD 2013Document6 pagesBacc Blanc SVT TC-TD 2013workfreelyPas encore d'évaluation
- S1 TD2 Protides PDFDocument8 pagesS1 TD2 Protides PDFmartinmune67% (3)
- Correction Des Exercices Sur L'énergie BiologiqueDocument6 pagesCorrection Des Exercices Sur L'énergie BiologiqueConstantin Nilda NgueyaPas encore d'évaluation
- Structure Des BactériesDocument9 pagesStructure Des BactérieskhouildiPas encore d'évaluation
- 1-Molécules de La Vie - RETRANSCRIPTION DU COURS ENREGISTRÉDocument18 pages1-Molécules de La Vie - RETRANSCRIPTION DU COURS ENREGISTRÉtoorop krazzPas encore d'évaluation
- PDF 21jan24 0547 SplittedDocument1 pagePDF 21jan24 0547 SplittedMohamed MéknPas encore d'évaluation
- RTU_GlucoseDocument3 pagesRTU_Glucoseroumayssaa.yPas encore d'évaluation