Vous aimerez peut-être aussi
- Modele A Trois FacteursDocument20 pagesModele A Trois FacteursNguyen Thi Thanh Binh100% (1)
- Modèle Fama French À Trois FacteursDocument29 pagesModèle Fama French À Trois FacteursHadyl Chokri100% (2)
- Rapport Sur Le Modã Le Multifactoriel FamaDocument26 pagesRapport Sur Le Modã Le Multifactoriel Famasamira zahirPas encore d'évaluation
- Cours Econometrie Finance TDDocument11 pagesCours Econometrie Finance TDfaten_chtourou100% (1)
- Bla 00032Document40 pagesBla 00032Chatiri AzizPas encore d'évaluation
- Wharton Macro Analysis PDFMomentumDocument70 pagesWharton Macro Analysis PDFMomentumRoman El FhalPas encore d'évaluation
- Arbitrage Pricing Theory 1Document10 pagesArbitrage Pricing Theory 1Ziyad SabourPas encore d'évaluation
- Gestion Des Risques Financiers - Mon - CoursDocument15 pagesGestion Des Risques Financiers - Mon - CoursBy mePas encore d'évaluation
- Chapitre 2Document8 pagesChapitre 2EL MAOULI ZAKARIAPas encore d'évaluation
- Choix de PortefeuilleDocument26 pagesChoix de PortefeuilleAlison Del VecchioPas encore d'évaluation
- TD N°2 - CorrigéDocument4 pagesTD N°2 - CorrigéSalma Lamghari0% (1)
- 717-Article Text-2699-1-10-20210711Document19 pages717-Article Text-2699-1-10-20210711Hight HopesPas encore d'évaluation
- Document 4 Le Coût Du CapitalDocument18 pagesDocument 4 Le Coût Du CapitalSalma ElPas encore d'évaluation
- RésumésDocument7 pagesRésumésIchrak BenPas encore d'évaluation
- 1 PBDocument16 pages1 PBfatmi zakariaPas encore d'évaluation
- CM 2 - Chap2 - Rentabilité Risque SEPT2021Document34 pagesCM 2 - Chap2 - Rentabilité Risque SEPT2021bocar sallPas encore d'évaluation
- Fama Et FrenchDocument71 pagesFama Et FrenchCherif Amen AllahPas encore d'évaluation
- Présentation Et Hypothèses Du Modèle 2. Implication Du Modèle D'équilibre 3. Utilité Et Les Limites Du MEDAFDocument9 pagesPrésentation Et Hypothèses Du Modèle 2. Implication Du Modèle D'équilibre 3. Utilité Et Les Limites Du MEDAFEL MAOULI ZAKARIAPas encore d'évaluation
- Theorie FinanciereDocument14 pagesTheorie FinancieresmatiPas encore d'évaluation
- MEDAFDocument3 pagesMEDAFIslam El OusroutiPas encore d'évaluation
- Exposé Théorie FinanciereDocument12 pagesExposé Théorie FinanciereMohamed BenbouzidPas encore d'évaluation
- FinanceDocument34 pagesFinancePPTPas encore d'évaluation
- BDF BM 3 Etu 10 t1Document15 pagesBDF BM 3 Etu 10 t1Al-amin MohammadPas encore d'évaluation
- Prime de Risque Sur Capitaux PropresDocument25 pagesPrime de Risque Sur Capitaux PropresMustapha El MansariPas encore d'évaluation
- Théories Modernes de Gestion de Portefeuille: Chapitre 2Document22 pagesThéories Modernes de Gestion de Portefeuille: Chapitre 2hajar elmazaniPas encore d'évaluation
- CAPM Et APTDocument23 pagesCAPM Et APTMajda Sealiti TrokastiPas encore d'évaluation
- Arbitrage Pricing TheoryDocument3 pagesArbitrage Pricing TheoryZiyad SabourPas encore d'évaluation
- Gestion de PortefeuilleDocument14 pagesGestion de PortefeuillesmatiPas encore d'évaluation
- Niveau: 3ème Année Finance TD-4&5 Gestion de PortefeuilleDocument4 pagesNiveau: 3ème Année Finance TD-4&5 Gestion de Portefeuillesiwar.zrelliPas encore d'évaluation
- Gestion de PortefeuilleDocument8 pagesGestion de PortefeuilleFatima-ezzahrae ElaabediPas encore d'évaluation
- GPF EnnonceDocument3 pagesGPF EnnonceKKKLM..OOOYnPas encore d'évaluation
- Econometrie App À La Finance Chap1Document24 pagesEconometrie App À La Finance Chap1bohmid003Pas encore d'évaluation
