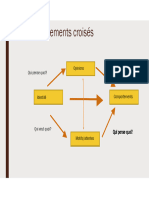
Vous aimerez peut-être aussi
- Analyser les données qualitatives en gestionD'EverandAnalyser les données qualitatives en gestionPas encore d'évaluation
- Méthodologie Quantitative Chap 3Document42 pagesMéthodologie Quantitative Chap 3Yassine Abbadi100% (2)
- Le Culte de Famille Son ImportanceDocument10 pagesLe Culte de Famille Son ImportanceN'da DjanPas encore d'évaluation
- Techniques de SondageDocument13 pagesTechniques de SondageRihabArfaoui100% (1)
- Econometrie PanelsDocument67 pagesEconometrie PanelsMØha MédPas encore d'évaluation
- 12-Méthode de Collecte Des Données Et Leur AnalyseDocument40 pages12-Méthode de Collecte Des Données Et Leur Analyseali boko100% (1)
- Credit BailDocument32 pagesCredit Bailkoigina100% (3)
- Analyse Des Données - Master - Cours - DR TchieuzingDocument69 pagesAnalyse Des Données - Master - Cours - DR TchieuzingBienvenue NoahPas encore d'évaluation
- Cours D'etude de MarcheDocument83 pagesCours D'etude de MarcheKodjo Nonou100% (2)
- TP Etude Marché 2020Document22 pagesTP Etude Marché 2020WissalmastouraPas encore d'évaluation
- Les Etudes Du MarcheDocument29 pagesLes Etudes Du Marcheaicha ismailiPas encore d'évaluation
- Analyse de Donnée QuantitativeDocument7 pagesAnalyse de Donnée QuantitativeHassan NabihPas encore d'évaluation
- TP Ecolexx SQL LDDDocument3 pagesTP Ecolexx SQL LDDapi-26420184Pas encore d'évaluation
- GPF SerieDocument5 pagesGPF SerieZakaria ImoussatPas encore d'évaluation
- Guide de Rédaction PFE InfirmierDocument9 pagesGuide de Rédaction PFE Infirmierdemoscratosa100% (1)
- Stats DescriptiveDocument65 pagesStats DescriptiveIliâss MâynârdPas encore d'évaluation
- Quizz 2024 CorrigÃsDocument8 pagesQuizz 2024 CorrigÃssitrakarasolosonPas encore d'évaluation
- Essai Sur Le Bonheur Ou Réflexions Philosophiques Sur Les Biens Et Les Maux de La Vie HumaineDocument295 pagesEssai Sur Le Bonheur Ou Réflexions Philosophiques Sur Les Biens Et Les Maux de La Vie HumaineEmmanuel GleveauPas encore d'évaluation
- Sujet UF 4 M1 M2 M3 Corrigé-1Document10 pagesSujet UF 4 M1 M2 M3 Corrigé-1Anass Treyaoui100% (1)
- Enquete de Satisfaction NDocument51 pagesEnquete de Satisfaction Nevianneyh8010Pas encore d'évaluation
- Techniques Quantitatives en MarketingDocument34 pagesTechniques Quantitatives en MarketingKadidia Cisse50% (2)
- CH III:L'étude de Marché: I - DéfinitionDocument5 pagesCH III:L'étude de Marché: I - DéfinitionmmllPas encore d'évaluation
- Chapitre 1Document7 pagesChapitre 1Aziz BenyounesPas encore d'évaluation
- Corrigé Exam 2014 2015Document3 pagesCorrigé Exam 2014 2015Raiaa ElmamiPas encore d'évaluation
- Méthodologie QuantitativeDocument5 pagesMéthodologie Quantitativejlassiwajih7Pas encore d'évaluation
- WORKSHOP SPSS Et RAPPELSDocument54 pagesWORKSHOP SPSS Et RAPPELSMeziane DjaoutPas encore d'évaluation
- Technique D EnqueteDocument10 pagesTechnique D EnqueteMAHTOUTPas encore d'évaluation
- Cours Analyse de Données Au Moyen Du Logiciel SPSS-1Document59 pagesCours Analyse de Données Au Moyen Du Logiciel SPSS-1Abdoul MadjidPas encore d'évaluation
- Résumé Info de GestionDocument9 pagesRésumé Info de GestionZainab MADAPas encore d'évaluation
- Cours Etude de Marche IsmDocument21 pagesCours Etude de Marche IsmJosée RossePas encore d'évaluation
- Je Partage « Exposé Motib Final » Avec VousDocument24 pagesJe Partage « Exposé Motib Final » Avec Vousrh.rhbadrPas encore d'évaluation
- BahloulDocument4 pagesBahloulZoubida BoudraaPas encore d'évaluation
- Chapitre 3 L'étude de MarchéDocument5 pagesChapitre 3 L'étude de MarchéNoélie JourdainPas encore d'évaluation
- Chapitre I Les Données StatistiquesDocument11 pagesChapitre I Les Données StatistiquesAsma SatouriPas encore d'évaluation
- Corrigé Exam 2016 2017Document3 pagesCorrigé Exam 2016 2017Raiaa ElmamiPas encore d'évaluation
- Chapitre V - Generalite Sur Les Etudes de MarcheDocument6 pagesChapitre V - Generalite Sur Les Etudes de MarcheVictor AlajePas encore d'évaluation
- Séquence 2 Méthodes Et Instruments D'enquêtesDocument15 pagesSéquence 2 Méthodes Et Instruments D'enquêtesserignefalloumbackendiaye0911Pas encore d'évaluation
- Chapitre Iii Methodologie QuantitativeDocument38 pagesChapitre Iii Methodologie Quantitativesamih.khorchafPas encore d'évaluation
- Chapitre IntroductifDocument5 pagesChapitre IntroductifChaimae BouzaganePas encore d'évaluation
- Développement de La Relation Client Et Vente Conseil CHAPITRE 3Document19 pagesDéveloppement de La Relation Client Et Vente Conseil CHAPITRE 3ArnaudPas encore d'évaluation
- Structurelles Cours 9araaDocument48 pagesStructurelles Cours 9araanappilPas encore d'évaluation
- Support de Cours Sixième SéanceDocument48 pagesSupport de Cours Sixième Séancemoustaidilyass7Pas encore d'évaluation
- 3 - La Veille Mercatique Et Commerciale 2022Document7 pages3 - La Veille Mercatique Et Commerciale 2022m4te3oPas encore d'évaluation
- Support de Cours - Les Fondamentaux Du Marketing - Partie 3Document16 pagesSupport de Cours - Les Fondamentaux Du Marketing - Partie 3paulinemoulinPas encore d'évaluation
- Cours Des Études de Marché QuestionnaireDocument5 pagesCours Des Études de Marché QuestionnaireBouchra GhandourPas encore d'évaluation
- Chapitre 4Document16 pagesChapitre 4Wonjew Abraham AhoulouPas encore d'évaluation
- Test DévaluationDocument5 pagesTest DévaluationImen TrablesiPas encore d'évaluation
- Add CoursDocument167 pagesAdd CoursAbdelkrim ElkhabiriPas encore d'évaluation
- Les Methodes D'entretienDocument18 pagesLes Methodes D'entretienMAHTOUTPas encore d'évaluation
- 3 - Les Études de MarchéDocument44 pages3 - Les Études de MarchéImad El JaàfariPas encore d'évaluation
- Chapitre 3 MKGDocument13 pagesChapitre 3 MKGsaidi rouaPas encore d'évaluation
- Les Étude de MarchéDocument4 pagesLes Étude de MarchéMeriem ChardalPas encore d'évaluation
- QUESTION INFORMATIQUE s6Document6 pagesQUESTION INFORMATIQUE s6khadijaPas encore d'évaluation
- Fin Cours Etudes Marketing EM3Document12 pagesFin Cours Etudes Marketing EM3ness.ntoutoumePas encore d'évaluation
- Chapitre 2 - Plan D'enquêteDocument5 pagesChapitre 2 - Plan D'enquêtearmel TAMA ZE100% (1)
- Le QuestionnaireDocument5 pagesLe Questionnaireاللهم غفرانكPas encore d'évaluation
- Esi - Manuel de CoursDocument34 pagesEsi - Manuel de CoursInnocent BIAPas encore d'évaluation
- Le Questionnaire D - Enquete1Document19 pagesLe Questionnaire D - Enquete1LukubamaPas encore d'évaluation
- Étude de MarchéDocument6 pagesÉtude de MarchéLOUBNA EL GOURICHIPas encore d'évaluation