- CampDocument38 pagesCampOussama Ez'Pas encore d'évaluation
- Traité de gestion de portefeuille, 5e édition actualisée: Titres à revenu fixe et produits structurés - Avec applications Excel (Visual Basic)D'EverandTraité de gestion de portefeuille, 5e édition actualisée: Titres à revenu fixe et produits structurés - Avec applications Excel (Visual Basic)Pas encore d'évaluation
- VaR SONDJODocument30 pagesVaR SONDJOisiris34Pas encore d'évaluation
- MEDAF InternationalDocument37 pagesMEDAF InternationalHadyl Chokri100% (1)
- Modèle MarchéDocument7 pagesModèle MarchéAbdelouahed MettarPas encore d'évaluation
- La Diversificationdu risqueMEDAF Modèles APT Et de Fama Et FrenchDocument22 pagesLa Diversificationdu risqueMEDAF Modèles APT Et de Fama Et FrenchElycheikh MogueyaPas encore d'évaluation
- ExamDocument3 pagesExamNajlaa LasfrPas encore d'évaluation
- Examen Gestion Financière II 3 Janvier 2012Document3 pagesExamen Gestion Financière II 3 Janvier 2012Rita FarahPas encore d'évaluation
- Cfa 420 - CapmDocument12 pagesCfa 420 - CapmKhaoulaKfouryPas encore d'évaluation
- Examen The. Fin. M. Roth 21 22Document10 pagesExamen The. Fin. M. Roth 21 22Hanane EssadikPas encore d'évaluation
- EXOS Gestion de PortefeuilleDocument11 pagesEXOS Gestion de PortefeuilleAFAF EL RHIOUANEPas encore d'évaluation
- TD3 2022-2023Document9 pagesTD3 2022-2023Mahamadou CoulibalyPas encore d'évaluation
- Cours M1 Finance 2015-2016 (10) Séance Du 4 Décembre 2015 Coût Moyen Pondéré Du CapitalDocument6 pagesCours M1 Finance 2015-2016 (10) Séance Du 4 Décembre 2015 Coût Moyen Pondéré Du CapitalIslam El OusroutiPas encore d'évaluation
- TD Finance de Marché - 2022Document6 pagesTD Finance de Marché - 2022Gaston GNIDEHOUPas encore d'évaluation
- Exos D'application TMFDocument3 pagesExos D'application TMFSINI DELIPas encore d'évaluation
- 2 - CapmDocument39 pages2 - CapmMrizig Aicha100% (1)
- Gestion de Portefeuille - TD - 3Document4 pagesGestion de Portefeuille - TD - 3ABDESSAMAD100% (1)
- chp6 - Analyse Fondamentale Et Analyse TechniqueDocument24 pageschp6 - Analyse Fondamentale Et Analyse Technique11 FATIPas encore d'évaluation
- Modèle MEDAFDocument4 pagesModèle MEDAFPPTPas encore d'évaluation
- Théorie Moderne Du PortefeuilleDocument28 pagesThéorie Moderne Du PortefeuilleAssouma Girla100% (2)
- Exposé FinanceDocument6 pagesExposé Financeتوبة نصووحةPas encore d'évaluation
- I-La Présentation Du MEDAFDocument19 pagesI-La Présentation Du MEDAFkaidi chaimaaPas encore d'évaluation
- Chapitre 6Document8 pagesChapitre 6Bahija BahijaPas encore d'évaluation
- BOURI Résumé Ch3. FMDocument1 pageBOURI Résumé Ch3. FMFiras Ben YahmedPas encore d'évaluation
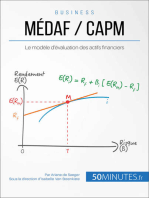
- MÉDAF / CAPM: Le modèle d'évaluation des actifs financiersD'EverandMÉDAF / CAPM: Le modèle d'évaluation des actifs financiersÉvaluation : 5 sur 5 étoiles5/5 (1)
- Titres et bourse – Tome 2: Marchés - Transactions - PlacementsD'EverandTitres et bourse – Tome 2: Marchés - Transactions - PlacementsPas encore d'évaluation
- Apprendre à traduire les textes économiques de l’anglais au françaisD'EverandApprendre à traduire les textes économiques de l’anglais au françaisPas encore d'évaluation
- Investir dans le pétrole et le gaz naturel via les ETCD'EverandInvestir dans le pétrole et le gaz naturel via les ETCPas encore d'évaluation