- Memoire Final Ngane AbenaDocument77 pagesMemoire Final Ngane AbenaSteve NganePas encore d'évaluation
- Les Études de Marché: L'Essentiel Du Chapitre 2 Mercator 8 ÉditionDocument2 pagesLes Études de Marché: L'Essentiel Du Chapitre 2 Mercator 8 Éditionabdelmajid en-namiPas encore d'évaluation
- 05-Enquete de SatisfactionDocument45 pages05-Enquete de SatisfactionBraham's Najih100% (1)
- Td-Elaboration Et Administration QuestionnaireDocument6 pagesTd-Elaboration Et Administration Questionnairestonyru07100% (1)
- Etude de Marchã© L2 2021 ISM 2022 Sem 1 T 4Document7 pagesEtude de Marchã© L2 2021 ISM 2022 Sem 1 T 4Anta ThiamPas encore d'évaluation
- Le Questionnaire D - EnqueteDocument19 pagesLe Questionnaire D - EnqueteMahdi BahiPas encore d'évaluation
- Cours Enquete TS2Document28 pagesCours Enquete TS2guypaterne golyPas encore d'évaluation
- QuestionnaireDocument24 pagesQuestionnairehasnaalgr1Pas encore d'évaluation
- Appliquer le modèle de Rasch: Défis et pistes de solutionD'EverandAppliquer le modèle de Rasch: Défis et pistes de solutionPas encore d'évaluation
- Economie Industrielle CompletDocument42 pagesEconomie Industrielle CompletsmatiPas encore d'évaluation
- Leçon 7 - Théorie Financiere Et Evaluation Des TitresDocument38 pagesLeçon 7 - Théorie Financiere Et Evaluation Des TitresSaraPas encore d'évaluation
- Finance de Marche Travaux Dirige CorrigeDocument10 pagesFinance de Marche Travaux Dirige CorrigesmatiPas encore d'évaluation
- manuel Re Organisation Industrielle, Chapitres Strat Et Gouvernance Boissin, O.Document42 pagesmanuel Re Organisation Industrielle, Chapitres Strat Et Gouvernance Boissin, O.smatiPas encore d'évaluation
- Economie Industrielle CompletDocument42 pagesEconomie Industrielle CompletsmatiPas encore d'évaluation
- TD3 - Les ActionsDocument3 pagesTD3 - Les ActionslalaouiPas encore d'évaluation
- Correction TD3Document5 pagesCorrection TD3smatiPas encore d'évaluation
- FDocument39 pagesFPRANAV TIWARIPas encore d'évaluation
- Cours de Gestion Financière (M1) - PDFDocument10 pagesCours de Gestion Financière (M1) - PDFsmatiPas encore d'évaluation
- Cours IIIDocument9 pagesCours IIIsmatiPas encore d'évaluation
- Cours M1 Finance 2021-2022 (5) Exercices Betas SMLDocument10 pagesCours M1 Finance 2021-2022 (5) Exercices Betas SMLsmatiPas encore d'évaluation
- Finance de Marche Travaux Dirige CorrigeDocument10 pagesFinance de Marche Travaux Dirige CorrigesmatiPas encore d'évaluation
- FDocument23 pagesFjudicaelmicheePas encore d'évaluation
- 1gestion Et Suivi de La Qualite PDFDocument57 pages1gestion Et Suivi de La Qualite PDFMiraPas encore d'évaluation
- Tables StatistiquesDocument7 pagesTables StatistiquessmatiPas encore d'évaluation
- Panel Statique PDFDocument60 pagesPanel Statique PDFWael Trabelsi100% (1)
- Economie Numerique 5Document52 pagesEconomie Numerique 5smatiPas encore d'évaluation
- Societe Scientifique DAppui A La QuantifDocument87 pagesSociete Scientifique DAppui A La Quantifnajeh lsfPas encore d'évaluation
- 1gestion Et Suivi de La Qualite PDFDocument57 pages1gestion Et Suivi de La Qualite PDFMiraPas encore d'évaluation
- Mulindabigwi 81711500 2017Document81 pagesMulindabigwi 81711500 2017Koraich AlmahdiPas encore d'évaluation
- Econometrie Des Donnees de Panel PDFDocument46 pagesEconometrie Des Donnees de Panel PDFKhaled AmriPas encore d'évaluation