- Chapitre 17 Les Soldes Intermediaires deDocument13 pagesChapitre 17 Les Soldes Intermediaires deyannickPas encore d'évaluation
- Trading Débutant - Guide Complet Pour DébuterDocument18 pagesTrading Débutant - Guide Complet Pour DébuterYounoussa NomboPas encore d'évaluation
- 1 - Lecture Du BOC - 20201224Document16 pages1 - Lecture Du BOC - 20201224David GNAGOPas encore d'évaluation
- Version Finale MémoireDocument86 pagesVersion Finale Mémoireifahela297Pas encore d'évaluation
- Corrigé Indicatif Exercice 1Document2 pagesCorrigé Indicatif Exercice 1Yassine BoughaidiPas encore d'évaluation
- 3546 Les Barrieres A L Entree Expliquent Elles Le Comportement Des Banques Dans La CemacDocument26 pages3546 Les Barrieres A L Entree Expliquent Elles Le Comportement Des Banques Dans La CemacOke mbaPas encore d'évaluation
- Corrigé Examen-Comptabilité Approndie1 2002 TunisieDocument4 pagesCorrigé Examen-Comptabilité Approndie1 2002 Tunisiemarwa1Pas encore d'évaluation
- Présentation Fatima-Zahra ABDOURAFIQDocument30 pagesPrésentation Fatima-Zahra ABDOURAFIQOmar RAMDANIPas encore d'évaluation
- Ue6 2019Document15 pagesUe6 2019SAFOUPas encore d'évaluation
- Memoire v2010Document96 pagesMemoire v2010pipou pipouPas encore d'évaluation
- Evaluation Des Entreprises - Approche PatrimonialeDocument7 pagesEvaluation Des Entreprises - Approche Patrimonialeghorbelfatma12100% (1)
- Cas-Saverglass Corrigé PDFDocument4 pagesCas-Saverglass Corrigé PDFlau jeromePas encore d'évaluation
- ContentDocument6 pagesContentEFFAPas encore d'évaluation
- T.D Fiscalite Des EntitesDocument4 pagesT.D Fiscalite Des EntitesPagui OrnellePas encore d'évaluation
- Gestion ObligataireDocument31 pagesGestion Obligataireproximastar100% (1)
- Chap 2 Comptabilité de Constitution de La SociétéDocument5 pagesChap 2 Comptabilité de Constitution de La SociétébompolongaeliePas encore d'évaluation
- CM Comptabilité Opérations D'inventaireDocument29 pagesCM Comptabilité Opérations D'inventaireAnge AsbPas encore d'évaluation
- TD 1 A FaireDocument7 pagesTD 1 A Fairen a d i rPas encore d'évaluation
- Analyse Financière B3 ALTDocument22 pagesAnalyse Financière B3 ALTabdillahiabdPas encore d'évaluation
- Cours s5 Gestion FinancièreDocument24 pagesCours s5 Gestion FinancièreTaha Can100% (5)
- TD 3 Cession Et Mise en Rebut Des Immob AmrtDocument2 pagesTD 3 Cession Et Mise en Rebut Des Immob AmrtNisrine SalihPas encore d'évaluation
- Gestion Et Politique FinanciereDocument32 pagesGestion Et Politique FinanciereCheikh NgomPas encore d'évaluation
- Examen Principal 2014 - M1-Evaluation & Fusions (Enoncé Et Corrigé)Document8 pagesExamen Principal 2014 - M1-Evaluation & Fusions (Enoncé Et Corrigé)kais kaPas encore d'évaluation
- La Bourse Pour Les Nuls V2Document20 pagesLa Bourse Pour Les Nuls V2Hichem Bennia100% (1)
- Support Du Cours de Consolidation Master CCADocument72 pagesSupport Du Cours de Consolidation Master CCAMaryem rh100% (3)
- RG Cadre de Surveillance A Lintention Des Conseils DadministrationDocument212 pagesRG Cadre de Surveillance A Lintention Des Conseils Dadministrationaldrige abagaPas encore d'évaluation
- GF EX1 Correction Cas Bookonline1Document3 pagesGF EX1 Correction Cas Bookonline1najib abou RjeilyPas encore d'évaluation
- Lecture 2.Document28 pagesLecture 2.Gilles Kokouvi AGBENONSIPas encore d'évaluation
- m-1 2Document2 pagesm-1 2Zillur RahmanPas encore d'évaluation
- Chapter 1 General IntroductionDocument19 pagesChapter 1 General IntroductionHanae ElPas encore d'évaluation