- Corrigé Sujet Exam HFE 19Document2 pagesCorrigé Sujet Exam HFE 19smatiPas encore d'évaluation
- Sujet Corrigé Ratt HFE 2018Document2 pagesSujet Corrigé Ratt HFE 2018smatiPas encore d'évaluation
- Sujet Rattrapage HFE 2017Document2 pagesSujet Rattrapage HFE 2017smatiPas encore d'évaluation
- Economie Numerique 5Document52 pagesEconomie Numerique 5smatiPas encore d'évaluation
- Développement Financier Et Croissance Économique Cas de La Région MENADocument5 pagesDéveloppement Financier Et Croissance Économique Cas de La Région MENAKaneki GoulPas encore d'évaluation
- Sujet 0 UF4 M1 M2 M3Document22 pagesSujet 0 UF4 M1 M2 M3Mohamed HadefPas encore d'évaluation
- Questionnaire QuickDocument2 pagesQuestionnaire QuickRédâ AminePas encore d'évaluation
- MINPOSTEL Rapport NGUENADocument74 pagesMINPOSTEL Rapport NGUENASimonet NguenaPas encore d'évaluation
- Stereochimie Chim 201-05-06cDocument13 pagesStereochimie Chim 201-05-06cToumany FofanaPas encore d'évaluation
- Present Simple RappelDocument8 pagesPresent Simple RappelYousra BadPas encore d'évaluation
- TP - Ms ProjectDocument3 pagesTP - Ms ProjectArthur OuattaraPas encore d'évaluation
- Double Distributivite 2 CorrigeDocument3 pagesDouble Distributivite 2 CorrigeKantryPas encore d'évaluation
- Dossier de CandidatureDocument3 pagesDossier de CandidatureWá LîdPas encore d'évaluation
- TD1 HTML PDFDocument3 pagesTD1 HTML PDFAbdo ElmamounPas encore d'évaluation
- SMP S6 EII TDS El Amraoui Chapitre 6Document10 pagesSMP S6 EII TDS El Amraoui Chapitre 6Houssein EL GHARSPas encore d'évaluation
- Histoire Des Congregations ReligieusesDocument31 pagesHistoire Des Congregations ReligieusesMarc Bozzo BatallaPas encore d'évaluation
- 001 TXT Deriv 2022Document10 pages001 TXT Deriv 2022Mat GrallPas encore d'évaluation
- French Polishing MethodeDocument35 pagesFrench Polishing MethodeJobePas encore d'évaluation
- Aon and AoaDocument18 pagesAon and AoaAhmed FrejPas encore d'évaluation
- BossuetDocument21 pagesBossuetLISBONNEPas encore d'évaluation
- Filières OffertesDocument162 pagesFilières OffertesMidou sebPas encore d'évaluation
- Gestion Budgetaire DevoirDocument5 pagesGestion Budgetaire DevoirVictoire OnanenaPas encore d'évaluation
- Cours Droit Penal Du Travail Cadre SynthetiqueDocument41 pagesCours Droit Penal Du Travail Cadre SynthetiqueAragsan HousseinPas encore d'évaluation
- RhamnaDocument168 pagesRhamnalabofor sarlPas encore d'évaluation
- LA GénéralDocument56 pagesLA Généralfotso kamgaPas encore d'évaluation
- 1moiscrosstrain PhilDocument31 pages1moiscrosstrain PhilNikoPas encore d'évaluation
- Axlou Toth Pour L'innovation: Cours de Renforcement Ou À Domicile Maths-PC-SVT: 78.192.84.64-78.151.34.44Document3 pagesAxlou Toth Pour L'innovation: Cours de Renforcement Ou À Domicile Maths-PC-SVT: 78.192.84.64-78.151.34.44yayaPas encore d'évaluation
- SimulationDocument5 pagesSimulationHoussem Eddine MereghniPas encore d'évaluation
- Describtion Technologique Des Fours4Document8 pagesDescribtion Technologique Des Fours4salah meGuenniPas encore d'évaluation
- 2013ADODocument42 pages2013ADOZikasELPas encore d'évaluation
- Cours Libertes PubliquesDocument47 pagesCours Libertes PubliquesAziz BenPas encore d'évaluation